Kubernetes学习(一)之认识Kubernetes
Kubernetes概念
简介
Kubernetes是一个跨主机集群的 开源的容器调度平台,它可以自动化应用容器的部署、扩展和操作 , 提供以容器为中心的基础架构。结合docker可以提供持续开发,持续部署的功能,我现在所从事开发的Choerodon就是基于这一套架构开发的企业级数字服务平台,具有敏捷化的应用交付和自动化的运营管理的特点。这里介绍的版本是v1.13

新的方式是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚机轻量、更“透明”,这更便于监控和管理。
组件

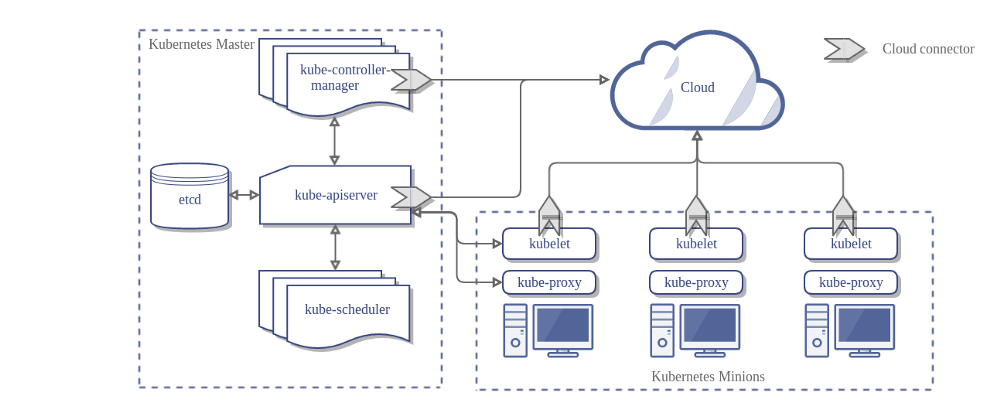
Master组件
Kubernetes 主要由以下几个核心(Master)组件组成,Master组件提供集群的管理控制中心。Master组件可以在集群中任何节点上运行。但是为了简单起见,通常在一台VM/机器上启动所有Master组件,并且不会在此VM/机器上运行用户容器。请参考构建高可用群集以来构建multi-master-VM。
kube-apiserver
etcd
etcd是Kubernetes提供默认的存储系统,保存所有集群数据,使用时需要为etcd数据提供备份计划。
kube-scheduler
主服务器上的组件,用于监视未创建节点的新创建的pod,并选择一个节点供其运行。 调度决策所考虑的因素包括个人和集体资源需求,硬件/软件/策略约束,亲和力和反亲和性规范,数据位置,工作负载间干扰和最后期限。
kube-controller-manager
kube-controller-manager运行管理控制器,它们是集群中处理常规任务的后台线程。逻辑上,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成单个二进制文件,并在单个进程中运行。负责维护集群的状态,比如故障检测、自动扩展、滚动更新等。
这些控制器包括:
- 节点(Node)控制器。
- 副本(Replication)控制器:负责维护系统中每个副本中的pod。
- 端点(Endpoints)控制器:填充Endpoints对象(即连接Services&Pods)。
- Service Account和Token控制器:为新的Namespace 创建默认帐户访问API Token。
cloud-controller-manager
云控制器管理器负责与底层云提供商的平台交互。云控制器管理器是Kubernetes版本1.6中引入的,目前还是Alpha的功能。
云控制器管理器仅运行云提供商特定的(controller loops)控制器循环。可以通过将--cloud-provider flag设置为external启动kube-controller-manager ,来禁用控制器循环。
cloud-controller-manager 具体功能:
- 节点(Node)控制器
- 路由(Route)控制器
- Service控制器
- 卷(Volume)控制器
节点(Node)组件
节点组件运行在Node,提供Kubernetes运行时环境,以及维护Pod。
kubelet
kubelet是主要的节点代理,它会监视已分配给节点的pod,负责维护容器的生命周期,同时也负责 Volume(CVI)和网络(CNI)的管理,具体功能:
- 安装Pod所需的volume。
- 下载Pod的Secrets。
- Pod中运行的 docker(或experimentally,rkt)容器。
- 定期执行容器健康检查。
- 通过在必要时创建镜像pod,将pod状态报告回系统的其余部分。
- 将节点的状态返回到系统的其余部分。
kube-proxy
kube-proxy通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。负责为 Service 提供 cluster 内部的服务发现和负载均衡。
Container Runtime
容器运行时是负责运行容器的软件。 Kubernetes支持多种运行时:Docker,rkt,runc和任何OCI运行时规范实现。
插件
插件(addon)是实现集群pod和Services功能的 。PodDeployments,ReplicationController等进行管理。Namespace 插件对象是在kube-system Namespace中创建。有关可用插件的扩展列表,请参阅插件。
DNS
虽然不严格要求使用插件,但Kubernetes集群都应该具有DNS集群。
群集 DNS是一个DNS服务器,能够为 Kubernetes services提供 DNS记录。
由Kubernetes启动的容器自动将这个DNS服务器包含在他们的DNS searches中。
用户界面
仪表板是Kubernetes集群的基于Web的通用UI。它允许用户管理和解决群集中运行的应用程序以及群集本身。
容器资源监测
容器资源监控提供一个UI浏览监控数据。
Cluster-level Logging
Cluster-level logging,负责保存容器日志,搜索/查看日志。
supervisord
supervisord是一个轻量级的监控系统,用于保障kubelet和docker运行。
fluentd
fluentd是一个守护进程,可提供cluster-level logging。
The Kubernetes API
API约定文档中描述了总体API约定
API参考中描述了API端点,资源类型和示例。
Controlling API Access文档中讨论了对API的远程访问。
Kubernetes API还可用作系统声明性配置架构的基础。 kubectl命令行工具可用于创建,更新,删除和获取API对象。
Kubernetes还根据API资源存储其序列化状态(当前在etcd中)。
Kubernetes本身被分解为多个组件,通过其API进行交互。
- API更改
- OpenAPI和Swagger定义
- API版本控制
- API组
- 启用API组
- 启用组中的资源
API更改
根据我们的经验,任何成功的系统都需要随着新用例的出现或现有用例的变化而增长和变化。因此,我们希望Kubernetes API能够不断变化和发展。但是,我们打算在很长一段时间内不破坏与现有客户端的兼容性。通常,可以预期频繁添加新的API资源和新的资源字段。消除资源或字段将需要遵循API弃用策略。
OpenAPI和Swagger定义
使用OpenAPI记录完整的API详细信息。 从Kubernetes 1.10开始,Kubernetes API服务器通过/openapi/ v2端点提供OpenAPI规范。通过设置HTTP标头指定请求的格式:
| Header | Possible Values |
|---|---|
| Accept | application/json, application/com.github.proto-openapi.spec.v2@v1.0+protobuf (the default content-type is application/json for / or not passing this header) |
| Accept-Encoding | gzip (not passing this header is acceptable) |
在1.14之前,格式分离的端点(/swagger.json,/swagger-2.0.0.json,/swagger-2.0.0.pb-v1,/swagger-2.0.0.pb-v1.gz)为OpenAPI提供服务不同格式的规范。这些端点已弃用,将在Kubernetes 1.14中删除。
获取OpenAPI规范的示例:
| Before 1.10 | Starting with Kubernetes 1.10 |
|---|---|
| GET /swagger.json | GET /openapi/v2 Accept: application/json |
| GET /swagger-2.0.0.pb-v1 | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf |
| GET /swagger-2.0.0.pb-v1.gz | GET /openapi/v2 Accept: application/com.github.proto-openapi.spec.v2@v1.0+protobuf Accept-Encoding: gzip |
Kubernetes为API实现了另一种基于Protobuf的序列化格式,主要用于集群内通信,在设计提案中有记录,每个模式的IDL文件都位于定义API对象的Go包中。
在1.14之前,Kubernetes apiserver还公开了一个API,可用于检索/ swaggerapi上的Swagger v1.2 Kubernetes API规范。该端点已弃用,将在Kubernetes 1.14中删除。
API版本控制
为了更容易消除字段或重构资源表示,Kubernetes支持多个API版本,每个API版本位于不同的API路径,例如/api/v1或/apis/extensions/v1beta1。
我们选择在API级别而不是在资源或字段级别进行版本化,以确保API提供清晰,一致的系统资源和行为视图,并允许控制对生命末端和/或实验API的访问。 JSON和Protobuf序列化模式遵循相同的模式更改指南 - 以下所有描述都涵盖两种格式。
请注意,API版本控制和软件版本控制仅间接相关。 API和发布版本控制提议描述了API版本控制和软件版本控制之间的关系。
不同的API版本意味着不同级别的稳定性和支持。 API更改文档中更详细地描述了每个级别的标准。他们总结在这里:
Alpha level:
- 版本名称包含alpha(例如v1alpha1)。
- 可能是马车。启用该功能可能会暴露错误。默认情况下禁用。
- 可随时删除对功能的支持,恕不另行通知。
- API可能会在以后的软件版本中以不兼容的方式更改,恕不另行通知。
- 由于错误风险增加和缺乏长期支持,建议仅在短期测试集群中使用。
Beta level::
- 版本名称包含beta(例如v2beta3)。
- 代码经过了充分测试。启用该功能被认为是安全的。默认情况下启用。
- 虽然细节可能会有所变化,但不会删除对整体功能的支持。
- 在随后的beta版或稳定版中,对象的模式和/或语义可能以不兼容的方式发生变化。发生这种情况时,我们将提供迁移到下一版本的说明。这可能需要删除,编辑和重新创建API对象。编辑过程可能需要一些思考。对于依赖该功能的应用程序,这可能需要停机时间。
- 建议仅用于非关键业务用途,因为后续版本中可能存在不兼容的更改。如果您有多个可以独立升级的群集,您可以放宽此限制。
- 请尝试我们的测试版功能并提供反馈!一旦他们退出测试版,我们可能无法进行更多更改。
Stable level:
- 该版本名称是vX这里X是一个整数。
- 许多后续版本的已发布软件中将出现稳定版本的功能。
API组
为了更容易扩展Kubernetes API,我们实现了API组。API组在REST路径和apiVersion序列化对象的字段中指定。
目前有几个API组正在使用中:
- 核心组,常常被称为遗留组,是在REST路径
/api/v1和用途apiVersion: v1。 - 命名组处于REST路径
/apis/$GROUP_NAME/$VERSION,并使用apiVersion: $GROUP_NAME/$VERSION(例如apiVersion: batch/v1)。在Kubernetes API参考中可以看到支持的API组的完整列表。
使用自定义资源扩展API有两种受支持的路径:
- CustomResourceDefinition 适用于具有非常基本CRUD需求的用户。
- 需要完整Kubernetes API语义的用户可以实现自己的apiserver并使用聚合器 使其无缝地为客户端。
启用API组
默认情况下启用某些资源和API组。可以通过设置--runtime-config apiserver 来启用或禁用它们。--runtime-config接受逗号分隔值。例如:要禁用批处理/ v1,请设置 --runtime-config=batch/v1=false,以启用批处理/ v2alpha1,设置--runtime-config=batch/v2alpha1。该标志接受逗号分隔的一组key = value对,描述了apiserver的运行时配置。
重要信息:启用或禁用组或资源需要重新启动apiserver和controller-manager以获取--runtime-config更改。
启用组中的资源
默认情况下启用DaemonSet,Deployments,HorizontalPodAutoscalers,Ingresses,Jobs和ReplicaSet。可以通过设置--runtime-configapiserver 来启用其他扩展资源。--runtime-config接受逗号分隔值。例如:要禁用部署和入口,请设置 --runtime-config=extensions/v1beta1/deployments=false,extensions/v1beta1/ingresses=false
与Kubernetes对象一起工作
了解Kubernetes对象
了解Kubernetes对象
Kubernetes对象是Kubernetes系统中的持久实体。Kubernetes使用这些实体来表示集群的状态。具体来说,他们可以描述:
- 容器化应用正在运行(以及在哪些节点上)
- 这些应用可用的资源
- 关于这些应用如何运行的策略,如重新策略,升级和容错
Kubernetes对象是“record of intent”,一旦创建了对象,Kubernetes系统会确保对象存在。通过创建对象,可以有效地告诉Kubernetes系统你希望集群的工作负载是什么样的。
要使用Kubernetes对象(无论是创建,修改还是删除),都需要使用Kubernetes API。例如,当使用kubectl命令管理工具时,CLI会为提供Kubernetes API调用。你也可以直接在自己的程序中使用Kubernetes API,您还可以使用其中一个客户端库在您自己的程序中直接使用Kubernetes API。
对象(Object)规范和状态
每个Kubernetes对象都包含两个嵌套对象字段,用于管理Object的配置:Object Spec和Object Status。Spec描述了对象所需的状态 - 希望Object具有的特性,Status描述了对象的实际状态,并由Kubernetes系统提供和更新。
例如,通过Kubernetes Deployment 来表示在集群上运行的应用的对象。创建Deployment时,可以设置Deployment Spec,来指定要运行应用的三个副本。Kubernetes系统将读取Deployment Spec,并启动你想要的三个应用实例 - 来更新状态以符合之前设置的Spec。如果这些实例中有任何一个失败(状态更改),Kuberentes系统将响应Spec和当前状态之间差异来调整,这种情况下,将会开始替代实例。
有关object spec、status和metadata更多信息,请参考“Kubernetes API Conventions”。
描述Kubernetes对象
在Kubernetes中创建对象时,必须提供描述其所需Status的对象Spec,以及关于对象(如name)的一些基本信息。当使用Kubernetes API创建对象(直接或通过kubectl)时,该API请求必须将该信息作为JSON包含在请求body中。通常,可以将信息提供给kubectl .yaml文件,在进行API请求时,kubectl将信息转换为JSON。
以下示例是一个.yaml文件,显示Kubernetes Deployment所需的字段和对象Spec:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#application/deployment.yaml
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用上述.yaml文件创建Deployment,是通过在kubectl中使用kubectl create命令来实现。将该.yaml文件作为参数传递。如下例子:1
2$ kubectl create -f https://k8s.io/examples/application/deployment.yaml --record
deployment.apps/nginx-deployment created
必填字段
对于要创建的Kubernetes对象的yaml文件,需要为以下字段设置值:
- apiVersion - 创建对象的Kubernetes API 版本
- kind - 要创建什么样的对象?
- metadata- 具有唯一标示对象的数据,包括 name(字符串)、UID和Namespace(可选项)
您还需要提供对象规范字段。对象规范的精确格式对于每个Kubernetes对象都是不同的,并且包含特定于该对象的嵌套字段。 Kubernetes API Reference可以帮助您找到可以使用Kubernetes创建的所有对象的规范格式。例如,可以在此处找到Pod对象的spec格式,可以在此处找到Deployment对象的spec格式。
name
Kubernetes REST API中的所有对象都由Name和UID明确标识。
对于非唯一的用户提供的属性,Kubernetes提供标签和注释。
有关名称和UID的精确语法规则,请参阅标识符设计文档。
- Names
- UIDs
Names
客户端提供的字符串,用于引用资源URL中的对象,例如/api/v1/pods/some-name。
只有给定类型的一个对象一次可以有一个给定的名称。但是,如果删除该对象,则可以创建具有相同名称的新对象。
按照惯例,Kubernetes资源的名称应最多为253个字符,并且由小写字母数字字符组成-,并且.,但某些资源具有更具体的限制。
UIDs
Kubernetes系统生成的字符串,用于唯一标识对象。
在Kubernetes集群的整个生命周期中创建的每个对象都具有不同的UID。它旨在区分类似实体的历史事件。
Namespaces
Kubernetes支持由同一物理集群支持的多个虚拟集群。这些虚拟集群称为名称空间。
- 何时使用多个命名空间
- 使用命名空间
- 命名空间和DNS
- 并非所有对象都在命名空间中
何时使用多个命名空间
命名空间旨在用于多个用户分布在多个团队或项目中的环境中。对于具有几个到几十个用户的集群,您根本不需要创建或考虑名称空间。当您需要它们提供的功能时,请开始使用命名空间。
命名空间提供名称范围。资源名称在名称空间中必须是唯一的,而不是跨名称空间。
命名空间是一种在多个用户之间划分群集资源的方法(通过资源配额)。
在Kubernetes的未来版本中,默认情况下,同一名称空间中的对象将具有相同的访问控制策略。
没有必要使用多个名称空间来分隔略有不同的资源,例如同一软件的不同版本:使用标签来区分同一名称空间中的资源。
使用命名空间
名称空间的管理指南文档中描述了名称空间的创建和删除。
查看名称空间
您可以使用以下命令列出集群中的当前名称空间:1
2
3
4
5$ kubectl get namespaces
NAME STATUS AGE
default Active 1d
kube-system Active 1d
kube-public Active 1d
Kubernetes以三个初始名称空间开头:
default没有其他命名空间的对象的默认命名空间kube-systemKubernetes系统创建的对象的命名空间kube-public此命名空间是自动创建的,并且所有用户(包括未经过身份验证的用户)都可以读取。此命名空间主要用于群集使用,以防某些资源在整个群集中可见且可公开读取。此命名空间的公共方面只是一个约定,而不是一个要求。
设置请求的命名空间
要临时设置请求的命名空间,请使用该--namespace标志。
例如:1
2$ kubectl --namespace=<insert-namespace-name-here> run nginx --image=nginx
$ kubectl --namespace=<insert-namespace-name-here> get pods
设置命名空间首选项
您可以在该上下文中为所有后续kubectl命令永久保存命名空间。
1 | $ kubectl config set-context $(kubectl config current-context) --namespace=<insert-namespace-name-here> |
命名空间和DNS
创建服务时,它会创建相应的DNS条目。此条目是表单<service-name>.<namespace-name>.svc.cluster.local,这意味着如果容器只是使用<service-name>,它将解析为命名空间本地的服务。这对于在多个名称空间(如开发,分段和生产)中使用相同的配置非常有用。如果要跨命名空间访问,则需要使用完全限定的域名(FQDN)。
并非所有对象都在命名空间中
大多数Kubernetes资源(例如pod,服务,复制控制器等)都在某些名称空间中。但是,命名空间资源本身并不在命名空间中。并且低级资源(例如节点和persistentVolumes)不在任何名称空间中。
要查看哪些Kubernetes资源在命名空间中,哪些不在:1
2
3
4
5 In a namespace
kubectl api-resources --namespaced=true
Not in a namespace
kubectl api-resources --namespaced=false
Labels and Selectors
标签是附加到对象(例如pod)的键/值对。标签旨在用于指定对用户有意义且相关的对象的标识属性,但不直接暗示核心系统的语义。标签可用于组织和选择对象的子集。标签可以在创建时附加到对象,随后可以随时添加和修改。每个对象都可以定义一组键/值标签。每个Key对于给定对象必须是唯一的。1
2
3
4
5
6"metadata": {
"labels": {
"key1" : "value1",
"key2" : "value2"
}
}
标签允许高效的查询和监视,非常适合在UI和CLI中使用。应使用注释记录非识别信息。
- 动机
- 语法和字符集
- 标签选择器
- API
动机
标签使用户能够以松散耦合的方式将他们自己的组织结构映射到系统对象,而无需客户端存储这些映射。
服务部署和批处理流水线通常是多维实体(例如,多个分区或部署,多个释放轨道,多个层,每层多个微服务)。管理通常需要交叉操作,这打破了严格的层次表示的封装,特别是由基础设施而不是用户确定的严格的层次结构。
示例标签:
"release" : "stable","release" : "canary""environment" : "dev","environment" : "qa","environment" : "production""tier" : "frontend","tier" : "backend","tier" : "cache""partition" : "customerA","partition" : "customerB""track" : "daily","track" : "weekly"
这些只是常用标签的例子; 你可以自由地制定自己的约定。请记住,标签Key对于给定对象必须是唯一的。
语法和字符集
标签是键/值对。有效标签键有两个段:可选前缀和名称,用斜杠(/)分隔。名称段是必需的,必须是63个字符或更少,以字母数字字符([a-z0-9A-Z])开头和结尾,带有破折号(-),下划线(_),点(.)和字母数字之间。前缀是可选的。如果指定,前缀必须是DNS子域:由点(.)分隔的一系列DNS标签,总共不超过253个字符,后跟斜杠(/)。
如果省略前缀,则假定标签Key对用户是私有的。自动化系统组件(例如kube-scheduler,kube-controller-manager,kube-apiserver,kubectl,或其他第三方自动化),它添加标签终端用户对象都必须指定一个前缀。
在kubernetes.io/和k8s.io/前缀保留给Kubernetes核心组件。
有效标签值必须为63个字符或更少,并且必须为空或以字母数字字符([a-z0-9A-Z])开头和结尾,并带有短划线(-),下划线(_),点(.)和字母数字。
标签选择器
与名称和UID不同,标签不提供唯一性。通常,我们希望许多对象携带相同的标签。
通过标签选择器,客户端/用户可以识别一组对象。标签选择器是Kubernetes中的核心分组原语。
目前,API支持两种类型的选择:基于平等,和基于集的。标签选择器可以由逗号分隔的多个要求组成。在多个要求的情况下,必须满足所有要求,因此逗号分隔符充当逻辑AND(&&)运算符。
空或非指定选择器的语义取决于上下文,使用选择器的API类型应记录它们的有效性和含义。
注意:对于某些API类型(例如ReplicaSet),两个实例的标签选择器不得在命名空间内重叠,或者控制器可以将其视为冲突的指令,并且无法确定应存在多少副本。
基于平等的要求
基于平等或不平等的要求允许按标签键和值进行过滤。匹配对象必须满足所有指定的标签约束,尽管它们也可能有其他标签。三种操作都承认=,==,!=。前两个代表平等(简单地说是同义词),而后者代表不平等。例如:1
2environment = production
tier != frontend
前者选择密钥等于environment和值等于的所有资源production。后者选择密钥等于tier和值不同的frontend所有资源,以及没有带tier密钥标签的所有资源。可以过滤使用逗号运算符production排除的资源frontend:environment=production,tier!=frontend
基于等同的标签要求的一种使用场景是Pods指定节点选择标准。例如,下面的示例Pod选择标签为“ accelerator=nvidia-tesla-p100”的节点。1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: Pod
metadata:
name: cuda-test
spec:
containers:
- name: cuda-test
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
accelerator: nvidia-tesla-p100
基于集合的要求
基于集合的标签要求允许根据一组值过滤密钥。三种操作的支持:in,notin和exists(仅密钥标识符)。例如:1
2
3
4environment in (production, qa)
tier notin (frontend, backend)
partition
!partition
第一个示例选择键等于environment和值等于production或的所有资源qa。第二个示例选择密钥等于tier和除了frontend和之外的值的backend所有资源,以及没有带tier密钥标签的所有资源。第三个例子选择所有资源,包括带密钥的标签partition; 没有检查值。第四个示例选择没有带键的标签的所有资源partition; 没有检查值。类似地,逗号分隔符充当AND运算符。因此,使用partition密钥(无论值)和environment不同的 过滤资源qa都可以实现partition,environment notin (qa)。基于集合标签选择器是一种平等的一般形式,因为environment=production它等同于environment in (production); 同样的!=和notin。
基于集合的需求可以与基于相等的需求相结合。例如:partition in (customerA, customerB),environment!=qa。
API
LIST和WATCH过滤
LIST和WATCH操作可以指定标签选择器来过滤使用查询参数返回的对象集。这两个要求都是允许的(在此处显示为出现在URL查询字符串中):
- 基于平等的要求:
?labelSelector=environment%3Dproduction,tier%3Dfrontend - 基于集合的要求:
?labelSelector=environment+in+%28production%2Cqa%29%2Ctier+in+%28frontend%29
两种标签选择器样式都可用于通过REST客户端列出或查看资源。例如,靶向apiserver与kubectl和使用基于平等-一个可写:1
$ kubectl get pods -l environment=production,tier=frontend
或使用基于集合的要求:1
$ kubectl get pods -l 'environment in (production),tier in (frontend)'
如前所述,基于集合的要求更具表现力。例如,他们可以在值上实现OR运算符:1
kubectl get pods -l 'environment in (production, qa)'
或限制负匹配通过存在操作者:1
kubectl get pods -l 'environment,environment notin (frontend)'
在API对象中设置引用
某些Kubernetes对象(例如services和replicationcontrollers)也使用标签选择器来指定其他资源集,例如pod。
服务和ReplicationController
service使用标签选择器定义目标的一组pod 。类似地,replicationcontroller应该管理的pod的数量也用标签选择器定义。
两个对象的标签选择器在使用映射定义json或yaml文件中定义,并且仅支持基于等同的需求选择器:1
2
3"selector": {
"component" : "redis",
}
要么1
2selector:
component: redis
这个选择器(分别以json或yaml格式)相当于component=redis或component in (redis)。
支持基于集合的需求的资源
较新的资源,如Job,Deployment,Replica Set,和Daemon Set,支持基于集合的要求也是如此。1
2
3
4
5
6selector:
matchLabels:
component: redis
matchExpressions:
- {key: tier, operator: In, values: [cache]}
- {key: environment, operator: NotIn, values: [dev]}
matchLabels是对的地图{key,value}。一个单一的{key,value}在matchLabels地图相当于一个元件matchExpressions,其key字段是“key”,则operator是“In”和values阵列仅包含“value”。matchExpressions是一个pod选择器要求列表。有效的运算符包括In,NotIn,Exists和DoesNotExist。在In和NotIn的情况下,设置的值必须是非空的。所有的要求,从两者matchLabels和matchExpressionsAND一起 - 他们必须满足,以匹配。
选择节点集
用于选择标签的一个用例是约束pod可以调度的节点集。有关更多信息,请参阅有关节点选择的文档。
Annotations
您可以使用Kubernetes注释将任意非标识元数据附加到对象。工具和库等客户端可以检索此元数据。
- 将元数据附加到对象
- 语法和字符集
将元数据附加到对象
您可以使用标签或注释将元数据附加到Kubernetes对象。标签可用于选择对象和查找满足特定条件的对象集合。相反,注释不用于识别和选择对象。注释中的元数据可以是小的或大的,结构化的或非结构化的,并且可以包括标签不允许的字符。
注释(如标签)是键/值映射1
2
3
4
5
6"metadata": {
"annotations": {
"key1" : "value1",
"key2" : "value2"
}
}
以下是可以在注释中记录的一些信息示例:
- 由声明性配置层管理的字段。将这些字段作为注释附加,可以将它们与客户端或服务器设置的默认值以及自动生成的字段和自动调整大小或自动调整系统设置的字段区分开来。
- 构建,发布或映像信息,如时间戳,版本ID,git分支,PR编号,镜像哈希和仓库地址。
- 指向日志记录,监视,分析或审计存储库的指针。
- 可用于调试目的的客户端库或工具信息:例如,名称,版本和构建信息。
- 用户或工具/系统出处信息,例如来自其他生态系统组件的相关对象的URL。
- 轻量推出工具元数据:例如,配置或检查点。
- 负责人的电话或寻呼机号码,或指定可在何处找到该信息的目录条目,例如团队网站。
- 从最终用户到实现的指令,用于修改行为或使用非标准功能。
您可以将此类信息存储在外部数据库或目录中,而不是使用注释,但这会使生成用于部署,管理,内省等的共享客户端库和工具变得更加困难。
语法和字符集
注释是键/值对。有效的注释键有两个段:可选的前缀和名称,用斜杠(/)分隔。名称段是必需的,必须是63个字符或更少,以字母数字字符([a-z0-9A-Z])开头和结尾,带有破折号(-),下划线(_),点(.)和字母数字之间。前缀是可选的。如果指定,前缀必须是DNS子域:由点(.)分隔的一系列DNS标签,总共不超过253个字符,后跟斜杠(/)。
如果省略前缀,则假定注释密钥对用户是私有的。自动化系统组件(例如kube-scheduler,kube-controller-manager,kube-apiserver,kubectl,或其他第三方自动化)的添加注释到最终用户的对象都必须指定一个前缀。
在kubernetes.io/和k8s.io/前缀保留给Kubernetes核心组件。
Field Selectors
- 支持的字段
- 支持操作
- 链式选择器
- 多种资源类型
字段选择器允许您根据一个或多个资源字段的值选择Kubernetes资源。以下是一些示例字段选择器查询:
metadata.name=my-servicemetadata.namespace!=defaultstatus.phase=Pending
此kubectl命令选择status.phase字段值为的所有Pod Running:1
$ kubectl get pods --field-selector status.phase=Running
注意:
字段选择器本质上是资源过滤器。默认情况下,不应用选择器/过滤器,这意味着将选择指定类型的所有资源。这使以下kubectl查询等效:
2
$ kubectl pods ---selector ""
支持的字段
支持的字段选择器因Kubernetes资源类型而异。所有资源类型都支持metadata.name和metadata.namespace字段。使用不受支持的字段选择器会产生错误。例如:1
2$ kubectl get ingress --field-selector foo.bar=baz
Error from server (BadRequest): Unable to find "ingresses" that match label selector "", field selector "foo.bar=baz": "foo.bar" is not a known field selector: only "metadata.name", "metadata.namespace"
支持操作
您可以使用=,==以及!=与现场选择操作(=和==意思是一样的)。kubectl例如,此命令选择不在default命名空间中的所有Kubernetes服务:1
$ kubectl get services --field-selector metadata.namespace!=default
链式选择器
与标签和其他选择器一样,字段选择器可以作为逗号分隔列表链接在一起。此kubectl命令选择status.phase不相等Running且spec.restartPolicy字段等于的所有Pod Always:1
$ kubectl get pods --field-selector=status.phase!=Running,spec.restartPolicy=Always
多种资源类型
您可以跨多种资源类型使用字段选择器。此kubectl命令选择不在default命名空间中的所有Statefulsets和Services :1
$ kubectl get statefulsets,services --field-selector metadata.namespace!=default
Recommended Labels
您可以使用比kubectl和仪表板更多的工具来可视化和管理Kubernetes对象。一组通用的标签允许工具以互操作的方式工作,以所有工具都能理解的通用方式描述对象。
除支持工具外,推荐标签还以可查询的方式描述应用程序。
- 标签
- 应用程序和应用程序实例
- 例子
元数据围绕应用程序的概念进行组织。Kubernetes不是一个服务平台(PaaS),也没有或强制执行正式的应用程序概念。相反,应用程序是非正式的,并使用元数据进 应用程序包含的内容的定义是松散的。
注意:这些是推荐标签。它们使管理应用程序变得更容易,但对于任何核心工具都不是必需的。
共享标签和注释共享一个共同的前缀:app.kubernetes.io。没有前缀的标签对用户是私有的。共享前缀可确保共享标签不会干扰自定义用户标签。
标签
为了充分利用这些标签,应将它们应用于每个资源对象。
| 键 | 描述 | 例 | 类型 |
|---|---|---|---|
| app.kubernetes.io/name | 应用程序的名称 | string | mysql |
| app.kubernetes.io/instance | 标识应用程序实例的唯一名称 | string | wordpress-abcxzy |
| app.kubernetes.io/version | 应用程序的当前版本(例如,语义版本,修订版哈希等) | string | 5.7.21 |
| app.kubernetes.io/component | 架构中的组件 | string | database |
| app.kubernetes.io/part-of | 此级别的更高级别应用程序的名称 | string | wordpress |
| app.kubernetes.io/managed-by | 该工具用于管理应用程序的操作 | string | helm |
要说明这些标签的运行情况,请考虑以下StatefulSet对象:1
2
3
4
5
6
7
8
9
10apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "5.7.21"
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/managed-by: helm
应用程序和应用程序实例
应用程序可以一次或多次安装到Kubernetes集群中,在某些情况下,可以安装在同一名称空间中。例如,wordpress可以不止一次安装,其中不同的网站是wordpress的不同安装。
应用程序的名称和实例名称分别记录。例如,在WordPress具有app.kubernetes.io/name的wordpress,同时它有一个实例名,被表示为app.kubernetes.io/instance具有值 wordpress-abcxzy。这使得应用程序的应用程序和实例可以识别。应用程序的每个实例都必须具有唯一的名称。
例子
为了说明使用这些标签的不同方式,以下示例具有不同的复杂性。
一种简单的无状态服务
考虑使用Deployment和Service对象部署的简单无状态服务的情况。以下两个代码段表示如何以最简单的形式使用标签。
本Deployment是用来监督运行应用程序本身的豆荚。1
2
3
4
5
6
7apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
将Service用于公开应用程序。1
2
3
4
5
6
7apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: myservice
app.kubernetes.io/instance: myservice-abcxzy
...
使用数据库的Web应用程序
考虑一个稍微复杂的应用程序:使用Helm安装的使用数据库(MySQL)的Web应用程序(WordPress)。以下代码段说明了用于部署此应用程序的对象的开始。
以下Deployment内容用于WordPress:1
2
3
4
5
6
7
8
9
10
11apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
将Service用于公开WordPress的:1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: wordpress
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/version: "4.9.4"
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: server
app.kubernetes.io/part-of: wordpress
...
MySQL作为一个StatefulSet包含它的元数据和它所属的更大的应用程序公开:1
2
3
4
5
6
7
8
9
10
11apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/version: "5.7.21"
...
将Service用于公开MySQL作为WordPress的部分:1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: mysql
app.kubernetes.io/instance: wordpress-abcxzy
app.kubernetes.io/managed-by: helm
app.kubernetes.io/component: database
app.kubernetes.io/part-of: wordpress
app.kubernetes.io/version: "5.7.21"
...
使用MySQL StatefulSet,Service您会注意到有关MySQL和Wordpress的信息,包括更广泛的应用程序。
对象管理使用kubectl
Kubernetes对象管理
该kubectl命令行工具支持多种不同的方法来创建和管理Kubernetes对象。本文档概述了不同的方法。
- 管理技巧
- 命令式命令
- 势在必行的对象配置
- 声明性对象配置
管理技巧
警告:应仅使用一种技术管理Kubernetes对象。对同一对象的混合和匹配技术会导致未定义的行为。
| Management technique | 操作 | 推荐环境 | Supported writers | Learning curve |
|---|---|---|---|---|
| Imperative commands | Live objects | Development projects | 1+ | Lowest |
| Imperative object configuration | Individual files | Production projects | 1 | Moderate |
| Declarative object configuration | Directories of files | Production projects | 1+ | Highest |
命令式命令
使用命令性命令时,用户直接在群集中的活动对象上操作。用户将kubectl命令的操作作为参数或标志提供。
这是在集群中启动或运行一次性任务的最简单方法。由于此技术直接在活动对象上运行,因此它不提供先前配置的历史记录。
例子
通过创建Deployment对象来运行nginx容器的实例:1
kubectl run nginx --image nginx
使用不同的语法执行相同的操作:1
kubectl create deployment nginx --image nginx
权衡
与对象配置相比的优点:
- 命令简单易学,易记。
- 命令只需要一个步骤即可对集群进行更改。
与对象配置相比的缺点:
- 命令不与更改审核过程集成。
- 命令不提供与更改关联的审计跟踪。
- 除了活动之外,命令不提供记录源。
- 命令不提供用于创建新对象的模板。
势在必行的对象配置
在命令式对象配置中,kubectl命令指定操作(创建,替换等),可选标志和至少一个文件名。指定的文件必须包含YAML或JSON格式的对象的完整定义。
有关 对象定义的更多详细信息,请参阅API参考。
警告:
replace命令式命令将现有规范替换为新提供的规范,删除对配置文件中缺少的对象的所有更改。此方法不应与其配置文件独立更新的资源类型一起使用。LoadBalancer例如,类型的服务使其externalIPs字段独立于群集的配置而更新。
例子
创建配置文件中定义的对象:1
kubectl create -f nginx.yaml
删除两个配置文件中定义的对象:1
kubectl delete -f nginx.yaml -f redis.yaml
通过覆盖实时配置来更新配置文件中定义的对象:1
kubectl replace -f nginx.yaml
权衡
与命令式命令相比的优点:
- 对象配置可以存储在诸如Git的源控制系统中。
- 对象配置可以与进程集成,例如在推送和审计跟踪之前查看更改。
- 对象配置提供了用于创建新对象的模板。
与命令式命令相比的缺点:
- 对象配置需要对对象模式有基本的了解。
- 对象配置需要编写YAML文件的附加步骤。
与声明对象配置相比的优点:
- 命令式对象配置行为更简单,更易于理解。
- 从Kubernetes 1.5版开始,命令式对象配置更加成熟。
与声明对象配置相比的缺点:
- 命令对象配置最适合文件,而不是目录。
- 活动对象的更新必须反映在配置文件中,否则在下次更换时会丢失。
声明性对象配置
使用声明性对象配置时,用户对本地存储的对象配置文件进行操作,但是用户不定义要对文件执行的操作。每个对象自动检测创建,更新和删除操作kubectl。这使得能够处理目录,其中可能需要不同对象的不同操作。
注意:声明性对象配置保留其他编写者所做的更改,即使更改未合并回对象配置文件也是如此。这可以通过使用
patchAPI操作来仅写入观察到的差异,而不是使用replaceAPI操作来替换整个对象配置。
例子
处理目录中的所有对象配置文件configs,并创建或修补活动对象。您可以先diff查看要进行的更改,然后应用:
1 | kubectl diff -f configs/ |
递归处理目录:1
2kubectl diff -R -f configs/
kubectl apply -R -f configs/
权衡
与命令式对象配置相比的优点:
- 即使它们未合并回配置文件,也会保留直接对活动对象所做的更改。
- 声明性对象配置更好地支持对目录进行操作并自动检测每个对象的操作类型(创建,修补,删除)。
与命令式对象配置相比的缺点:
- 声明性对象配置更难以调试,并在意外时理解结果。
- 使用diff的部分更新会创建复杂的合并和修补操作。
使用命令式命令管理Kubernetes对象
可以使用命令kubectl行工具中内置的命令性命令直接创建,更新和删除Kubernetes对象。本文档说明了如何组织这些命令以及如何使用它们来管理实时对象。
- 权衡
- 如何创建对象
- 如何更新对象
- 如何删除对象
- 如何查看对象
- 使用set命令在创建之前修改对象
- 使用–edit修改之前创建的对象
权衡
该kubectl工具支持三种对象管理:
- 命令式命令
- 势在必行的对象配置
- 声明性对象配置
有关每种对象管理 的优缺点的讨论,请参阅Kubernetes对象管理。
如何创建对象
该kubectl工具支持动词驱动的命令,用于创建一些最常见的对象类型。这些命令被命名为不熟悉Kubernetes对象类型的用户可识别。
run:创建一个新的Deployment对象以在一个或多个Pod中运行Container。expose:创建一个新的服务对象,以跨Pod调整流量负载。autoscale:创建新的Autoscaler对象以自动水平扩展控制器,例如部署。
该kubectl工具还支持由对象类型驱动的创建命令。这些命令支持更多对象类型,并且更明确地表达了它们的意图,但要求用户知道他们打算创建的对象的类型。
create <objecttype> [<subtype>] <instancename>
某些对象类型具有您可以在create命令中指定的子类型。例如,Service对象有几个子类型,包括ClusterIP,LoadBalancer和NodePort。这是一个使用子类型NodePort创建服务的示例:1
kubectl create service nodeport <myservicename>
在前面的示例中,该create service nodeport命令称为命令的子create service命令。
您可以使用该-h标志来查找子命令支持的参数和标志:1
kubectl create service nodeport -h
如何更新对象
该kubectl命令支持一些常见更新操作的动词驱动命令。命名这些命令是为了使不熟悉Kubernetes对象的用户能够在不知道必须设置的特定字段的情况下执行更新:
scale:通过更新控制器的副本计数,水平缩放控制器以添加或删除Pod。annotate:在对象中添加或删除注释。label:在对象中添加或删除标签。
该kubectl命令还支持由对象的一个方面驱动的更新命令。设置此方面可以为不同的对象类型设置不同的字段:
- set :设置对象的一个方面。
注意:在Kubernetes 1.5版中,并非每个动词驱动的命令都有一个关联的方面驱动命令。
该kubectl工具支持这些直接更新实时对象的其他方法,但是它们需要更好地理解Kubernetes对象模式。
edit:通过在编辑器中打开其配置,直接编辑活动对象的原始配置。patch:使用补丁字符串直接修改活动对象的特定字段。有关修补程序字符串的更多详细信息,请参阅API约定中的修补程序部分 。
如何删除对象
您可以使用该delete命令从群集中删除对象:
delete <type>/<name>
注意:您可以使用
kubectl delete命令式命令和命令式对象配置。不同之处在于传递给命令的参数。要kubectl delete用作命令性命令,请将要删除的对象作为参数传递。这是一个传递名为nginx的Deployment对象的示例:
1 | kubectl delete deployment/nginx |
如何查看对象
有几个命令用于打印有关对象的信息:
get:打印有关匹配对象的基本信息。使用get -h查看选项列表。describe:打印有关匹配对象的聚合详细信息。logs:为在Pod中运行的容器打印stdout和stderr。
使用set命令在创建之前修改对象
有些对象字段没有可在create命令中使用的标志。在一些案件中,可以使用的组合 set并create指定对象创建前场的值。这是通过将create命令的输出传递给 set命令,然后返回到create命令来完成的。这是一个例子:
1 | kubectl create service clusterip my-svc --clusterip="None" -o yaml --dry-run | kubectl set selector --local -f - 'environment=qa' -o yaml | kubectl create -f - |
- 该
kubectl create service -o yaml --dry-run命令为服务创建配置,但将其作为YAML打印到stdout,而不是将其发送到Kubernetes API服务器。 - 该
kubectl set selector --local -f - -o yaml命令从stdin读取配置,并将更新的配置作为YAML写入stdout。 - 该
kubectl create -f -命令使用stdin提供的配置创建对象。
使用–edit修改之前创建的对象
您可以kubectl create --edit在创建对象之前对其进行任意更改。这是一个例子:1
2kubectl create service clusterip my-svc --clusterip="None" -o yaml --dry-run > /tmp/srv.yaml
kubectl create --edit -f /tmp/srv.yaml
该kubectl create service命令为服务创建配置并将其保存到/tmp/srv.yaml。
该kubectl create --edit命令在创建对象之前打开配置文件以进行编辑。
使用配置文件管理Kubernetes对象
可以使用kubectl 命令行工具以及使用YAML或JSON编写的对象配置文件来创建,更新和删除Kubernetes对象。本文档介绍了如何使用配置文件定义和管理对象。
- 权衡
- 如何创建对象
- 如何更新对象
- 如何删除对象
- 如何查看对象
- 限制
- 在不保存配置的情况下从URL创建和编辑对象
- 从命令式命令迁移到命令式对象配置
- 定义控制器选择器和PodTemplate标签
权衡
该kubectl工具支持三种对象管理:
- 命令式命令
- 势在必行的对象配置
- 声明性对象配置
有关每种对象管理 的优缺点的讨论,请参阅Kubernetes对象管理。
如何创建对象
您可以使用kubectl create -f从配置文件创建对象。 有关详细信息,请参阅kubernetes API参考。
kubectl create -f <filename|url>
如何更新对象
警告:使用该
replace命令更新对象会删除配置文件中未指定的规范的所有部分。这不应该与规范部分由集群管理的对象一起使用,例如类型服务LoadBalancer,其中externalIPs字段独立于配置文件进行管理。必须将独立管理的字段复制到配置文件中以防止replace丢弃它们。
您可以使用kubectl replace -f根据配置文件更新活动对象。
kubectl replace -f <filename|url>
如何删除对象
您可以使用kubectl delete -f删除配置文件中描述的对象。
kubectl delete -f <filename|url>
如何查看对象
您可以使用它kubectl get -f来查看有关配置文件中描述的对象的信息。
kubectl get -f <filename|url> -o yaml
该-o yaml标志指定打印完整对象配置。使用kubectl get -h查看选项列表。
限制
create,replace和delete命令工作得很好,当每个对象的配置完全确定并记录在它的配置文件。但是,当更新活动对象并且更新未合并到其配置文件中时,更新将在下次replace 执行时丢失。如果控制器(例如HorizontalPodAutoscaler)直接对活动对象进行更新,则会发生这种情况。这是一个例子:
- 您可以从配置文件创建对象。
- 另一个源通过更改某个字段来更新对象。
- 您从配置文件中替换该对象。步骤2中其他来源所做的更改将丢失。
如果需要支持同一对象的多个编写器,则可以使用它kubectl apply来管理对象。
在不保存配置的情况下从URL创建和编辑对象
假设您具有对象配置文件的URL。您可以 kubectl create --edit在创建对象之前用于更改配置。这对于指向可由读者修改的配置文件的教程和任务特别有用。
1 | kubectl create -f <url> --edit |
从命令式命令迁移到命令式对象配置
- 从命令式命令迁移到命令式对象配置涉及几个手动步骤。
将活动对象导出到本地对象配置文件:
1 | kubectl get <kind>/<name> -o yaml --export > <kind>_<name>.yaml |
从对象配置文件中手动删除状态字段。
对于后续对象管理,请
replace专门使用。
1 | kubectl replace -f <kind>_<name>.yaml |
定义控制器选择器和PodTemplate标签
警告:强烈建议不要更新控制器上的选择器。
推荐的方法是定义一个仅由控制器选择器使用的单个不可变PodTemplate标签,没有其他语义含义。
示例标签:1
2
3
4
5
6
7selector:
matchLabels:
controller-selector: "extensions/v1beta1/deployment/nginx"
template:
metadata:
labels:
controller-selector: "extensions/v1beta1/deployment/nginx"
使用配置文件声明管理Kubernetes对象
可以通过在目录中存储多个对象配置文件并使用kubectl apply根据需要递归创建和更新这些对象来创建,更新和删除Kubernetes对象。此方法保留对活动对象的写入,而不将更改合并回对象配置文件。kubectl diff还可以预览apply将要进行的更改。
- 权衡
- 在你开始之前
- 如何创建对象
- 如何更新对象
- 如何删除对象
- 如何查看对象
- 如何应用计算差异并合并更改
- 默认字段值
- 如何更改配置文件和直接命令式编写器之间字段的所有权
- 改变管理方法
- 定义控制器选择器和PodTemplate标签
权衡
该kubectl工具支持三种对象管理:
- 命令式命令
- 势在必行的对象配置
- 声明性对象配置
有关每种对象管理 的优缺点的讨论,请参阅Kubernetes对象管理。
在你开始之前
声明性对象配置需要牢固地理解Kubernetes对象定义和配置。如果您还没有阅读并填写以下文件:
以下是本文档中使用的术语的定义:
- 对象配置文件/配置文件:定义Kubernetes对象配置的文件。本主题说明如何将配置文件传递给
kubectl apply。配置文件通常存储在源代码管理中,例如Git。 - 实时对象配置/实时配置:Kubernetes集群观察到的对象的实时配置值。这些保存在Kubernetes集群存储中,通常是etcd。
- 声明性配置writer / declarative writer:对活动对象进行更新的人员或软件组件。本主题中提到的实时编写器会更改对象配置文件并运行
kubectl apply以编写更改。
如何创建对象
使用kubectl apply创建的所有对象,除了那些已经存在,通过配置文件在指定的目录中定义:1
kubectl apply -f <directory>/
这将kubectl.kubernetes.io/last-applied-configuration: '{...}'在每个对象上设置注释。注释包含用于创建对象的对象配置文件的内容。
注意:添加-R标志以递归处理目录。
以下是对象配置文件的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#application/simple_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
运行kubectl diff以打印将要创建的对象:1
kubectl diff -f https://k8s.io/examples/application/simple_deployment.yaml
注意:
diff使用服务器端干运行,需要启用kube-apiserver。
使用kubectl apply以下方法创建对象1
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
使用kubectl get以下方式打印实时配置1
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示kubectl.kubernetes.io/last-applied-configuration注释已写入实时配置,并且与配置文件匹配:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36kind: Deployment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
spec:
minReadySeconds: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- containerPort: 80
如何更新对象
您还可以使用kubectl apply更新目录中定义的所有对象,即使这些对象已存在。此方法可实现以下目标:
- 设置实时配置中配置文件中显示的字段。
- 清除实时配置中从配置文件中删除的字段。
1 | kubectl diff -f <directory>/ |
注意:添加-R标志以递归处理目录。
这是一个示例配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#application/simple_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用kubectl apply以下方法创建对象1
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
注意:出于说明的目的,上述命令引用单个配置文件而不是目录。
使用kubectl get以下方式打印实时配置1
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示kubectl.kubernetes.io/last-applied-configuration注释已写入实时配置,并且与配置文件匹配:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36kind: Deployment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
spec:
minReadySeconds: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- containerPort: 80
使用,直接更新replicas实时配置中的字段kubectl scale。这不使用kubectl apply:1
kubectl scale deployment/nginx-deployment --replicas=2
使用kubectl get以下方式打印实时配置1
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示该replicas字段已设置为2,并且last-applied-configuration注释不包含replicas字段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
spec:
replicas: 2
minReadySeconds: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- containerPort: 80
更新simple_deployment.yaml配置文件以将映像更改 nginx:1.7.9为nginx:1.11.9,并删除该minReadySeconds字段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#application/update_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.11.9 # update the image
ports:
- containerPort: 80
应用对配置文件所做的更改:1
2kubectl diff -f https://k8s.io/examples/application/update_deployment.yaml
kubectl apply -f https://k8s.io/examples/application/update_deployment.yaml
使用kubectl get以下方式打印实时配置1
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示实时配置的以下更改:
该replicas字段保留2的值kubectl scale。这是可能的,因为它从配置文件中省略。
该image场已被更新,以nginx:1.11.9从nginx:1.7.9。
该last-applied-configuration批注已经更新了新的形象。
该minReadySeconds领域已被清除。
该last-applied-configuration注释不再包含minReadySeconds字段。
1 | apiVersion: apps/v1 |
警告:混合
kubectl apply与势在必行对象配置命令create和replace不支持。这是因为create并replace没有保留kubectl.kubernetes.io/last-applied-configuration的是kubectl apply用来计算更新。
如何删除对象
删除管理对象有两种方法kubectl apply。
推荐的: kubectl delete -f <filename>
建议的方法是使用命令式命令手动删除对象,因为它更明确地删除了什么,并且不太可能导致用户无意中删除了某些内容1
kubectl delete -f <filename>
替代方案: kubectl apply -f <directory/> --prune -l your=label
只有在你知道自己在做什么的情况下才能使用它。
警告:
kubectl apply --prune处于alpha状态,后续版本中可能会引入向后不兼容的更改。
警告:使用此命令时必须小心,以免意外删除对象。
作为替代方法kubectl delete,您可以使用它kubectl apply来识别从目录中删除配置文件后要删除的对象。--prune 对API服务器应用查询以匹配一组标签的所有对象,并尝试将返回的活动对象配置与对象配置文件进行匹配。如果对象与查询匹配,并且目录中没有配置文件,并且它具有last-applied-configuration注释,则会将其删除。1
kubectl apply -f <directory/> --prune -l <labels>
警告:只应对包含对象配置文件的根目录运行prune。如果对象被指定的标签选择器查询返回-l
并且未出现在子目录中,则对子目录运行会导致无意中删除对象。
如何查看对象
您可以使用kubectl getwith -o yaml来查看活动对象的配置:
1 | kubectl get -f <filename|url> -o yaml |
如何应用计算差异并合并更改
注意:补丁是一种更新操作,其范围限定为对象的特定字段而不是整个对象。这样可以仅更新对象上的特定字段集,而无需先读取对象。
当kubectl apply一个对象更新实时配置,它通过发送补丁请求API服务器这样做。该补丁定义了作用于活动对象配置的特定字段的更新。该kubectl apply命令使用配置文件,实时配置和实时配置中last-applied-configuration存储的注释来计算此修补程序请求 。
合并补丁计算
该kubectl apply命令将配置文件的内容写入 kubectl.kubernetes.io/last-applied-configuration注释。这用于标识已从配置文件中删除的字段,需要从实时配置中清除。以下是用于计算应删除或设置哪些字段的步骤:
- 计算要删除的字段。这些是
last-applied-configuration配置文件中存在和丢失的字段。 - 计算要添加或设置的字段。这些是配置文件中存在的字段,其值与实时配置不匹配。
这是一个例子。假设这是Deployment对象的配置文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#application/update_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.11.9 # update the image
ports:
- containerPort: 80
另外,假设这是同一Deployment对象的实时配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"minReadySeconds":5,"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.7.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
spec:
replicas: 2
minReadySeconds: 5
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx:1.7.9
name: nginx
ports:
- containerPort: 80
以下是将通过以下方式执行的合并计算kubectl apply:
- 通过读取值
last-applied-configuration并将它们与配置文件中的值进行比较来计算要删除的字段 。清除字段在本地对象配置文件中显式设置为null,无论它们是否出现在last-applied-configuration。在此示例中,minReadySeconds出现在last-applied-configuration注释中,但未出现在配置文件中。 Action:minReadySeconds`从实时配置中清除。 - 通过从配置文件中读取值并将它们与实时配置中的值进行比较来计算要设置的字段。在此示例中,
image配置文件中的值与实时配置中的值不匹配。Action:设置image实时配置中的值。 - 设置
last-applied-configuration注释以匹配配置文件的值。 - 将来自1,2,3的结果合并到API服务器的单个补丁请求中。
以下是合并的实时配置:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
# ...
# The annotation contains the updated image to nginx 1.11.9,
# but does not contain the updated replicas to 2
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"apps/v1","kind":"Deployment",
"metadata":{"annotations":{},"name":"nginx-deployment","namespace":"default"},
"spec":{"selector":{"matchLabels":{"app":nginx}},"template":{"metadata":{"labels":{"app":"nginx"}},
"spec":{"containers":[{"image":"nginx:1.11.9","name":"nginx",
"ports":[{"containerPort":80}]}]}}}}
# ...
spec:
selector:
matchLabels:
# ...
app: nginx
replicas: 2 # Set by `kubectl scale`. Ignored by `kubectl apply`.
# minReadySeconds cleared by `kubectl apply`
# ...
template:
metadata:
# ...
labels:
app: nginx
spec:
containers:
- image: nginx:1.11.9 # Set by `kubectl apply`
# ...
name: nginx
ports:
- containerPort: 80
# ...
# ...
# ...
# ...
如何合并不同类型的字段
配置文件中的特定字段如何与实时配置合并取决于字段的类型。有几种类型的字段:
- primitive:字符串,整数或布尔类型的字段。例如,
image和replicas是原始字段。行动:替换。 - map,也称为object:类型为map的字段或包含子字段的复杂类型。例如
labels,annotations,spec并且metadata是所有map。Action:合并元素或子字段。 - list:包含可以是基本类型或映射的项列表的字段。例如
containers,ports和args是列表。行动:变化。
当kubectl apply更新map或列表字段,它通常不更换整个领域,而是更新各个子元素。例如,在合并spec部署时,spec不会替换整个部署。相反,比较和合并spec诸如的子字段replicas。
将更改合并到基本字段
将更改合并到基本字段
注意: -用于“不适用”,因为未使用该值。
| 对象配置文件中的字段 | 实时对象配置中的字段 | 最后应用配置中的字段 | 行动 |
|---|---|---|---|
| 是 | 是 | - | 设置为配置文件值。 |
| 是 | 没有 | - | 将实时设置为本地配置。 |
| 没有 | - | - | 从实时配置中清除。 |
| 没有 | - | 没有 | 没做什么。保持实时价值。 |
合并对地图字段的更改
通过比较地图的每个子字段或元素来合并表示地图的字段:
注意: -用于“不适用”,因为未使用该值。
| 键入对象配置文件 | 键入实时对象配置 | 最后应用配置中的字段 | 行动 |
|---|---|---|---|
| 是 | 是 | - | 比较子字段值。 |
| 是 | 没有 | - | 将实时设置为本地配置。 |
| 没有 | - | 是 | 从实时配置中删除。 |
| 没有 | - | 没有 | 没做什么。保持实时价值。 |
合并类型列表字段的更改
将更改合并到列表使用以下三种策略之一:
- 替换列表。
- 合并复杂元素列表中的各个元素。
- 合并原始元素列表。
战略的选择是基于每个领域。
替换列表
将列表视为与原始字段相同。替换或删除整个列表。这保留了订购。
例如:使用kubectl apply更新args一个pod里的一个Container的field。这会将args实时配置中的值设置为配置文件中的值。args之前已添加到实时配置的任何元素都将丢失。args配置文件中定义的元素的顺序将保留在实时配置中。1
2
3
4
5
6
7
8
9
10
11
args: ["a", "b"]
args: ["a", "c"]
args: ["a", "b", "d"]
args: ["a", "c"]
说明:合并使用配置文件值作为新列表值。
合并复杂元素列表中的各个元素:
将列表视为映射,并将每个元素的特定字段视为键。添加,删除或更新单个元素。这不会保留排序。
此合并策略在每个字段上使用一个名为a的特殊标记patchMergeKey。patchMergeKey是在Kubernetes源代码中的每个字段中定义: types.go 当合并映射的列表,指定的字段作为patchMergeKey对于给定的元素被用于像该元素的映射键。
例如:使用kubectl apply更新containers一PodSpec的field。这将列表合并为好像是每个元素都被键入的映射name。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42# last-applied-configuration value
containers:
- name: nginx
image: nginx:1.10
- name: nginx-helper-a # key: nginx-helper-a; will be deleted in result
image: helper:1.3
- name: nginx-helper-b # key: nginx-helper-b; will be retained
image: helper:1.3
# configuration file value
containers:
- name: nginx
image: nginx:1.10
- name: nginx-helper-b
image: helper:1.3
- name: nginx-helper-c # key: nginx-helper-c; will be added in result
image: helper:1.3
# live configuration
containers:
- name: nginx
image: nginx:1.10
- name: nginx-helper-a
image: helper:1.3
- name: nginx-helper-b
image: helper:1.3
args: ["run"] # Field will be retained
- name: nginx-helper-d # key: nginx-helper-d; will be retained
image: helper:1.3
# result after merge
containers:
- name: nginx
image: nginx:1.10
# Element nginx-helper-a was deleted
- name: nginx-helper-b
image: helper:1.3
args: ["run"] # Field was retained
- name: nginx-helper-c # Element was added
image: helper:1.3
- name: nginx-helper-d # Element was ignored
image: helper:1.3
说明:
- 名为“nginx-helper-a”的容器已删除,因为配置文件中没有出现名为“nginx-helper-a”的容器。
- 名为“nginx-helper-b”的容器保留
args了实时配置中的更改。kubectl apply能够识别实时配置中的“nginx-helper-b”与配置文件中的“nginx-helper-b”相同,即使它们的字段具有不同的值(args配置文件中没有)。这是因为patchMergeKey字段值(名称)在两者中都是相同的。 - 添加了名为“nginx-helper-c”的容器,因为实时配置中没有出现具有该名称的容器,但配置文件中出现了具有该名称的容器。
- 保留名为“nginx-helper-d”的容器,因为在最后应用的配置中没有出现具有该名称的元素。
合并原始元素列表
从Kubernetes 1.5开始,不支持合并原始元素列表。
注意:为给定字段选择的上述策略中的哪一个由types.go中的
patchStrategy标记控制。如果没有为类型列表的字段指定patchStrategy,则替换列表。
默认字段值
如果在创建对象时未指定某些字段,则API服务器会将某些字段设置为实时配置中的默认值。
这是部署的配置文件。该文件未指定strategy:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#application/simple_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
使用kubectl apply以下方法创建对象1
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
使用kubectl get以下方式打印实时配置1
kubectl get -f https://k8s.io/examples/application/simple_deployment.yaml -o yaml
输出显示API服务器在实时配置中将多个字段设置为默认值。配置文件中未指定这些字段。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34apiVersion: apps/v1
kind: Deployment
# ...
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 5
replicas: 1 # defaulted by apiserver
strategy:
rollingUpdate: # defaulted by apiserver - derived from strategy.type
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate # defaulted apiserver
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
containers:
- image: nginx:1.7.9
imagePullPolicy: IfNotPresent # defaulted by apiserver
name: nginx
ports:
- containerPort: 80
protocol: TCP # defaulted by apiserver
resources: {} # defaulted by apiserver
terminationMessagePath: /dev/termination-log # defaulted by apiserver
dnsPolicy: ClusterFirst # defaulted by apiserver
restartPolicy: Always # defaulted by apiserver
securityContext: {} # defaulted by apiserver
terminationGracePeriodSeconds: 30 # defaulted by apiserver
# ...
在修补程序请求中,默认字段不会被重新默认,除非它们作为修补程序请求的一部分被明确清除。这可能会导致基于其他字段的值默认的字段出现意外行为。稍后更改其他字段时,除非明确清除,否则不会更新默认值。
因此,建议在配置文件中显式定义服务器默认的某些字段,即使所需的值与服务器默认值匹配也是如此。这样可以更轻松地识别不会被服务器重新默认的冲突值。
例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63# last-applied-configuration
spec:
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
# configuration file
spec:
strategy:
type: Recreate # updated value
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
# live configuration
spec:
strategy:
type: RollingUpdate # defaulted value
rollingUpdate: # defaulted value derived from type
maxSurge : 1
maxUnavailable: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
# result after merge - ERROR!
spec:
strategy:
type: Recreate # updated value: incompatible with rollingUpdate
rollingUpdate: # defaulted value: incompatible with "type: Recreate"
maxSurge : 1
maxUnavailable: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
说明:
- 用户无需定义即可创建部署
strategy.type。 - 服务器默认
strategy.type为RollingUpdate默认strategy.rollingUpdate值。 - 用户更改
strategy.type为Recreate。该strategy.rollingUpdate值保持在其默认的值,但服务器期望他们被清除。如果strategy.rollingUpdate最初在配置文件中定义了值,则更清楚的是它们需要被删除。 - 应用失败,因为
strategy.rollingUpdate未清除。该strategy.rollingupdate字段不能与被定义strategy.type的Recreate。
建议:应在对象配置文件中明确定义这些字段:
- 工作负载上的选择器和PodTemplate标签,例如Deployment,StatefulSet,Job,DaemonSet,ReplicaSet和ReplicationController
- 部署部署策略
如何清除其他编写者设置的服务器默认字段或字段
可以通过将其值设置为null然后应用配置文件来清除未出现在配置文件中的字段。对于服务器默认的字段,这会触发重新默认值。
如何更改配置文件和直接命令式编写器之间字段的所有权
这些是您应该用来更改单个对象字段的唯一方法:
- 使用
kubectl apply。 - 直接写入实时配置而不修改配置文件:例如,使用
kubectl scale。
将所有者从直接命令式编写器更改为配置文件
将该字段添加到配置文件中。对于现场,停止对未经过的实时配置的直接更新kubectl apply。
将所有者从配置文件更改为直接命令式编写器
从Kubernetes 1.5开始,将字段的所有权从配置文件更改为命令式编写器需要手动步骤:
- 从配置文件中删除该字段。
- 从
kubectl.kubernetes.io/last-applied-configuration活动对象上的注释中删除该字段。
改变管理方法
应该一次只使用一种方法管理Kubernetes对象。可以从一种方法切换到另一种方法,但这是一种手动过程。
注意:使用命令式删除和声明式管理是可以的。
从命令式命令管理迁移到声明性对象配置
从命令式命令管理迁移到声明性对象配置涉及几个手动步骤:
将活动对象导出到本地配置文件:
1
kubectl get <kind>/<name> -o yaml --export > <kind>_<name>.yaml
status从配置文件中手动删除该字段。
注意:此步骤是可选的,因为
kubectl apply不会更新状态字段 即使它存在于配置文件中。
kubectl.kubernetes.io/last-applied-configuration在对象上设置注释:1
kubectl replace --save-config -f <kind>_<name>.yaml
更改
kubectl apply用于专门管理对象的进程。
从命令式对象配置迁移到声明性对象配置
kubectl.kubernetes.io/last-applied-configuration在对象上设置注释:1
kubectl replace --save-config -f <kind>_<name>.yaml
更改
kubectl apply用于专门管理对象的进程。
定义控制器选择器和PodTemplate标签
警告:强烈建议不要更新控制器上的选择器。
推荐的方法是定义一个仅由控制器选择器使用的单个不可变PodTemplate标签,没有其他语义含义。
例:1
2
3
4
5
6
7selector:
matchLabels:
controller-selector: "extensions/v1beta1/deployment/nginx"
template:
metadata:
labels:
controller-selector: "extensions/v1beta1/deployment/nginx"
Kubernetes Architecture
节点
节点是Kubernetes中的工作机器,以前称为一个 minion。节点可以是VM或物理机,具体取决于集群。每个节点都包含运行pods所需的服务,并由主组件管理。节点上的服务包括container runtime,kubelet和kube-proxy。有关更多详细信息,请参阅 体系结构设计文档中的Kubernetes节点部分。
- 节点状态
- 管理
- API对象
节点状态
节点的状态包含以下信息:
- 地址
- 条件
- 容量
- 信息
下面详细描述每个部分。
地址
这些字段的使用取决于您的云提供商或裸机配置。
- HostName:节点内核报告的主机名。可以通过kubelet
--hostname-override参数覆盖。 - ExternalIP:通常是可从外部路由的节点的IP地址(可从群集外部获得)。
- InternalIP:通常仅在群集内可路由的节点的IP地址。
条件
该conditions字段描述了所有Running节点的状态。
| 节点条件 | 描述 |
|---|---|
OutOfDisk |
True 如果节点上的可用空间不足以添加新的pod,否则 False |
Ready |
True如果节点是健康的并准备好接受pod,False如果节点不健康且不接受pod,并且Unknown节点控制器在最后一次没有从节点听到node-monitor-grace-period(默认为40秒) |
MemoryPressure |
True如果节点存储器上存在压力 - 即节点存储器是否为低; 除此以外False |
PIDPressure |
True如果进程存在压力 - 也就是说,如果节点上有太多进程; 除此以外False |
DiskPressure |
True如果磁盘大小存在压力 - 即磁盘容量低; 除此以外False |
NetworkUnavailable |
True 如果没有正确配置节点的网络,否则 False |
节点条件表示为JSON对象。例如,以下响应描述了健康节点。1
2
3
4
5
6"conditions": [
{
"type": "Ready",
"status": "True"
}
]
如果就绪状态的状态保持Unknown或False超过pod-eviction-timeout,则会将参数传递给kube-controller-manager,并且节点控制器会调度节点上的所有Pod以进行删除。默认逐出超时持续时间为五分钟。在某些情况下,当节点无法访问时,apiserver无法与节点上的kubelet通信。在重新建立与apiserver的通信之前,不能将删除pod的决定传送到kubelet。同时,计划删除的pod可以继续在分区节点上运行。
在1.5之前的Kubernetes版本中,节点控制器会从apiserver中强制删除这些无法访问的pod。但是,在1.5及更高版本中,节点控制器不会强制删除容器,直到确认它们已停止在群集中运行。您可以看到可能在无法访问的节点上运行的Pod处于Terminating或Unknown状态。如果节点永久离开群集,如果Kubernetes无法从底层基础架构推断出,则群集管理员可能需要手动删除节点对象。从Kubernetes中删除节点对象会导致节点上运行的所有Pod对象从apiserver中删除,并释放它们的名称。
在版本1.12中,TaintNodesByCondition功能被提升为beta版,因此节点生命周期控制器会自动创建表示条件的 taints 。类似地,调度程序在考虑节点时忽略条件;相反,它会查看Node的污点和Pod的容忍度。 现在,用户可以在旧的调度模型和更灵活的新调度模型之间进行选择。根据旧型号,可以安排没有任何容忍度的Pod。但是可以在该节点上安排容忍特定节点的污点的Pod。
警告:启用此功能会在观察到条件和创建污点之间产生一个小延迟。此延迟通常小于一秒,但它可以增加成功安排但被kubelet拒绝的Pod的数量。
容量
描述节点上可用的资源:CPU,内存以及可以在节点上调度的最大pod数。
信息
有关节点的一般信息,例如内核版本,Kubernetes版本(kubelet和kube-proxy版本),Docker版本(如果使用),操作系统名称。信息由Kubelet从节点收集。
管理
与pod和服务不同,Kubernetes本身并不创建节点:它由Google Compute Engine等云提供商在外部创建,或者存在于物理或虚拟机池中。因此,当Kubernetes创建节点时,它会创建一个表示节点的对象。创建后,Kubernetes会检查节点是否有效。例如,如果您尝试从以下内容创建节点:1
2
3
4
5
6
7
8
9
10{
"kind": "Node",
"apiVersion": "v1",
"metadata": {
"name": "10.240.79.157",
"labels": {
"name": "my-first-k8s-node"
}
}
}
Kubernetes在内部创建节点对象(表示),并通过基于metadata.name字段的运行状况检查来验证节点。如果节点有效 - 即,如果所有必需的服务都在运行 - 它有资格运行pod。否则,对于任何群集活动,它将被忽略,直到它变为有效。
注意: Kubernetes保留无效节点的对象,并不断检查它是否有效。您必须显式删除Node对象才能停止此过程。
目前,有三个组件与Kubernetes节点接口交互:节点控制器,kubelet和kubectl。
节点控制器
节点控制器是Kubernetes主组件,它管理节点的各个方面。
节点控制器在节点的生命周期中具有多个角色。第一种是在注册时为节点分配CIDR块(如果打开了CIDR分配)。
第二个是使节点控制器的内部节点列表与云提供商的可用计算机列表保持同步。在云环境中运行时,只要节点不健康,节点控制器就会询问云提供商该节点的VM是否仍然可用。如果不是,则节点控制器从其节点列表中删除该节点。
第三是监测节点的健康状况。节点控制器负责在节点变得无法访问时将NodeStatus的NodeReady条件更新为ConditionUnknown(即节点控制器由于某种原因停止接收心跳,例如由于节点关闭),然后从节点中驱逐所有pod (如果节点仍然无法访问,则使用正常终止)。(默认超时为40 --node-monitor-period秒,开始报告ConditionUnknown,之后5米开始驱逐pod。)节点控制器每秒检查每个节点的状态。
在1.13之前的Kubernetes版本中,NodeStatus是节点的心跳。从Kubernetes 1.13开始,节点租用功能作为alpha功能引入(功能门NodeLease, KEP-0009)。启用节点租用功能时,每个节点都有一个关联的Lease对象 kube-node-lease由节点定期更新的命名空间,NodeStatus和节点租约都被视为来自节点的心跳。节点租约经常更新,而NodeStatus仅在有一些更改或经过足够时间时从节点报告为主节点(默认值为1分钟,这比不可达节点的默认超时40秒)。由于节点租约比NodeStatus轻得多,因此从可伸缩性和性能角度来看,此功能使节点心跳显着降低。
在Kubernetes 1.4中,我们更新了节点控制器的逻辑,以便在大量节点到达主站时遇到问题时更好地处理案例(例如,因为主站有网络问题)。从1.4开始,节点控制器在决定pod驱逐时查看集群中所有节点的状态。
在大多数情况下,节点控制器将驱逐率限制为每秒 --node-eviction-rate(默认值0.1),这意味着它不会每10秒从多个节点驱逐pod。
当给定可用区中的节点变得不健康时,节点逐出行为会发生变化。节点控制器同时检查区域中节点的百分比是否不健康(NodeReady条件是ConditionUnknown或ConditionFalse)。如果不健康节点的比例至少为 --unhealthy-zone-threshold(默认为0.55),则驱逐率降低:如果群集较小(即小于或等于--large-cluster-size-threshold节点 - 默认为50)则停止驱逐,否则驱逐率降低为 --secondary-node-eviction-rate(默认0.01)每秒。每个可用区域实施这些策略的原因是因为一个可用区域可能从主服务器分区而其他可用区域保持连接。如果您的群集未跨越多个云提供商可用区域,则只有一个可用区域(整个群集)。
在可用区域之间传播节点的一个关键原因是,当整个区域出现故障时,工作负载可以转移到健康区域。因此,如果区域中的所有节点都不健康,则节点控制器以正常速率驱逐--node-eviction-rate。角落情况是所有区域完全不健康(即群集中没有健康的节点)。在这种情况下,节点控制器假定主连接存在一些问题,并在某些连接恢复之前停止所有驱逐。
从Kubernetes 1.6开始,NodeController还负责驱逐在具有NoExecute污点的节点上运行的pod,当pod不能容忍taints时。此外,作为默认禁用的alpha功能,NodeController负责添加与节点无法访问或未就绪等节点问题相对应的污点。 有关污点和alpha功能的详细信息,请参阅此文档NoExecute。
从版本1.8开始,节点控制器可以负责创建表示节点条件的污点。这是1.8版的alpha功能。
节点自注册
当kubelet标志--register-node为true(默认值)时,kubelet将尝试向API服务器注册自己。这是大多数发行版使用的首选模式。
对于自行注册,可以使用以下选项启动kubelet:
--kubeconfig- 凭证路径,以向apiserver验证自身。--cloud-provider- 如何与云提供商交谈以阅读有关自身的元数据。--register-node- 自动注册API服务器。--register-with-taints- 使用给定的taints列表注册节点(以逗号分隔<key>=<value>:<effect>)。No-op如果register-node是假的。--node-ip- 节点的IP地址。--node-labels- 在群集中注册节点时添加的标签(请参阅1.13+中NodeRestriction准入插件强制执行的标签限制)。--node-status-update-frequency- 指定kubelet将节点状态发布到master的频率。
当节点授权模式和 NodeRestriction录取插件的启用,kubelets仅被授权创建/修改自己的节点资源。
手动节点管理
集群管理员可以创建和修改节点对象。
如果管理员希望手动创建节点对象,请设置kubelet标志 --register-node=false。
管理员可以修改节点资源(无论设置如何--register-node)。修改包括在节点上设置标签并将其标记为不可调度。
节点上的标签可以与pod上的节点选择器结合使用以控制调度,例如,将pod限制为仅有资格在节点的子集上运行。
将节点标记为不可调度可防止将新pod调度到该节点,但不会影响节点上的任何现有pod。这在节点重启等之前作为准备步骤很有用。例如,要标记节点不可调度,请运行以下命令:1
kubectl cordon $NODENAME
注意:由DaemonSet控制器创建的Pod绕过Kubernetes调度程序,不遵守节点上的不可调度属性。这假设守护进程属于机器,即使它在准备重新启动时正在耗尽应用程序。
节点容量
节点的容量(cpus的数量和内存量)是节点对象的一部分。通常,节点在创建节点对象时注册自己并报告其容量。如果您正在进行手动节点管理,则需要在添加节点时设置节点容量。
Kubernetes调度程序确保节点上的所有pod都有足够的资源。它检查节点上容器请求的总和不大于节点容量。它包括由kubelet启动的所有容器,但不包括由容器运行时直接启动的容器,也不包括在容器外部运行的任何进程。
如果要为非Pod进程显式保留资源,请按照本教程 为系统守护程序保留资源。
API对象
Node是Kubernetes REST API中的顶级资源。有关API对象的更多详细信息,请参见: Node API对象。
主节点通信
本文档对master(实际上是apiserver)和Kubernetes集群之间的通信路径进行了编目。目的是允许用户自定义其安装以强化网络配置,以便群集可以在不受信任的网络(或云提供商上的完全公共IP)上运行。
- 群集到Master
- 掌握群集
群集到Master
从集群到主服务器的所有通信路径都在apiserver处终止(其他主服务器组件均未设计为公开远程服务)。在典型部署中,apiserver被配置为在安全HTTPS端口(443)上侦听远程连接,其中启用了一种或多种形式的客户端认证。 应启用一种或多种授权形式,尤其是 在允许匿名请求 或服务帐户令牌的情况下。
应为节点配置群集的公共根证书,以便它们可以安全地连接到apiserver以及有效的客户端凭据。例如,在默认GKE部署中,提供给kubelet的客户端凭证采用客户端证书的形式。请参阅 kubelet TLS bootstrapping 以自动配置kubelet客户端证书。
希望连接到apiserver的Pod可以通过利用服务帐户安全地执行此操作,以便Kubernetes在实例化时自动将公共根证书和有效的承载令牌注入到pod中。该kubernetes服务(在所有名称空间中)配置有虚拟IP地址,该地址被重定向(通过kube-proxy)到apiserver上的HTTPS端点。
主组件还通过安全端口与群集服务器通信。
因此,默认情况下,从群集(节点和节点上运行的节点)到主节点的连接的默认操作模式是安全的,可以在不受信任和/或公共网络上运行。
掌握群集
从主服务器(apiserver)到集群有两条主要通信路径。第一个是从apiserver到kubelet进程,它在集群中的每个节点上运行。第二种是通过apiserver的代理功能从apiserver到任何节点,pod或服务。
kubelet的保护者
从apiserver到kubelet的连接用于:
- 获取pod的日志。
- 附加(通过kubectl)到运行的pod。
- 提供kubelet的端口转发功能。
这些连接终止于kubelet的HTTPS端点。默认情况下,apiserver不会验证kubelet的服务证书,这会使连接受到中间人攻击,并且 不安全地运行在不受信任的和/或公共网络上。
要验证此连接,请使用该--kubelet-certificate-authority标志为apiserver提供根证书包,以用于验证kubelet的服务证书。
如果无法做到这一点,请 在apiserver和kubelet之间使用SSH隧道,以避免连接不受信任或公共网络。
最后, 应启用Kubelet身份验证和/或授权以保护kubelet API。
节点,pod和服务的apiserver
从apiserver到节点,pod或服务的连接默认为纯HTTP连接,因此既未经过身份验证也未加密。它们可以通过前缀https:到API URL中的节点,pod或服务名称在安全HTTPS连接上运行,但它们不会验证HTTPS端点提供的证书,也不会提供客户端凭据,因此在连接将被加密时,它不会提供任何诚信保证。这些连接目前在不受信任和/或公共网络上运行是不安全的。
云控制器管理器的基础概念
最初创建云控制器管理器(CCM)概念(不要与二进制混淆),以允许特定于云的供应商代码和Kubernetes核心彼此独立地发展。云控制器管理器与其他主组件(如Kubernetes控制器管理器,API服务器和调度程序)一起运行。它也可以作为Kubernetes插件启动,在这种情况下它运行在Kubernetes之上。
云控制器管理器的设计基于一种插件机制,允许新的云提供商通过使用插件轻松地与Kubernetes集成。有计划在Kubernetes上加入新的云提供商,以及将云提供商从旧模型迁移到新的CCM模型。
本文档讨论了云控制器管理器背后的概念,并提供了有关其相关功能的详细信息。
这是没有云控制器管理器的Kubernetes集群的架构:
- 设计
- CCM的组成部分
- CCM的功能
- 插件机制
- 授权
- 供应商实施
- 群集管理
设计
在上图中,Kubernetes和云提供商通过几个不同的组件集成:
- Kubelet
- Kubernetes控制器经理
- Kubernetes API服务器
CCM整合了前三个组件中的所有依赖于云的逻辑,以创建与云的单一集成点。CCM的新架构如下所示: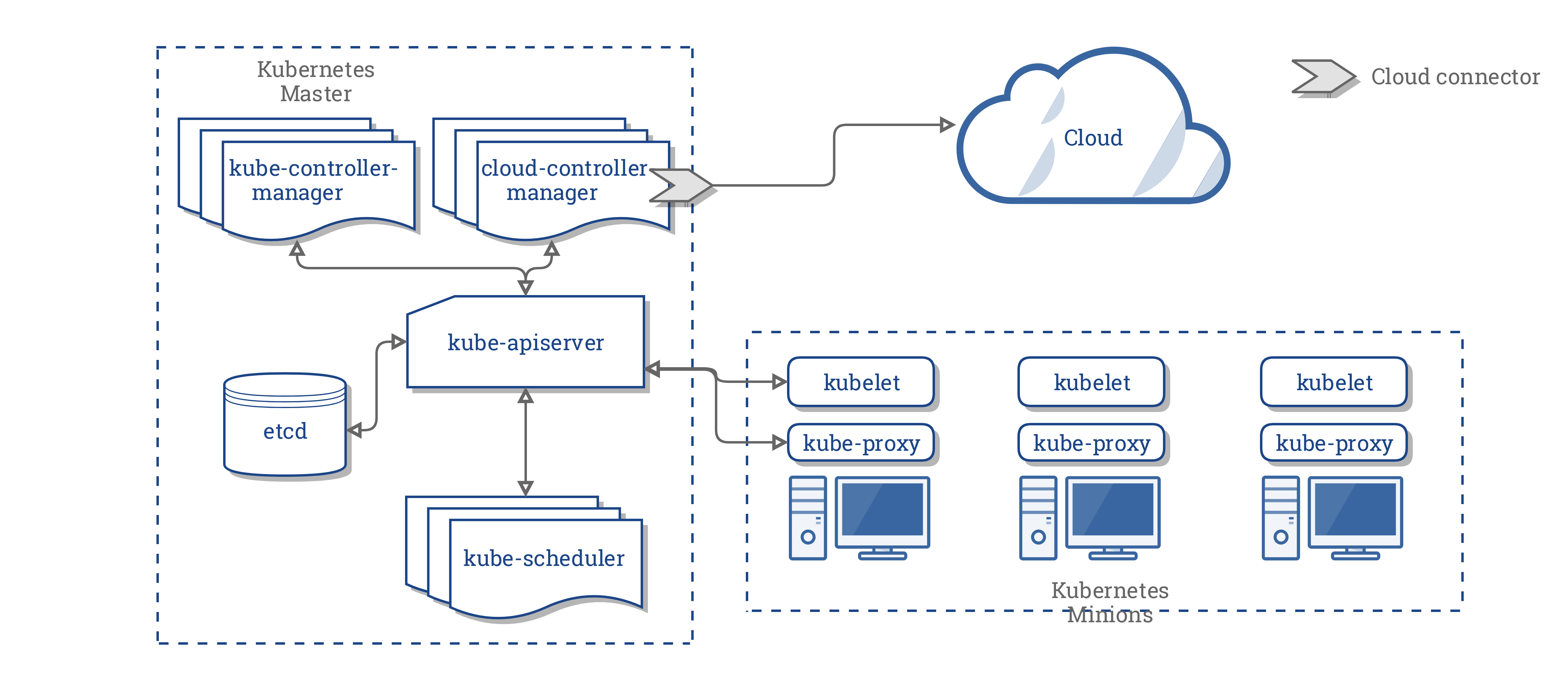
CCM的组成部分
CCM打破了Kubernetes控制器管理器(KCM)的一些功能,并将其作为一个单独的进程运行。具体来说,它打破了KCM中依赖于云的控制器。KCM具有以下依赖于云的控制器循环:
- 节点控制器
- 音量控制器
- 路线控制器
- 服务控制器
在1.9版中,CCM运行前面列表中的以下控制器:
- 节点控制器
- 路线控制器
- 服务控制器
此外,它还运行另一个名为PersistentVolumeLabels控制器的控制器。此控制器负责在GCP和AWS云中创建的PersistentVolumes上设置区域和区域标签。
注意:故意选择音量控制器不属于CCM。由于涉及复杂性并且由于现有的努力抽象出供应商特定的卷逻辑,因此决定不将卷控制器移动到CCM。
使用CCM支持卷的最初计划是使用Flex卷来支持可插拔卷。然而,正在计划一项名为CSI的竞争性工作来取代Flex。
考虑到这些动态,我们决定在CSI准备好之前进行中间止差测量。
CCM的功能
CCM从依赖于云提供商的Kubernetes组件继承其功能。本节基于这些组件构建。
1. Kubernetes控制器经理
CCM的大部分功能来自KCM。如上一节所述,CCM运行以下控制循环:
- 节点控制器
- 路线控制器
- 服务控制器
- PersistentVolumeLabels控制器
节点控制器
节点控制器负责通过从云提供商获取有关在集群中运行的节点的信息来初始化节点。节点控制器执行以下功能:
- 使用特定于云的区域/区域标签初始化节点。
- 使用特定于云的实例详细信息初始化节点,例如,类型和大小。
- 获取节点的网络地址和主机名。
- 如果节点无响应,请检查云以查看该节点是否已从云中删除。如果已从云中删除该节点,请删除Kubernetes Node对象。
路线控制器
Route控制器负责适当地配置云中的路由,以便Kubernetes集群中不同节点上的容器可以相互通信。路径控制器仅适用于Google Compute Engine群集。
服务控制器
服务控制器负责监听服务创建,更新和删除事件。根据Kubernetes中当前的服务状态,它配置云负载均衡器(如ELB或Google LB)以反映Kubernetes中的服务状态。此外,它还确保云负载平衡器的服务后端是最新的。
PersistentVolumeLabels控制器
PersistentVolumeLabels控制器在创建AWS EBS / GCE PD卷时应用标签。这消除了用户手动设置这些卷上的标签的需要。
这些标签对于pod的计划至关重要,因为这些卷仅限于在它们所在的区域/区域内工作。使用这些卷的任何Pod都需要在同一区域/区域中进行调度。
PersistentVolumeLabels控制器专门为CCM创建; 也就是说,在创建CCM之前它不存在。这样做是为了将Kubernetes API服务器(它是一个许可控制器)中的PV标记逻辑移动到CCM。它不在KCM上运行。
2. Kubelet
节点控制器包含kubelet的依赖于云的功能。在引入CCM之前,kubelet负责使用特定于云的详细信息(如IP地址,区域/区域标签和实例类型信息)初始化节点。CCM的引入已将此初始化操作从kubelet转移到CCM。
在这个新模型中,kubelet初始化一个没有特定于云的信息的节点。但是,它会为新创建的节点添加污点,使节点不可调度,直到CCM使用特定于云的信息初始化节点。然后它消除了这种污点。
3. Kubernetes API服务器
PersistentVolumeLabels控制器将Kubernetes API服务器的依赖于云的功能移动到CCM,如前面部分所述。
插件机制
云控制器管理器使用Go接口允许插入任何云的实现。具体来说,它使用此处定义的CloudProvider接口。
上面突出显示的四个共享控制器的实现,以及一些脚手架以及共享的cloudprovider接口,将保留在Kubernetes核心中。特定于云提供商的实现将在核心之外构建,并实现核心中定义的接口。
有关开发插件的更多信息,请参阅开发Cloud Controller Manager。
授权
本节分解了CCM执行其操作时各种API对象所需的访问权限。
节点控制器
Node控制器仅适用于Node对象。它需要完全访问get,list,create,update,patch,watch和delete Node对象。
V1 /节点:
- Get
- List
- Create
- Update
- Patch
- Watch
- Delete
路线控制器
路由控制器侦听Node对象创建并适当地配置路由。它需要访问Node对象。
V1 /节点:
- Get
服务控制器
服务控制器侦听Service对象创建,更新和删除事件,然后适当地为这些服务配置端点。
要访问服务,它需要列表和监视访问权限。要更新服务,它需要修补和更新访问权限。
要为服务设置端点,需要访问create,list,get,watch和update。
V1 /服务:
- List
- Get
- Watch
- Patch
- Update
PersistentVolumeLabels控制器
PersistentVolumeLabels控制器侦听PersistentVolume(PV)创建事件,然后更新它们。该控制器需要访问以获取和更新PV。
V1 / PersistentVolume:
- Get
- List
- Watch
- Update
其他
CCM核心的实现需要访问以创建事件,并且为了确保安全操作,它需要访问以创建ServiceAccounts。
V1 /事件:
- Create
- Patch
- Update
V1 / ServiceAccount:
- Create
CCM的RBAC ClusterRole如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cloud-controller-manager
rules:
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- '*'
- apiGroups:
- ""
resources:
- nodes/status
verbs:
- patch
- apiGroups:
- ""
resources:
- services
verbs:
- list
- patch
- update
- watch
- apiGroups:
- ""
resources:
- serviceaccounts
verbs:
- create
- apiGroups:
- ""
resources:
- persistentvolumes
verbs:
- get
- list
- update
- watch
- apiGroups:
- ""
resources:
- endpoints
verbs:
- create
- get
- list
- watch
- update
供应商实施
以下云提供商已实施CCM:
群集管理
此处提供了有关配置和运行CCM的完整说明
容器
镜像
您创建Docker镜像并将其推送到仓库,然后在Kubernetes的pod中引用它。
image容器的属性支持与docker命令相同的语法,包括私有仓库和标记。
- 更新镜像
- 用清单构建多架构镜像
- 使用私人仓库
更新镜像
默认拉取策略IfNotPresent会导致Kubelet跳过拉动镜像(如果已存在)。如果您想总是强制Docker拉动,可以执行以下操作之一:
- 将
imagePullPolicy容器设置为Always。 - 省略
imagePullPolicy并使用它:latest作为要使用的镜像的标记。 - 省略
imagePullPolicy要使用的镜像和标记。 - 启用AlwaysPullImages准入控制器。
请注意,您应该避免使用:latest标记,有关详细信息,请参阅配置的最佳实践。
用清单构建多架构图像
Docker CLI现在支持以下命令docker manifest中包含的子命令create,annotate并push。这些命令可用于构建和推送清单。您可以使用docker manifest inspect查看清单。
请在此处查看docker文档,
请参阅我们在构建工具中如何使用它的示例&i=nope&files=&repos=)。
这些命令完全依赖于Docker CLI,并且完全在Docker CLI上实现。您需要编辑$HOME/.docker/config.json和设置experimental密钥,enabled或者只需在调用CLI命令时将DOCKER_CLI_EXPERIMENTAL环境变量设置为enabled。
注意:请使用Docker 18.06或更高版本,以下版本有错误或不支持实验命令行选项。示例会在containerd下导致问题。
如果您在上传陈旧的清单时遇到问题,只需清理旧的清单$HOME/.docker/manifests即可重新开始。
对于Kubernetes,我们通常使用带后缀的镜像-$(ARCH)。为了向后兼容,请生成带有后缀的旧镜像。我们的想法是生成pause具有所有拱形清单的说明镜像,并说出pause-amd64哪些向后兼容旧配置或YAML文件,这些文件可能硬编码带有后缀的镜像。
使用私人仓库
私人仓库管理可能需要密钥才能从中读取图像。凭证可以通过多种方式提供:
- 使用Google Container Registry
- Per-cluster
- 在Google Compute Engine或Google Kubernetes Engine上自动配置
- 所有pod都可以读取项目的私有仓库
- 使用AWS EC2容器仓库(ECR)
- 使用IAM角色和策略来控制对ECR存储库的访问
- 自动刷新ECR登录凭据
- 使用Azure容器仓库(ACR)
- 使用IBM Cloud Container Registry
- 配置节点以验证私有仓库
- 所有pod都可以读取任何已配置的私有仓库
- 需要集群管理员进行节点配置
- 预拉镜像
- 所有pod都可以使用节点上缓存的任何镜像
- 需要root权限才能设置所有节点
- 在Pod上指定ImagePullSecrets
- 只有提供自己密钥的pod才能访问私有仓库
下面更详细地描述每个选项。
使用Google Container Registry
在Google Compute Engine(GCE)上运行时,Kubernetes对Google Container Registry(GCR)提供原生支持。如果您在GCE或Google Kubernetes Engine上运行群集,只需使用完整的镜像名称(例如gcr.io/my_project/image:tag)。
群集中的所有pod都具有此仓库中镜像的读取权限。
kubelet将使用实例的Google服务帐户向GCR进行身份验证。实例上的服务帐户将具有一个 https://www.googleapis.com/auth/devstorage.read_only,因此它可以从项目的GCR中提取,但不能推送。
使用AWS EC2 Container Registry
当节点是AWS EC2实例时,Kubernetes对AWS EC2 Container Registry具有本机支持。
只需ACCOUNT.dkr.ecr.REGION.amazonaws.com/imagename:tag在Pod定义中使用完整的图像名称(例如)。
可以创建pod的群集的所有用户都可以运行使用ECR仓库中任何镜像的pod。
kubelet将获取并定期刷新ECR凭据。它需要以下权限才能执行此操作:
- ecr:GetAuthorizationToken
- ecr:BatchCheckLayerAvailability
- ecr:GetDownloadUrlForLayer
- ecr:GetRepositoryPolicy
- ecr:DescribeRepositories
- ecr:ListImages
- ecr:BatchGetImage
要求:
- 您必须使用kubelet版本
v1.2.0或更新版本。(例如run/usr/bin/kubelet --version=true)。 - 如果您的节点位于区域A中且您的注册表位于不同的区域B中,则需要
v1.3.0更新版本或更新版本。 - ECR必须在您所在的地区提供
故障排除:
- 验证上述所有要求。
us-west-2在工作站上获取$ REGION(例如)凭据。SSH进入主机并使用这些信用卡手动运行Docker。它有用吗?- 验证kubelet是否正在运行
--cloud-provider=aws。 - 检查kubelet日志(例如
journalctl -u kubelet)以获取日志行,例如:plugins.go:56] Registering credential provider: aws-ecr-keyprovider.go:91] Refreshing cache for provider: *aws_credentials.ecrProvider
使用Azure容器仓库(ACR)
使用Azure容器仓库时, 您可以使用管理员用户或服务主体进行身份验证。在任何一种情况下,身份验证都通过标准Docker身份验证完成 这些说明假定使用 azure-cli命令行工具。
您首先需要创建一个仓库并生成凭据,完整的文档可以在Azure容器仓库文档中找到。
创建容器仓库后,您将使用以下凭据登录:
DOCKER_USER:服务主体或管理员用户名DOCKER_PASSWORD:服务主体密码或管理员用户密码DOCKER_REGISTRY_SERVER:${some-registry-name}.azurecr.ioDOCKER_EMAIL:${some-email-address}
填好这些变量后,您可以配置Kubernetes Secret并使用它来部署Pod。
使用IBM Cloud Container Registry
IBM Cloud Container Registry提供了一个多租户私有镜像仓库,您可以使用它来安全地存储和共享Docker镜像。默认情况下,集成的漏洞顾问会扫描私有仓库中的镜像,以检测安全问题和潜在漏洞。IBM Cloud帐户中的用户可以访问您的镜像,也可以创建令牌以授予对仓库命名空间的访问权限。
要安装IBM Cloud Container Registry CLI插件并为镜像创建命名空间,请参阅IBM Cloud Container Registry入门。
您可以使用IBM Cloud Container Registry将容器从IBM Cloud公共镜像和私有镜像部署到defaultIBM Cloud Kubernetes Service集群的命名空间中。要将容器部署到其他名称空间,或使用来自其他IBM Cloud Container Registry区域或IBM Cloud帐户的镜像,请创建Kubernetes imagePullSecret。有关更多信息,请参阅从镜像构建容器。
配置节点以验证私有仓库
注意:如果您在Google Kubernetes Engine上运行,则
.dockercfg每个节点上都会有一个包含Google Container Registry凭据的节点。你不能使用这种方法。
注意:如果您在AWS EC2上运行并且正在使用EC2容器仓库(ECR),则每个节点上的kubelet将管理和更新ECR登录凭据。你不能使用这种方法
注意:如果您可以控制节点配置,则此方法是合适的。它不能可靠地在GCE和任何其他进行自动节点替换的云提供商上运行。
Docker将私有仓库的密钥存储在$HOME/.dockercfg或$HOME/.docker/config.json文件中。如果您将相同的文件放在下面的搜索路径列表中,则kubelet会在拉取镜像时将其用作凭据提供程序。
{--root-dir:-/var/lib/kubelet}/config.json{cwd of kubelet}/config.json${HOME}/.docker/config.json/.docker/config.json{--root-dir:-/var/lib/kubelet}/.dockercfg{cwd of kubelet}/.dockercfg${HOME}/.dockercfg/.dockercfg
注意:您可能必须
HOME=/root在环境文件中明确设置kubelet。
以下是配置节点以使用私有仓库的建议步骤。在此示例中,在桌面/笔记本电脑上运行这些:
docker login [server]针对要使用的每组凭据运行。这更新$HOME/.docker/config.json。$HOME/.docker/config.json在编辑器中查看以确保它仅包含您要使用的凭据。- 获取节点列表,例如:
- 如果你想要这些名字:
nodes=$(kubectl get nodes -o jsonpath='{range.items[*].metadata}{.name} {end}') - 如果你想获得IP:
nodes=$(kubectl get nodes -o jsonpath='{range .items[*].status.addresses[?(@.type=="ExternalIP")]}{.address} {end}')
- 将本地复制
.docker/config.json到上面的搜索路径列表之一。
- 例如:
for n in $nodes; do scp ~/.docker/config.json root@$n:/var/lib/kubelet/config.json; done
通过创建使用私有镜像的pod进行验证,例如:1
2
3
4
5
6
7
8
9
10
11
12
13kubectl create -f - <<EOF
apiVersion: v1
kind: Pod
metadata:
name: private-image-test-1
spec:
containers:
- name: uses-private-image
image: $PRIVATE_IMAGE_NAME
imagePullPolicy: Always
command: [ "echo", "SUCCESS" ]
EOF
pod/private-image-test-1 created
如果一切正常,那么过了一会儿,你应该看到:1
2kubectl logs private-image-test-1
SUCCESS
如果失败了,那么你会看到:1
2kubectl describe pods/private-image-test-1 | grep "Failed"
Fri, 26 Jun 2015 15:36:13 -0700 Fri, 26 Jun 2015 15:39:13 -0700 19 {kubelet node-i2hq} spec.containers{uses-private-image} failed Failed to pull image "user/privaterepo:v1": Error: image user/privaterepo:v1 not found
您必须确保群集中的所有节点都具有相同的节点.docker/config.json。否则,pod将在某些节点上运行,而无法在其他节点上运行。例如,如果使用节点自动缩放,则每个实例模板都需要包含.docker/config.json或装载包含它的驱动器。
将私有仓库项添加到任何私有仓库中后,所有pod都将具有对镜像的读访问权限.docker/config.json。
预拉图像
注意:如果您在Google Kubernetes Engine上运行,则.dockercfg每个节点上都会有一个包含Google Container Registry凭据的节点。你不能使用这种方法。
注意:如果您可以控制节点配置,则此方法是合适的。它不能可靠地在GCE和任何其他进行自动节点替换的云提供商上运行。
默认情况下,kubelet将尝试从指定的仓库中提取每个镜像。但是,如果imagePullPolicy容器的属性设置为IfNotPresent或Never,则使用本地镜像(分别优先或排他)。
如果您希望依赖预先提取的镜像作为仓库身份验证的替代,则必须确保群集中的所有节点都具有相同的预拉镜像。
这可以用于预加载某些镜像以提高速度,或者作为对私有仓库进行身份验证的替代方法。
所有pod都可以读取任何预拉镜像。
在Pod上指定ImagePullSecrets
注意:此方法目前是Google Kubernetes Engine,GCE以及自动创建节点的任何云提供商的推荐方法。
Kubernetes支持在pod上指定仓库项。
使用Docker配置创建机密
运行以下命令,替换相应的大写值:1
2kubectl create secret docker-registry myregistrykey --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
secret/myregistrykey created.
如果需要访问多个仓库,则可以为每个仓库创建一个秘密。 在为Pods提取镜像时,Kubelet会将任何内容合并imagePullSecrets为一个虚拟内容.docker/config.json。
Pod只能在自己的命名空间中引用镜像拉取秘密,因此每个命名空间需要执行一次此过程。
绕过kubectl会产生秘密
如果由于某种原因,您需要单个项目中的多个项目.docker/config.json或需要上述命令未给出的控制,那么您可以使用json或yaml创建一个秘密。
务必:
- 设置数据项的名称
.dockerconfigjson - base64编码docker文件并粘贴该字符串,不间断作为字段的值
data[".dockerconfigjson"] - 设置
type为kubernetes.io/dockerconfigjson
例:1
2
3
4
5
6
7
8apiVersion: v1
kind: Secret
metadata:
name: myregistrykey
namespace: awesomeapps
data:
.dockerconfigjson: UmVhbGx5IHJlYWxseSByZWVlZWVlZWVlZWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWFhYWxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGxsbGx5eXl5eXl5eXl5eXl5eXl5eXl5eSBsbGxsbGxsbGxsbGxsbG9vb29vb29vb29vb29vb29vb29vb29vb29vb25ubm5ubm5ubm5ubm5ubm5ubm5ubm5ubmdnZ2dnZ2dnZ2dnZ2dnZ2dnZ2cgYXV0aCBrZXlzCg==
type: kubernetes.io/dockerconfigjson
如果收到错误消息error: no objects passed to create,则可能表示base64编码的字符串无效。如果收到类似的错误消息Secret "myregistrykey" is invalid: data[.dockerconfigjson]: invalid value ...,则表示数据已成功取消base64编码,但无法解析为.docker/config.json文件。
参考Pod上的imagePullSecrets
现在,您可以通过向imagePullSecrets pod定义添加一个部分来创建引用该秘密的pod。1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Pod
metadata:
name: foo
namespace: awesomeapps
spec:
containers:
- name: foo
image: janedoe/awesomeapp:v1
imagePullSecrets:
- name: myregistrykey
需要对使用私有仓库的每个pod执行此操作。
但是,可以通过在serviceAccount资源中设置imagePullSecrets来自动设置此字段。检查将ImagePullSecrets添加到服务帐户以获取详细说明。
您可以将其与每个节点结合使用.docker/config.json。凭证将被合并。这种方法适用于Google Kubernetes Engine。
用例
有许多配置私有仓库的解决方案。以下是一些常见用例和建议的解决方案。
- 群集仅运行非专有(例如开源)镜像。无需隐藏镜像。
- 在Docker hub上使用公共镜像。
- 无需配置。
- 在GCE / Google Kubernetes Engine上,自动使用本地镜像来提高速度和可用性。
- 群集运行一些专有镜像,这些镜像像应隐藏给公司外部的人员,但对所有群集用户可见。
- 使用托管的私有Docker仓库。
- 它可能托管在Docker Hub或其他地方。
- 如上所述,在每个节点上手动配置
.docker / config.json。
- 或者,使用开放读取访问权限在防火墙后面运行内部私有仓库。
- 不需要Kubernetes配置。
- 或者,在使用GCE / Google Kubernetes Engine时,请使用该项目的Google Container Registry。
- 与集群自动调节相比,它可以比手动节点配置更好地工作。
- 或者,在更改节点配置不方便的群集上,请使用
imagePullSecrets。
- 具有专有镜像的集群,其中一些需要更严格的访问控制。
- 确保AlwaysPullImages准入控制器处于活动状态。否则,所有Pod都可能访问所有镜像。
- 将敏感数据移动到“秘密”资源中,而不是将其打包在镜像中。
- 一个多租户群集,每个租户都需要拥有私有仓库。
- 确保AlwaysPullImages准入控制器处于活动状态。否则,所有租户的所有Pod都可能访问所有图像。
- 运行需要授权的私有仓库。
- 为每个租户生成仓库凭据,保密,并为每个租户命名空间填充机密。
- 租户将这个秘密添加到每个命名空间的imagePullSecrets。
容器环境变量
此页面描述Container环境中Container可用的资源。
容器环境
Kubernetes Container环境为容器提供了几个重要资源:
- 文件系统,是镜像和一个或多个卷的组合。
- 有关Container本身的信息。
- 有关群集中其他对象的信息。
容器信息
Container 的主机名是运行Container的Pod的名称。它可以通过 libc中的hostname命令或 gethostname函数调用获得。
Pod名称和命名空间可通过向下API作为环境变量使用 。
Pod定义中的用户定义环境变量也可用于Container,Docker镜像中静态指定的任何环境变量也是如此。
群集信息
创建Container时运行的所有服务的列表可作为环境变量用于该Container。这些环境变量与Docker链接的语法相匹配。
对于名为foo的映射到名为bar的Container 的服务,定义了以下变量:1
2FOO_SERVICE_HOST=<the host the service is running on>
FOO_SERVICE_PORT=<the port the service is running on>
服务具有专用IP地址,如果启用了DNS插件,则可通过DNS使用Container 。
运行时类
特征状态: Kubernetes v1.12
该页面描述了RuntimeClass资源和运行时选择机制。
此功能目前处于alpha状态,意思是:
版本名称包含alpha(例如v1alpha1)。
可能是马车。启用该功能可能会暴露错误。默认情况下禁用。
可随时删除对功能的支持,恕不另行通知。
API可能会在以后的软件版本中以不兼容的方式更改,恕不另行通知。
由于错误风险增加和缺乏长期支持,建议仅在短期测试集群中使用。
运行时类
RuntimeClass是一个alpha功能,用于选择用于运行pod容器的容器运行时配置。
建立
作为早期的alpha功能,必须采取一些额外的设置步骤才能使用RuntimeClass功能:
- 启用RuntimeClass功能门(在apiservers&kubelets上,需要1.12+版本)
- 安装RuntimeClass CRD
- 在节点上配置CRI实现(取决于运行时)
- 创建相应的RuntimeClass资源
1.启用RuntimeClass feature gate
有关启用feature gates的说明,请参见feature gates。必须在apiservers和kubelet上启用RuntimeClass功能门。
2.安装RuntimeClass CRD
RuntimeClass CustomResourceDefinition(CRD)可以在Kubernetes git repo的addons目录中找到:kubernetes / cluster / addons / runtimeclass / runtimeclass_crd.yaml
安装CRD kubectl apply -f runtimeclass_crd.yaml。
3.在节点上配置CRI实现
使用RuntimeClass进行选择的配置取决于CRI实现。有关如何配置的信息,请参阅CRI实现的相应文档。由于这是一个alpha功能,并非所有CRI都支持多个RuntimeClasses。
注意: RuntimeClass当前假定整个集群中的同类节点配置(这意味着所有节点的配置方式与容器运行时相同)。任何异构性(变化的配置)必须通过调度功能独立于RuntimeClass进行管理(请参阅将Pod分配给节点)。
配置具有相应的RuntimeHandler名称,由RuntimeClass引用。RuntimeHandler必须是有效的DNS 1123子域(字母数字+ -和.字符)。
4.创建相应的RuntimeClass资源
步骤3中的配置设置应各自具有关联的RuntimeHandler名称,用于标识配置。对于每个RuntimeHandler(以及可选的空””处理程序),创建相应的RuntimeClass对象。
RuntimeClass资源当前只有2个重要字段:RuntimeClass name(metadata.name)和RuntimeHandler(spec.runtimeHandler)。对象定义如下所示:1
2
3
4
5
6
7apiVersion: node.k8s.io/v1alpha1 # RuntimeClass is defined in the node.k8s.io API group
kind: RuntimeClass
metadata:
name: myclass # The name the RuntimeClass will be referenced by
# RuntimeClass is a non-namespaced resource
spec:
runtimeHandler: myconfiguration # The name of the corresponding CRI configuration
注意:建议将RuntimeClass写入操作(create / update / patch / delete)限制为群集管理员。这通常是默认值。有关详细信息,请参阅授权概述。
用法
为集群配置RuntimeClasses后,使用它们非常简单。runtimeClassName在Pod规范中指定a 。例如:1
2
3
4
5
6
7apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
runtimeClassName: myclass
这将指示Kubelet使用命名的RuntimeClass来运行此pod。如果命名的RuntimeClass不存在,或者CRI无法运行相应的处理程序,则pod将进入 Failed终端阶段。查找错误消息的相应事件。
如果未runtimeClassName指定,则将使用默认的RuntimeHandler,这相当于禁用RuntimeClass功能时的行为。
容器生命周期钩子
此页面描述了kubelet管理的容器如何使用Container生命周期钩子框架来运行在管理生命周期中由事件触发的代码。
- 概观
- 集装箱挂钩
概观
类似于许多具有组件生命周期钩子的编程语言框架,例如Angular,Kubernetes为Containers提供了生命周期钩子。钩子使Container能够了解其管理生命周期中的事件,并在执行相应的生命周期钩子时运行在处理程序中实现的代码。
容器钩子
有两个暴露给容器的钩子:
PostStart
在创建容器后立即执行此挂钩。但是,无法保证挂钩将在容器ENTRYPOINT之前执行。没有参数传递给处理程序。
PreStop
在容器终止之前立即调用此挂钩。它是阻塞的,意味着它是同步的,所以它必须在删除容器的调用之前完成。没有参数传递给处理程序。
终止行为的更详细描述可以在终端中找到 。
钩子处理程序实现
容器可以通过实现和注册该钩子的处理程序来访问钩子。可以为Container实现两种类型的钩子处理程序:
- Exec - 执行特定命令,例如
pre-stop.sh,在Container的cgroups和名称空间内。命令消耗的资源将根据Container计算。 - HTTP - 对Container上的特定端点执行HTTP请求。
钩子处理程序执行
调用Container生命周期管理挂钩时,Kubernetes管理系统会在为该挂钩注册的Container中执行处理程序。
钩子处理程序调用在包含Container的Pod的上下文中是同步的。这意味着对于一个PostStart钩子,Container ENTRYPOINT和钩子异步发射。但是,如果挂钩运行或挂起太长时间,则Container无法达到某种running状态。
PreStop钩子的行为类似。如果钩子在执行期间挂起,则Pod阶段将保持Terminating状态并在terminationGracePeriodSecondspod结束后被杀死。如果一个 PostStart或PreStophook失败,则会终止Container。
用户应使其钩子处理程序尽可能轻量级。但是,有些情况下,长时间运行的命令是有意义的,例如在停止Container之前保存状态。
挂钩送货保证
钩子传递至少是一次,这意味着可以为任何给定事件多次调用钩子,例如for PostStart或PreStop。由钩子实现来正确处理这个问题。
通常,只进行单次交付。例如,如果HTTP挂钩接收器关闭且无法获取流量,则不会尝试重新发送。然而,在一些罕见的情况下,可能会发生双重递送。例如,如果一个kubelet在发送一个钩子的过程中重新启动,那么在该kubelet重新启动后可能会重新发送一个钩子。
调试Hook处理程序
在Pod事件中不公开Hook处理程序的日志。如果处理程序由于某种原因失败,它会广播一个事件。因为PostStart,这是FailedPostStartHook事件,因为PreStop这是FailedPreStopHook事件。您可以通过运行来查看这些事件kubectl describe pod <pod_name>。以下是运行此命令的一些事件输出示例:1
2
3
4
5
6
7
8
9
10
11
12Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {default-scheduler } Normal Scheduled Successfully assigned test-1730497541-cq1d2 to gke-test-cluster-default-pool-a07e5d30-siqd
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulling pulling image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Created Created container with docker id 5c6a256a2567; Security:[seccomp=unconfined]
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Pulled Successfully pulled image "test:1.0"
1m 1m 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Started Started container with docker id 5c6a256a2567
38s 38s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 5c6a256a2567: PostStart handler: Error executing in Docker Container: 1
37s 37s 1 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Normal Killing Killing container with docker id 8df9fdfd7054: PostStart handler: Error executing in Docker Container: 1
38s 37s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "main" with RunContainerError: "PostStart handler: Error executing in Docker Container: 1"
1m 22s 2 {kubelet gke-test-cluster-default-pool-a07e5d30-siqd} spec.containers{main} Warning FailedPostStartHook
Workloads
Pods
Pod概述
此页面概述Pod了Kubernetes对象模型中最小的可部署对象。
- 了解Pods
- 使用Pods
- Pod模板
了解Pods
一个pod是在创建或部署Kubernetes对象模型Kubernetes-最小最简单的单元的基本构建块。Pod表示群集上正在运行的进程。
Pod封装了一个应用程序容器(或者,在某些情况下,多个容器),存储资源,一个唯一的网络IP以及控制容器应该如何运行的选项。Pod表示部署单元:Kubernetes中的单个应用程序实例,可能包含单个容器或少量紧密耦合且共享资源的容器。
Docker是Kubernetes Pod中最常用的容器运行时,但Pods也支持其他容器运行时。
Kubernetes集群中的Pod可以以两种主要方式使用:
- 运行单个容器的Pod。“one-container-per-Pod”模型是最常见的Kubernetes用例; 在这种情况下,您可以将Pod视为单个容器的包装,而Kubernetes直接管理Pod而不是容器。
- 运行多个需要协同工作的容器的Pod。Pod可以封装由多个共址容器组成的应用程序,这些容器紧密耦合并需要共享资源。这些共处一地的容器可能形成一个统一的服务单元 - 一个容器从共享卷向公众提供文件,而一个单独的“sidecar”容器刷新或更新这些文件。Pod将这些容器和存储资源作为单个可管理实体包装在一起。
该Kubernetes博客对pod用例一些额外的信息。有关更多信息,请参阅:
每个Pod都用于运行给定应用程序的单个实例。如果要水平扩展应用程序(例如,运行多个实例),则应使用多个Pod,每个实例一个。在Kubernetes中,这通常被称为复制。复制Pod通常由称为Controller的抽象创建和管理。有关更多信息,请参阅Pod和控制器。
Pod如何管理多个容器
Pod旨在支持多个协作流程(作为容器),形成一个有凝聚力的服务单元。Pod中的容器自动位于群集中的同一物理或虚拟机上,并共同调度。容器可以共享资源和依赖关系,彼此通信,并协调它们何时以及如何终止。
请注意,在单个Pod中对多个共存和共同管理的容器进行分组是一个相对高级的用例。您应该仅在容器紧密耦合的特定实例中使用此模式。例如,您可能有一个容器充当共享卷中文件的Web服务器,以及一个单独的“sidecar”容器,用于从远程源更新这些文件,如下图所示:
pod diagram
Pod为其组成容器提供两种共享资源:网络和存储。
联网
每个Pod都分配有唯一的IP地址。Pod中的每个容器都共享网络命名空间,包括IP地址和网络端口。Pod内的容器可以使用相互通信localhost。当Pod中的容器与Pod 外部的实体通信时,它们必须协调它们如何使用共享网络资源(例如端口)。
存储
Pod可以指定一组共享存储卷。Pod中的所有容器都可以访问共享卷,允许这些容器共享数据。如果需要重新启动其中一个容器,则卷还允许Pod中的持久数据存活。见卷上Kubernetes如何实现一个pod里的共享存储更多的信息。
使用Pods
你很少直接在Kubernetes - 甚至是单身Pod中创建单独的Pod。这是因为Pods被设计为相对短暂的一次性实体。当创建Pod(由您直接创建或由Controller间接创建)时,它将被安排在群集中的节点上运行。Pod保留在该节点上,直到进程终止,pod对象被删除,pod 因资源不足而被驱逐,或者Node失败。
注意:不应将重新启动Pod重新启动Pod中的容器。Pod本身不会运行,但是容器运行的环境会持续存在,直到删除为止。
pod本身不能自我修复。如果将Pod调度到失败的节点,或者调度操作本身失败,则删除Pod; 同样,由于缺乏资源或节点维护,Pod将无法在驱逐中存活。Kubernetes使用更高级别的抽象,称为Controller,它处理管理相对可处理的Pod实例的工作。因此,虽然可以直接使用Pod,但在Kubernetes中使用Controller管理pod更为常见。见pod和控制器上Kubernetes如何使用控制器来实现pod缩放和愈合的更多信息。
pod和控制器
Controller可以为您创建和管理多个Pod,处理复制和部署,并在集群范围内提供自我修复功能。例如,如果节点发生故障,Controller可能会通过在不同节点上安排相同的替换来自动替换Pod。
包含一个或多个pod的控制器的一些示例包括:
通常,控制器使用您提供的Pod模板来创建它负责的Pod。
Pod模板
Pod模板是pod规范,包含在其他对象中,例如 Replication Controllers,Jobs和 DaemonSets。控制器使用Pod模板制作实际的pod。下面的示例是Pod的简单清单,其中包含一个打印消息的容器。1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo Hello Kubernetes! && sleep 3600']
pod模板不是指定所有副本的当前所需状态,而是像cookie 切割机。切割 cookie后,cookie与切割机无关。没有“量子纠缠”。对模板的后续更改甚至切换到新模板对已创建的pod没有直接影响。类似地,随后可以直接更新由复制控制器创建的pod。这与pod有意对比,pod确实指定了属于pod的所有容器的当前所需状态。这种方法从根本上简化了系统语义并增加了原语的灵活性。
Pods
pods是可以创建和管理Kubernetes计算的最小可部署单元。
- 什么是Pod?
- pod的动机
- pod的使用
- 考虑的替代方案
- pod的耐久性(或缺乏)
- 终止pod
- pod容器的特权模式
- API对象
什么是Pod?
一个pod(如在whales或pea pod中)是一组一个或多个容器(如Docker容器),具有共享存储/网络,以及如何运行容器的规范。pod的内容始终位于同一位置并共同调度,并在共享上下文中运行。pod模拟特定于应用程序的“逻辑主机” - 它包含一个或多个相对紧密耦合的应用程序容器 - 在预容器世界中,在同一物理或虚拟机上执行意味着在同一逻辑主机上执行。
虽然Kubernetes支持的容器运行时间多于Docker,但Docker是最常见的运行时,它有助于用Docker术语描述pod。
pod的共享上下文是一组Linux命名空间,cgroup,以及可能的隔离方面 - 与隔离Docker容器相同的东西。在pod的上下文中,各个应用程序可能会应用进一步的子隔离。
Pod中的容器共享IP地址和端口空间,并且可以通过它们找到彼此localhost。他们还可以使用标准的进程间通信(如SystemV信号量或POSIX共享内存)相互通信。不同pod中的容器具有不同的IP地址,并且在没有特殊配置的情况下无法通过IPC进行通信 。这些容器通常通过Pod IP地址相互通信。
pod中的应用程序还可以访问共享卷,共享卷被定义为pod的一部分,可以安装到每个应用程序的文件系统中。
就Docker构造而言,pod被建模为一组具有共享命名空间和共享卷的Docker容器 。
与单个应用程序容器一样,pod被认为是相对短暂的(而不是持久的)实体。正如在pod的生命周期中所讨论的,创建pod,分配唯一ID(UID),并调度到它们保留的节点,直到终止(根据重启策略)或删除。如果节点终止,则在超时期限之后,将调度计划到该节点的Pod进行删除。给定的pod(由UID定义)不会“重新安排”到新节点; 相反,它可以被相同的pod替换,如果需要,甚至可以使用相同的名称,但是使用新的UID(有关更多详细信息,请参阅复制控制器)。
当某些东西被认为具有与容量相同的生命周期时,例如卷,这意味着只要该容器(具有该UID)存在就存在。如果由于任何原因删除了该pod,即使创建了相同的替换,相关的东西(例如卷)也会被销毁并重新创建。
pod图
一个多容器窗格,包含文件提取程序和Web服务器,该服务器使用持久卷在容器之间共享存储。
pod的动机
管理
Pod是多个合作过程模式的模型,形成了一个有凝聚力的服务单元。它们通过提供比其组成应用程序集更高级别的抽象来简化应用程序部署和管理。Pod用作部署,水平扩展和复制的单元。对容器中的容器自动处理共置(共同调度),共享命运(例如终止),协调复制,资源共享和依赖关系管理。
资源共享和沟通
Pod可以实现其成员之间的数据共享和通信。
pod中的应用程序都使用相同的网络命名空间(相同的IP和端口空间),因此可以相互“找到”并使用它们进行通信localhost。因此,pod中的应用程序必须协调它们对端口的使用。每个pod在平面共享网络空间中具有IP地址,该网络空间与网络上的其他物理计算机和pod完全通信。
主机名设置为pod中应用程序容器的pod名称。关于网络的更多细节。
除了定义在pod中运行的应用程序容器之外,pod还指定了一组共享存储卷。卷使数据能够在容器重新启动后继续存在,并在容器内的应用程序之间共享。
pod的使用
Pod可用于托管垂直集成的应用程序堆栈(例如LAMP),但其主要动机是支持共址,共同管理的帮助程序,例如:
- 内容管理系统,文件和数据加载器,本地缓存管理器等。
- 日志和检查点备份,压缩,旋转,快照等
- 数据变更观察者,日志零售商,日志和监控适配器,活动发布者等。
- 代理,网桥和适配器
- 控制器,管理器,配置器和更新器
通常,单个pod不用于运行同一应用程序的多个实例。
有关更长的说明,请参阅分布式系统工具包:复合容器的模式。
考虑的替代方案
为什么不在一个(Docker)容器中运行多个程序?
- 透明度。使基础架构内的容器对基础架构可见,使基础架构能够为这些容器提供服务,例如进程管理和资源监视。这为用户提供了许多便利。
- 解耦软件依赖关系。各个容器可以独立地进行版本化,重建和重新部署。Kubernetes甚至有一天可能会支持单个容器的实时更新。
- 便于使用。用户无需运行自己的流程管理器,担心信号和退出代码传播等。
- 效率。由于基础设施承担更多责任,因此集装箱的重量可以更轻。
为什么不支持基于亲和力的容器协同调度?
这种方法可以提供协同定位,但不会提供pod的大部分好处,例如资源共享,IPC,保证命运共享和简化管理。
pod的耐久性(或缺乏)
pod不应被视为耐用实体。它们将无法在调度故障,节点故障或其他驱逐(例如由于缺乏资源)或节点维护的情况下存活。
通常,用户不需要直接创建pod。他们应该几乎总是使用控制器,即使是singletons,例如, 部署。控制器提供集群范围的自我修复,以及复制和部署管理。像StatefulSet这样的控制器 也可以为有状态的pod提供支持。
使用集合API作为主要的面向用户的原语在集群调度系统中相对常见,包括Borg,Marathon,Aurora和Tupperware。
Pod作为基元公开,以便于:
- 调度程序和控制器可插拔性
- 支持pod级操作,无需通过控制器API“代理”它们
- pod生命周期与控制器生命周期的解耦,例如引导
- 控制器和服务的分离 - 端点控制器只是监视pod
- 具有集群级功能的Kubelet级功能的清晰组合 - Kubelet实际上是“pod控制器”
- 高可用性应用程序,它们将期望在终止之前更换pod,并且肯定在删除之前,例如在计划驱逐或图像预取的情况下。
终止pod
因为pod表示集群中节点上的正在运行的进程,所以允许这些进程在不再需要时优雅地终止(与使用KILL信号猛烈杀死并且没有机会清理)非常重要。用户应该能够请求删除并知道进程何时终止,但也能够确保删除最终完成。当用户请求删除pod时,系统会在允许pod强制终止之前记录预期的宽限期,并将TERM信号发送到每个容器中的主进程。宽限期到期后,KILL信号将发送到这些进程,然后从API服务器中删除该pod。如果在等待进程终止时重新启动Kubelet或容器管理器,
一个示例流程:
- 用户发送删除Pod的命令,默认宽限期(30秒)
- API服务器中的Pod随着时间的推移而更新,其中Pod被视为“死”以及宽限期。
- 在客户端命令中列出时,Pod显示为“终止”
- (与3同时)当Kubelet看到Pod已被标记为终止,因为已经设置了2中的时间,它开始了pod关闭过程。
- 如果其中一个Pod的容器定义了一个preStop挂钩,则会在容器内部调用它。如果在
preStop宽限期到期后钩子仍在运行,则以小(2秒)延长的宽限期调用步骤2。 - 容器被发送TERM信号。请注意,并非Pod中的所有容器都会同时收到TERM信号,并且
preStop如果它们关闭的顺序很重要,则每个容器都需要一个钩子。
- 如果其中一个Pod的容器定义了一个preStop挂钩,则会在容器内部调用它。如果在
- (与3同时)Pod从端点列表中删除以进行维护,并且不再被视为复制控制器的运行pod集的一部分。缓慢关闭的窗格无法继续提供流量,因为负载平衡器(如服务代理)会将其从旋转中移除。
- 当宽限期到期时,仍然在Pod中运行的任何进程都将被SIGKILL杀死。
- Kubelet将通过设置宽限期0(立即删除)完成删除API服务器上的Pod。Pod从API中消失,不再从客户端可见。
默认情况下,所有删除在30秒内都是正常的。该kubectl delete命令支持--grace-period=<seconds>允许用户覆盖默认值并指定其自己的值的选项。值0force删除 pod。在kubectl版本> = 1.5时,必须指定一个额外的标志--force一起--grace-period=0,以执行力的缺失。
强制删除pod
强制删除pod被定义为立即从群集状态和etcd删除pod。当执行强制删除时,许可证持有者不会等待来自kubelet的确认该pod已在其运行的节点上终止。它会立即删除API中的pod,以便可以使用相同的名称创建新的pod。在节点上,设置为立即终止的pod在被强制终止之前仍将被给予一个小的宽限期。
强制删除可能对某些pod有潜在危险,应谨慎执行。如果是StatefulSet pod,请参阅任务文档以从StatefulSet中删除 Pod 。
pod容器的特权模式
从Kubernetes v1.1开始,pod中的任何容器都可以使用容器规范中的privileged标志启用特权模式SecurityContext。这对于想要使用Linux功能(如操作网络堆栈和访问设备)的容器非常有用。容器内的进程获得与容器外部进程可用的几乎相同的权限。使用特权模式,将网络和卷插件编写为不需要编译到kubelet的独立窗格应该更容易。
如果主服务器正在运行Kubernetes v1.1或更高版本,并且节点运行的版本低于v1.1,那么api-server将接受新的特权pod,但不会启动。他们将处于待决状态。如果用户呼叫kubectl describe pod FooPodName,用户可以查看pod处于暂挂状态的原因。describe命令输出中的events表将说:1
Error validating pod "FooPodName"."FooPodNamespace" from api, ignoring: spec.containers[0].securityContext.privileged: forbidden '<*>(0xc2089d3248)true'
如果主服务器运行的版本低于v1.1,则无法创建特权pod。如果用户尝试创建具有特权容器的pod,则用户将收到以下错误:1
The Pod "FooPodName" is invalid. spec.containers[0].securityContext.privileged: forbidden '<*>(0xc20b222db0)true'
API对象
Pod是Kubernetes REST API中的顶级资源。有关API对象的更多详细信息,请参阅: Pod API对象。
Pod生命周期
该页面描述了Pod的生命周期。
- Pod阶段
- Pod条件
- 容器探针
- Pod和Container状态
- Pod准备gate
- 重启政策
- Pod寿命
- 例子
Pod阶段
Pod的status字段是 PodStatus 对象,它有一个phase字段。
Pod的阶段是Pod在其生命周期中的简单,高级摘要。该阶段不是对Container或Pod状态的全面观察汇总,也不是一个综合状态机。
Pod阶段值的数量和含义受到严密保护。除了这里记录的内容之外,没有任何关于具有给定phase值的Pod的假设。
以下是可能的值phase:
| 值 | 描述 |
|---|---|
Pending |
Pod已被Kubernetes系统接受,但尚未创建一个或多个Container图像。这包括计划之前的时间以及通过网络下载图像所花费的时间,这可能需要一段时间。 |
Running |
Pod已绑定到节点,并且已创建所有Container。至少有一个Container仍在运行,或者正在启动或重新启动。 |
Succeeded |
Pod中的所有容器都已成功终止,并且不会重新启动。 |
Failed |
Pod中的所有容器都已终止,并且至少有一个Container已终止失败。也就是说,Container要么退出非零状态,要么被系统终止。 |
Unknown |
由于某种原因,无法获得Pod的状态,这通常是由于与Pod的主机通信时出错。 |
Pod条件
Pod有一个PodStatus,它有一个PodConditions数组, Pod已经或没有通过它。PodCondition数组的每个元素都有六个可能的字段:
- 该
lastProbeTime字段提供上次探测Pod条件的时间戳。 - 该
lastTransitionTime字段提供Pod最后从一个状态转换到另一个状态的时间戳。 - 该
message字段是人类可读的消息,指示有关转换的详细信息。 - 该
reason字段是该条件最后一次转换的唯一,单字,CamelCase原因。 - 该
status字段是一个字符串,可能的值为“True”,“False”和“Unknown”。 - 该
type字段是一个包含以下可能值的字符串:PodScheduled:Pod已被安排到一个节点;Ready:Pod可以提供请求,应该添加到所有匹配服务的负载平衡池中;Initialized:所有init容器 都已成功启动;Unschedulable:调度程序现在无法调度Pod,例如由于缺少资源或其他限制;ContainersReady:Pod中的所有容器都已准备就绪。
容器探针
一个探头是通过周期性地执行的诊断kubelet 上的容器。为了执行诊断,kubelet调用Container实现的 Handler。有三种类型的处理程序:
- ExecAction:在Container内执行指定的命令。如果命令以状态代码0退出,则认为诊断成功。
- TCPSocketAction:对指定端口上的Container的IP地址执行TCP检查。如果端口打开,则诊断被认为是成功的。
- HTTPGetAction:对指定端口和路径上的Container的IP地址执行HTTP Get请求。如果响应的状态代码大于或等于200且小于400,则认为诊断成功。
每个探针都有三个结果之一:
- 成功:Container通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不应采取任何措施。
在运行容器时,kubelet可以选择性地执行和响应两种探测器:
livenessProbe:指示Container是否正在运行。如果活动探测失败,则kubelet会杀死Container,并且Container将受其重启策略的约束。如果Container未提供活动探测,则默认状态为Success。readinessProbe:指示Container是否已准备好为请求提供服务。如果准备就绪探测失败,则端点控制器会从与Pod匹配的所有服务的端点中删除Pod的IP地址。初始延迟之前的默认准备状态是Failure。如果Container未提供就绪探测,则默认状态为Success。
什么时候应该使用活力或准备探针?
如果您的Container中的进程在遇到问题或变得不健康时能够自行崩溃,则您不一定需要活动探测器; kubelet将根据Pod的内容自动执行正确的操作restartPolicy。
如果您希望在探测失败时杀死并重新启动Container,则指定活动探测,并指定restartPolicyAlways或OnFailure。
如果您只想在探测成功时开始向Pod发送流量,请指定准备探测。在这种情况下,准备情况探测可能与活动探测相同,但规范中存在准备探测意味着Pod将在不接收任何流量的情况下启动,并且仅在探测开始成功后才开始接收流量。
如果Container需要在启动期间处理大型数据,配置文件或迁移,请指定就绪性探针。
如果您希望Container能够自行维护,您可以指定一个就绪探针,用于检查特定于就绪状态的端点,该端点与活动探针不同。
请注意,如果您只想在删除Pod时排除请求,则不一定需要准备探测; 在删除时,无论准备情况探测是否存在,Pod都会自动将其置于未准备状态。Pod在等待Pod中的容器停止时仍处于未准备状态。
有关如何设置活动或准备情况探测的详细信息,请参阅 配置活动和准备探测。
Pod和Container状态
有关Pod容器状态的详细信息,请参阅 PodStatus 和 ContainerStatus。请注意,报告为Pod状态的信息取决于当前的 ContainerState。
Pod准备gate
特征状态: Kubernetes v1.12
此功能目前处于测试状态
为了通过注入额外的反馈或信号来增加Pod准备的可扩展性PodStatus,Kubernetes 1.11引入了一个名为Pod ready ++的功能。您可以使用新的字段ReadinessGate中PodSpec指定波德准备进行评估附加条件。如果Kubernetes在status.conditionsPod 的字段中找不到这样的条件,则条件的状态默认为“ False”。以下是一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19Kind: Pod
...
spec:
readinessGates:
- conditionType: "www.example.com/feature-1"
status:
conditions:
- type: Ready # this is a builtin PodCondition
status: "True"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
- type: "www.example.com/feature-1" # an extra PodCondition
status: "False"
lastProbeTime: null
lastTransitionTime: 2018-01-01T00:00:00Z
containerStatuses:
- containerID: docker://abcd...
ready: true
...
新Pod条件必须符合Kubernetes 标签密钥格式。由于该kubectl patch命令仍然不支持修补对象状态,因此必须PATCH使用其中一个KubeClient库通过操作注入新的Pod条件。
随着新Pod条件的引入,只有 当以下两个语句都成立时,才会评估Pod是否就绪:
- Pod中的所有容器都已准备就绪。
- 指定的所有条件
ReadinessGates均为“True”。
为了便于对Pod准备评估进行此更改,ContainersReady引入了一个新的Pod条件 来捕获旧的Pod Ready条件。
在K8s 1.11中,作为alpha功能,必须通过将PodReadinessGates 功能门设置 为true 来明确启用“Pod Ready ++”功能。
在K8s 1.12中,默认情况下启用该功能。
重启政策
PodSpec的restartPolicy字段可能包含Always,OnFailure和Never。默认值为Always。 restartPolicy适用于Pod中的所有容器。restartPolicy仅指由同一节点上的kubelet重新启动Container。由kubelet重新启动的已退出容器将以指数退避延迟(10秒,20秒,40秒……)重新启动,上限为五分钟,并在成功执行十分钟后重置。正如Pods文档中所讨论的 ,一旦绑定到节点,Pod将永远不会被反弹到另一个节点。
Pod寿命
一般来说,pod不会消失,直到有人摧毁它们。这可能是人或控制者。此规则的唯一例外是具有phase成功或失败超过一定持续时间(由terminated-pod-gc-thresholdmaster确定)的Pod将过期并自动销毁。
有三种控制器可供选择:
- 使用Job for Pods预期终止,例如批量计算。作业仅适用于
restartPolicy等于OnFailure或Never的Pod。 - 对不希望终止的Pod(例如,Web服务器)使用ReplicationController, ReplicaSet或 Deployment。ReplicationControllers仅适用于具有
restartPolicyAlways的Pod。 - 使用需要为每台计算机运行一个的Pod的DaemonSet,因为它们提供特定于计算机的系统服务。
所有三种类型的控制器都包含PodTemplate。建议创建适当的控制器并让它创建Pod,而不是自己直接创建Pod。这是因为Pods单独对机器故障没有弹性,但是控制器是。
如果节点死亡或与群集的其余部分断开连接,Kubernetes会应用策略phase将丢失节点上的所有Pod设置为Failed。
例子
高级活动探测示例
活动探测由kubelet执行,因此所有请求都在kubelet网络名称空间中进行。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- args:
- /server
image: k8s.gcr.io/liveness
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 15
timeoutSeconds: 1
name: liveness
示例状态
- Pod正在运行并有一个Container。集装箱出口成功。
- 记录完成事件。
- 如果
restartPolicy是:- 始终:重启容器; Pod
phase保持运行状态。 - OnFailure:Pod
phase成功。 - 从不:Pod
phase成功。
- 始终:重启容器; Pod
- Pod正在运行并有一个Container。容器退出失败。
- 记录失败事件。
- 如果
restartPolicy是:- 始终:重启容器; Pod
phase保持运行状态。 - OnFailure:重启容器; Pod
phase保持运行状态。 - 从不:Pod
phase变得失败。
- 始终:重启容器; Pod
- Pod正在运行并有两个容器。容器1出现故障。
- 记录失败事件。
- 如果
restartPolicy是:- 始终:重启容器; Pod
phase保持运行状态。 - OnFailure:重启容器; Pod
phase保持运行状态。 - 从不:不要重启容器; Pod
phase保持运行状态。
- 始终:重启容器; Pod
- 如果Container 1未运行,并且Container 2退出:
- 记录失败事件。
- 如果
restartPolicy是:- 始终:重启容器; Pod
phase保持运行状态。 - OnFailure:重启容器; Pod
phase保持运行状态。 - 从不:Pod
phase变得失败。
- 始终:重启容器; Pod
- Pod正在运行并有一个Container。容器耗尽内存。
- 记录失败事件。
- 记录OOM事件。
- 如果
restartPolicy是:- 始终:重启容器; Pod
phase保持运行状态。 - OnFailure:重启容器; Pod
phase保持运行状态。 - 从不:记录失败事件; Pod
phase保持运行状态。
- 始终:重启容器; Pod
- Pod正在运行,磁盘已经死亡。
- 杀死所有容器。
- 记录适当的事件。
- Pod
phase变得失败。 - 如果在控制器下运行,Pod将在其他位置重新创建。
- Pod正在运行,其节点已分段。
- 杀死所有容器。
- 记录适当的事件。
- Pod
phase变得失败。 - 如果在控制器下运行,Pod将在其他位置重新创建。
初始容器
此页面提供了Init Containers的概述,它是在应用程序容器之前运行的专用容器,可以包含应用程序映像中不存在的实用程序或设置脚本。
- 了解Init容器
- Init容器可以用于什么?
- 详细的行为
- 支持和兼容性
了解Init容器
一个pod能够在其内运行的应用程序的多个容器,但它也可以有一个或多个初始化容器,该容器的应用容器启动之前运行。
Init容器与常规容器完全相同,除了:
- 他们总是跑完成。
- 每个人必须在下一个启动之前成功完成。
如果Init容器的Init容器失败,Kubernetes会重复重启Pod,直到Init容器成功。但是,如果Pod具有restartPolicyNever,则不会重新启动。
要将Container指定为Init容器,请将initContainersPodSpec上的字段添加 为应用程序数组旁边的Container类型的JSON containers数组。init容器的状态在.status.initContainerStatuses字段中作为容器状态的数组返回(类似于.status.containerStatuses字段)。
与常规容器的差异
Init Containers支持应用容器的所有字段和功能,包括资源限制,卷和安全设置。但是,Init容器的资源请求和限制的处理方式略有不同,这些内容在下面的参考资料中有说明。此外,Init Containers不支持就绪探针,因为它们必须在Pod准备好之前运行完成。
如果为Pod指定了多个Init容器,则按顺序一次运行一个Container。每一个都必须在下一次运行之前成功。当所有Init容器都运行完成后,Kubernetes会初始化Pod并像往常一样运行应用程序容器。
Init容器可以用于什么?
由于Init Containers具有来自应用容器的单独镜像,因此它们对于启动相关代码具有一些优势:
- 出于安全原因,它们可以包含并运行不希望包含在应用容器镜像中的实用程序。
- 它们可以包含应用程序镜像中不存在的用于设置的实用程序或自定义代码。例如,没有必要使镜像
FROM的另一个镜像只使用像工具sed,awk,python,或dig在安装过程中。 - 应用程序映像构建器和部署者角色可以独立工作,而无需共同构建单个应用程序镜像。
- 他们使用Linux命名空间,以便他们从应用程序容器中获得不同的文件系统视图。因此,他们可以访问应用容器无法访问的秘密。
- 它们在任何应用程序容器启动之前运行完成,而应用程序容器并行运行,因此Init容器提供了一种简单的方法来阻止或延迟应用容器的启动,直到满足一组前置条件。
例子
以下是有关如何使用Init Containers的一些想法:
- 等待使用shell命令创建服务,例如:
- 我在{1..100}; 做睡觉1; 如果挖我的服务; 然后退出0; 网络连接; 完成; 退出1
使用以下命令从向下API向远程服务器注册此Pod:
curl -X POST http:// $ MANAGEMENT_SERVICE_HOST:$ MANAGEMENT_SERVICE_PORT / register -d’instal = $()IP = $()”
- 等待一段时间,然后使用类似命令启动app Container
sleep 60。 - 将git存储库克隆到卷中。
- 将值放入配置文件并运行模板工具以动态生成主应用程序Container的配置文件。例如,将POD_IP值放在配置中,并使用Jinja生成主应用程序配置文件。
可以在StatefulSets文档 和Production Pods指南中找到更详细的用法示例。
初始容器正在使用中
以下针对Kubernetes 1.5的yaml文件概述了一个具有两个Init容器的简单Pod。第一个等待,myservice第二个等待mydb。一旦两个容器完成,Pod就会开始。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
annotations:
pod.beta.kubernetes.io/init-containers: '[
{
"name": "init-myservice",
"image": "busybox",
"command": ["sh", "-c", "until nslookup myservice; do echo waiting for myservice; sleep 2; done;"]
},
{
"name": "init-mydb",
"image": "busybox",
"command": ["sh", "-c", "until nslookup mydb; do echo waiting for mydb; sleep 2; done;"]
}
]'
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
Kubernetes 1.6中有一种新语法,尽管旧的注释语法仍适用于1.6和1.7。新语法必须用于1.8或更高版本。我们已将Init Containers的声明移至spec:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']
- name: init-mydb
image: busybox
command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
1.5语法仍适用于1.6,但我们建议使用1.6语法。在Kubernetes 1.6中,Init Containers在API中成为了一个领域。beta注释在1.6和1.7中仍然受到尊重,但在1.8或更高版本中不受支持。
下面YAML文件概述了mydb与myservice服务:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19kind: Service
apiVersion: v1
metadata:
name: myservice
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9376
kind: Service
apiVersion: v1
metadata:
name: mydb
spec:
ports:
- protocol: TCP
port: 80
targetPort: 9377
可以使用以下命令启动和调试此Pod:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40$ kubectl create -f myapp.yaml
pod/myapp-pod created
$ kubectl get -f myapp.yaml
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 6m
$ kubectl describe -f myapp.yaml
Name: myapp-pod
Namespace: default
[...]
Labels: app=myapp
Status: Pending
[...]
Init Containers:
init-myservice:
[...]
State: Running
[...]
init-mydb:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Containers:
myapp-container:
[...]
State: Waiting
Reason: PodInitializing
Ready: False
[...]
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
16s 16s 1 {default-scheduler } Normal Scheduled Successfully assigned myapp-pod to 172.17.4.201
16s 16s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulling pulling image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Pulled Successfully pulled image "busybox"
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Created Created container with docker id 5ced34a04634; Security:[seccomp=unconfined]
13s 13s 1 {kubelet 172.17.4.201} spec.initContainers{init-myservice} Normal Started Started container with docker id 5ced34a04634
$ kubectl logs myapp-pod -c init-myservice # Inspect the first init container
$ kubectl logs myapp-pod -c init-mydb # Inspect the second init container
一旦我们启动mydb和myservice服务,我们就可以看到Init Containers完成并myapp-pod创建了:1
2
3
4
5
6$ kubectl create -f services.yaml
service/myservice created
service/mydb created
$ kubectl get -f myapp.yaml
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 9m
这个例子非常简单,但应该为您创建自己的Init容器提供一些灵感。
详细的行为
在Pod启动期间,初始化网络和卷后,初始容器将按顺序启动。每个Container必须在下一个Container启动之前成功退出。如果Container由于运行时未能启动或因故障退出,则根据Pod重试restartPolicy。但是,如果将Pod restartPolicy设置为Always,则Init Containers将使用 RestartPolicyOnFailure。
在Ready所有Init容器都成功之前,Pod不能。Init容器上的端口不在服务下聚合。正在初始化的Pod处于Pending状态,但应将条件Initializing设置为true。
如果重新启动 Pod,则必须再次执行所有Init Containers。
Init容器规范的更改仅限于容器镜像字段。更改Init Container镜像字段相当于重新启动Pod。
由于Init Containers可以重新启动,重试或重新执行,因此Init Container代码应该是幂等的。特别是,EmptyDirs 应该为输出文件已经存在的可能性准备写入文件的代码。
Init Containers具有应用Container的所有字段。但是,Kubernetes禁止readinessProbe使用,因为Init Containers无法定义与完成不同的准备情况。这在验证期间强制执行。
使用activeDeadlineSeconds上podlivenessProbe的容器,以防止初始化容器从永远失败。活动截止日期包括Init Containers。
Pod中每个应用程序和Init容器的名称必须是唯一的; 任何与另一个名称共享名称的Container都会引发验证错误。
资源
给定Init Containers的排序和执行,适用以下资源使用规则:
- 在所有Init Containers上定义的任何特定资源请求或限制的最高值是有效的init请求/限制
- Pod 对资源的有效请求/限制是以下值中的较高者:
- 资源的所有应用容器请求/限制的总和
- 资源的有效init请求/限制
- 调度是基于有效的请求/限制完成的,这意味着Init Containers可以预留在Pod生命周期内未使用的初始化资源。
- Pod的有效QoS层的QoS层是Init Containers和app容器的QoS层。
根据有效的Pod请求和限制应用配额和限制。
Pod级别cgroup基于有效的Pod请求和限制,与调度程序相同。
Pod重启原因
Pod可以重新启动,导致重新执行Init Containers,原因如下:
- 用户更新PodSpec,导致Init容器映像发生更改。App Container图像更改仅重新启动应用程序Container。
- Pod基础架构容器重新启动。这种情况并不常见,必须由对节点具有root访问权限的人员来完成。
- Pod中的所有容器都被终止,同时
restartPolicy设置为Always,强制重新启动,并且Init Container完成记录由于垃圾回收而丢失。
支持和兼容性
具有Apiserver 1.6.0或更高版本的群集支持使用该.spec.initContainers字段的Init Containers 。以前的版本使用alpha或beta注释支持Init Containers。该.spec.initContainers字段还镜像为alpha和beta注释,以便Kubelet 1.3.0或更高版本可以执行Init Containers,因此版本1.6 apiserver可以安全地回滚到1.5.x版,而不会丢失现有创建的pod的Init Container功能。
在Apiserver和Kubelet 1.8.0或更高版本中,删除了对alpha和beta注释的支持,需要从不推荐的注释转换到 .spec.initContainers字段。
此功能已在1.6中退出测试版。可以在应用程序containers阵列旁边的PodSpec中指定Init容器。beta注释值仍将受到尊重并覆盖PodSpec字段值,但是,它们在1.6和1.7中已弃用。在1.8中,不再支持注释,必须将其转换为PodSpec字段。
Pod Preset
此页面提供PodPresets的概述,PodPresets是在创建时将特定信息注入pod的对象。信息可以包括秘密,卷,卷安装和环境变量。
- 了解Pod预设
- 这个怎么运作
- 启用Pod预设
了解Pod预设
Pod Preset是一种API资源,用于在创建时将其他运行时需求注入Pod。您可以使用标签选择器 指定应用给定Pod预设的Pod。
使用Pod预设允许pod模板作者不必显式提供每个pod的所有信息。这样,使用特定服务的pod模板的作者不需要知道有关该服务的所有详细信息。
这个怎么运作
Kubernetes提供了一个准入控制器(PodPreset),当启用时,它将Pod Presets应用于传入的pod创建请求。发生pod创建请求时,系统会执行以下操作:
- 检索所有
PodPresets可用的。 - 检查任何标签选择器是否
PodPreset与正在创建的pod上的标签匹配。 - 尝试将所定义的各种资源合并
PodPreset到正在创建的Pod中。 - 出错时,抛出一个记录pod上合并错误的事件,并创建pod 而不从中注入任何资源
PodPreset。 - 注释生成的修改后的Pod规范,以指示它已被修改
PodPreset。注释是形式的podpreset.admission.kubernetes.io/podpreset-<pod-preset name>: "<resource version>"。
每个Pod可以匹配零个或多个Pod Presets; 并且每个PodPreset都可以应用于零个或多个pod。当 PodPreset应用于一个或多个Pod时,Kubernetes会修改Pod规范。对于更改Env,EnvFrom和 VolumeMounts,Kubernetes修改在波德所有容器容器规范; 对于更改Volume,Kubernetes修改Pod规范。
注意: Pod Preset能够
.spec.containers在适当的时候修改Pod规范中的字段。没有从POD预置资源定义将被应用到initContainers外地。
禁用特定Pod的Pod预设
在某些情况下,您希望Pod不会被任何Pod Preset突变改变。在这些情况下,您可以在表单的Pod Spec中添加注释:podpreset.admission.kubernetes.io/exclude: "true"。
启用Pod预设
要在群集中使用Pod Presets,您必须确保以下内容:
- 您已启用API类型
settings.k8s.io/v1alpha1/podpreset。例如,这可以通过包含settings.k8s.io/v1alpha1=true在--runtime-configAPI服务器的选项中来完成。在minikube中,--extra-config=apiserver.runtime-config=settings.k8s.io/v1alpha1=true在启动集群时添加此标志 。 - 您已启用准入控制器
PodPreset。执行此操作的一种方法是包含PodPreset在--enable-admission-plugins为API服务器指定的选项值中。在minikube中,--extra-config=apiserver.enable-admission-plugins=Initializers,NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,NodeRestriction,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,PodPreset在启动集群时添加此标志 。 - 您已通过
PodPreset在将使用的命名空间中创建对象来定义Pod预设。
中断
本指南适用于想要构建高可用性应用程序的应用程序所有者,因此需要了解Pod可能发生的中断类型。
它也适用于希望执行自动群集操作的群集管理员,例如升级和自动缩放群集。
- 自愿和非自愿中断
- 处理中断
- 中断预算如何运作
- PDB示例
- 分离群集所有者和应用程序所有者角色
- 如何在群集上执行破坏性操作
自愿和非自愿中断
在有人(一个人或一个控制器)摧毁它们,或者存在不可避免的硬件或系统软件错误之前,Pod不会消失。
我们将这些不可避免的案例称为对应用程序的非自愿中断。例如:
- 支持节点的物理机的硬件故障
- 集群管理员错误地删除了VM(实例)
- 云提供商或虚拟机管理程序故障使虚拟机消失
- 内核恐慌
- 由于群集网络分区,节点从群集中消失
- 由于节点资源不足而导致pod被驱逐。
除资源不足外,大多数用户都应熟悉所有这些条件; 它们不是Kubernetes特有的。
我们将其他案件称为自愿中断。其中包括应用程序所有者启动的操作和群集管理员启动的操作。典型应用程序所有者操作包
- 删除管理pod的部署或其他控制器
- 更新部署的pod模板导致重新启动
- 直接删除pod(例如意外)
群集管理员操作包括:
- 耗尽节点进行修复或升级。
- 从群集中排出节点以缩小群集(了解群集自动缩放 )。
- 从节点中删除pod以允许其他内容适合该节点。
这些操作可以由集群管理员直接执行,也可以由集群管理员或集群主机提供商自动运行。
请咨询您的集群管理员或咨询您的云提供商或分发文档,以确定是否为您的集群启用了任何自愿中断源。如果未启用,则可以跳过创建Pod中断预算。
处理中断
以下是一些缓解非自愿中断的方法:
- 确保您的pod 请求所需的资源。
- 如果需要更高的可用性,请复制应用程序。(了解运行复制的 无状态 和有状态应用程序。)
- 为了在运行复制的应用程序时获得更高的可用性,可以跨机架(使用反关联)或跨区域(如果使用 多区域群集)分布应用程序 。
自愿中断的频率各不相同。在基本的Kubernetes集群上,根本没有自愿中断。但是,您的群集管理员或托管服务提供商可能会运行一些导致自愿中断的其他服务。例如,推出节点软件更新可能会导致自愿中断。此外,群集(节点)自动缩放的某些实现可能会导致自动中断以进行碎片整理和压缩节点。您的集群管理员或托管服务提供商应记录预期的自愿中断级别(如果有)。
Kubernetes提供的功能可以帮助您在频繁的自愿中断的同时运行高可用性应用程序。我们将这组功能称为 中断预算。
中断预算如何运作
应用程序所有者可以PodDisruptionBudget为每个应用程序创建一个对象(PDB)。PDB限制复制应用程序的pod的数量,这些pod与自愿中断同时发生故障。例如,基于仲裁的应用程序希望确保运行的副本数量永远不会低于仲裁所需的数量。Web前端可能希望确保服务负载的副本数量永远不会低于总数的某个百分比。
集群管理器和托管提供商应使用通过调用Eviction API 而不是直接删除pod来遵守Pod Disruption Budgets的工具。示例是kubectl drain命令和Kubernetes-on-GCE集群升级脚本(cluster/gce/upgrade.sh)。
当集群管理员想要耗尽节点时,他们使用该kubectl drain命令。该工具试图驱逐机器上的所有pod。可以暂时拒绝逐出请求,并且该工具定期重试所有失败的请求,直到所有pod终止,或者直到达到可配置的超时。
PDB指定应用程序可以容忍的副本数量,相对于预期的副本数量。例如,具有部署.spec.replicas: 5应该在任何给定时间具有5个pod。如果其PDB允许一次有4个,则Eviction API将允许一次自动中断一个而不是两个pod。
组成应用程序的pod组使用标签选择器指定,与应用程序控制器使用的标签选择器相同(部署,有状态集等)。
“预期”数量的pod是根据.spec.replicaspods控制器计算出来的。使用.metadata.ownerReferences对象的pod从pod中发现控制器。
PDB不能防止非自愿中断发生,但它们确实违背了预算。
由于滚动升级到应用程序而被删除或不可用的Pod确实会计入中断预算,但是在执行滚动升级时,控制器(如部署和有状态集)不受PDB限制 - 在应用程序更新期间处理故障在控制器规范中。(了解有关更新部署的信息。)
当吊舱使用驱逐API逐出,它是正常终止(见 terminationGracePeriodSeconds在PodSpec。)
PDB示例
考虑具有3个节点的群集中,node-1通过node-3。群集正在运行多个应用程序。其中一人有3个副本最初称 pod-a,pod-b和pod-c。pod-x还示出了另一个没有PDB的不相关的pod。最初,pod的布局如下:
| 节点-1 | 节点-2- | 节点-3- |
|---|---|---|
| pod-a 可用 | pod-b 可用 | pod-c 可用 |
| pod-x 可用 |
所有3个pod都是部署的一部分,它们共同拥有一个PDB,要求所有3个pod中至少有2个可用。
例如,假设集群管理员想要重新启动到新的内核版本来修复内核中的错误。群集管理员首先尝试node-1使用该kubectl drain命令消耗。该工具试图驱逐pod-a和pod-x。这立即成功。两个pod同时进入该terminating。这使集群处于以下状态
| 节点-1 耗尽 | 节点-2- | 节点-3- |
|---|---|---|
| pod-a 终止 | pod-b 可用 | pod-c 可用 |
| pod-x 终止 |
部署注意到其中一个pod正在终止,因此它会创建一个名为的替换pod-d。由于node-1是封锁的,它落在另一个节点上。还创造pod-y了一些替代品pod-x。
(注意:对于一个StatefulSet,pod-a它将被称为类似的东西pod-1,需要在它被替换之前完全终止,也可以被调用,pod-1但是可以创建不同的UID。否则,该示例也适用于StatefulSet。)
现在集群处于以下状态:
| 节点-1 耗尽 | 节点-2- | 节点-3- |
|---|---|---|
| pod-a 终止 | pod-b 可用 | pod-c 可用 |
| pod-x 终止 | pod-b 开始 | POD-Y |
在某些时候,pod终止,集群看起来像这样:
| 节点-1 耗尽 | 节点-2- | 节点-3- |
|---|---|---|
| pod-b 可用 | pod-c 可用 | |
| pod-b 开始 | POD-Y |
此时,如果一个不耐烦的集群管理员试图耗尽,node-2或者 node-3排除命令将阻塞,因为部署只有2个可用的pod,并且其PDB至少需要2.经过一段时间后,pod-d变为可用。
群集状态现在看起来像这样:
| 节点-1 耗尽 | 节点-2- | 节点-3- |
|---|---|---|
| pod-b 可用 | pod-c 可用 | |
| pod-b 可用 | POD-Y |
现在,集群管理员试图耗尽node-2。drain命令将尝试以某种顺序驱逐两个pod,pod-b先说然后再说 pod-d。它将成功驱逐pod-b。但是,当它试图逐出时pod-d,它将被拒绝,因为这将只留下一个可用于部署的pod。
部署创建了pod-b被叫的替代品pod-e。因为集群中没有足够的资源来安排 pod-e排水将再次阻塞。群集可能最终处于此状态:
| 节点-1 耗尽 | 节点-2- | 节点-3- | 没有节点 |
|---|---|---|---|
| pod-b 可用 | pod-c 可用 | pod-e 待定 | |
| pod-b 可用 | POD-Y |
此时,集群管理员需要将节点添加回集群以继续升级。
你可以看到Kubernetes如何改变发生中断的速度,根据:
- 应用程序需要多少个副本
- 优雅地关闭实例需要多长时间
- 启动新实例需要多长时间
- 控制器的类型
- 集群的资源容量
分离群集所有者和应用程序所有者角色
通常,将群集管理器和应用程序所有者视为彼此知之甚少的单独角色很有用。在这些情况下,这种职责分离可能有意义:
- 当有许多应用程序团队共享Kubernetes集群时,角色有自然的专业化
- 当第三方工具或服务用于自动化集群管理时
Pod Disruption Budgets通过在角色之间提供接口来支持这种角色分离。
如果您的组织中没有这样的责任分离,则可能不需要使用Pod Disruption Budgets。
如何在群集上执行破坏性操作
如果您是群集管理员,并且需要对群集中的所有节点执行中断操作,例如节点或系统软件升级,则可以使用以下选项:
- 在升级期间接受停机时间。
- 故障转移到另一个完整的副本群集。
- 没有停机时间,但对于重复的节点以及人类协调切换的努力可能都是昂贵的。
- 编写容错中断应用程序并使用PDB。
- 没有停机时间。
- 最小的资源重复。
- 允许更多自动化群集管理。
- 编写容忍破坏性的应用程序很棘手,但容忍自愿中断的工作很大程度上与支持自动缩放和容忍非自愿中断的工作重叠。
控制器
ReplicaSet
ReplicaSet是下一代复制控制器。现在ReplicaSet和 Replication Controller之间的唯一区别是选择器支持。ReplicaSet支持新的基于集合的选择器要求,如标签用户指南中所述, 而Replication Controller仅支持基于等同的选择器要求。
- 如何使用ReplicaSet
- 何时使用ReplicaSet
- 例
- 编写副本集规范
- 使用ReplicaSet
- ReplicaSet的替代品
如何使用ReplicaSet
大多数kubectl支持复制控制器的命令也支持ReplicaSet。rolling-update命令是一个例外 。如果您想要滚动更新功能,请考虑使用部署。此外, rolling-update命令是必需的,而Deployments是声明性的,因此我们建议通过rollout命令使用Deployments 。
虽然ReplicaSet可以独立使用,但今天它主要被 Deployments用作协调pod创建,删除和更新的机制。使用“部署”时,您不必担心管理它们创建的副本集。部署拥有并管理其ReplicaSet。
何时使用ReplicaSet
ReplicaSet确保在任何给定时间运行指定数量的pod副本。但是,Deployment是一个更高级别的概念,它管理ReplicaSet并为pod提供声明性更新以及许多其他有用的功能。因此,除非您需要自定义更新编排或根本不需要更新,否则我们建议使用部署而不是直接使用ReplicaSet。
这实际上意味着您可能永远不需要操作ReplicaSet对象:改为使用Deployment,并在spec部分中定义您的应用程序。
例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39#controllers/frontend.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
metadata:
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
resources:
requests:
cpu: 100m
memory: 100Mi
env:
- name: GET_HOSTS_FROM
value: dns
# If your cluster config does not include a dns service, then to
# instead access environment variables to find service host
# info, comment out the 'value: dns' line above, and uncomment the
# line below.
# value: env
ports:
- containerPort: 80
将此清单保存frontend.yaml到Kubernetes集群并将其提交到Kubernetes集群应该创建已定义的ReplicaSet及其管理的pod。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36$ kubectl create -f http://k8s.io/examples/controllers/frontend.yaml
replicaset.apps/frontend created
$ kubectl describe rs/frontend
Name: frontend
Namespace: default
Selector: tier=frontend,tier in (frontend)
Labels: app=guestbook
tier=frontend
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=guestbook
tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: 80/TCP
Requests:
cpu: 100m
memory: 100Mi
Environment:
GET_HOSTS_FROM: dns
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 {replicaset-controller } Normal SuccessfulCreate Created pod: frontend-qhloh
1m 1m 1 {replicaset-controller } Normal SuccessfulCreate Created pod: frontend-dnjpy
1m 1m 1 {replicaset-controller } Normal SuccessfulCreate Created pod: frontend-9si5l
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
frontend-9si5l 1/1 Running 0 1m
frontend-dnjpy 1/1 Running 0 1m
frontend-qhloh 1/1 Running 0 1m
编写副本集规范
与所有其他Kubernetes API对象,一个ReplicaSet需要apiVersion,kind和metadata领域。有关使用清单的一般信息,请参阅使用kubectl进行对象管理。
ReplicaSet还需要一个.spec部分。
Pod模板
这.spec.template是唯一必需的领域.spec。这.spec.template是一个 pod模板。它与pod具有完全相同的架构 ,除了它是嵌套的并且没有apiVersion或kind。
除了pod的必填字段外,ReplicaSet中的pod模板还必须指定适当的标签和适当的重新启动策略。
对于标签,请确保不与其他控制器重叠。有关更多信息,请参阅pod选择器。
对于重新启动策略,唯一允许的值.spec.template.spec.restartPolicy是Always,这是默认值。
对于本地容器重新启动,ReplicaSet委托给节点上的代理程序,例如Kubelet或Docker。
Pod选择器
该.spec.selector字段是标签选择器。ReplicaSet使用与选择器匹配的标签管理所有pod。它不区分它创建或删除的pod以及另一个人或进程创建或删除的pod。这允许替换ReplicaSet而不影响正在运行的pod。
在.spec.template.metadata.labels必须匹配.spec.selector,否则会被API被拒绝。
在Kubernetes 1.9中,apps/v1ReplicaSet类型的API版本是当前版本,默认情况下已启用。apps/v1beta2不推荐使用API版本。
此外,您通常不应创建任何标签与此选择器匹配的pod,可以直接与另一个ReplicaSet一起创建,也可以与其他控制器(如Deployment)一起创建。如果这样做,ReplicaSet会认为它创建了其他pod。Kubernetes并没有阻止你这样做。
如果最终有多个具有重叠选择器的控制器,则必须自己管理删除。
副本集上的标签
ReplicaSet本身可以有标签(.metadata.labels)。通常,您可以将它们设置为相同.spec.template.metadata.labels。但是,允许它们不同,并且.metadata.labels不会影响ReplicaSet的行为。
副本
您可以通过设置指定应同时运行的pod数量.spec.replicas。在任何时间运行的数字可能更高或更低,例如,如果副本只是增加或减少,或者如果正常关闭吊舱,并且提前开始更换。
如果未指定.spec.replicas,则默认为1。
使用ReplicaSet
删除ReplicaSet及其Pod
要删除ReplicaSet及其所有Pod,请使用kubectl delete。该垃圾收集器在默认情况下会自动删除所有相关的荚。
使用REST API或client-go库时,必须设置propagationPolicy为Background或Foreground删除选项。例如:1
2
3
4kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/extensions/v1beta1/namespaces/default/replicasets/frontend' \
> -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
> -H "Content-Type: application/json"
仅删除副本集
您可以删除副本集,而不会影响使用kubectl delete该--cascade=false选项的任何pod 。使用REST API或client-go库时,必须设置propagationPolicy为Orphan,例如:1
2
3
4kubectl proxy --port=8080
curl -X DELETE 'localhost:8080/apis/extensions/v1beta1/namespaces/default/replicasets/frontend' \
> -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
> -H "Content-Type: application/json"
删除原始文件后,您可以创建一个新的ReplicaSet来替换它。只要旧的和新.spec.selector的相同,那么新的将采用旧的豆荚。但是,它不会做任何努力使现有的pod匹配一个新的,不同的pod模板。要以受控方式将pod更新为新规范,请使用滚动更新。
从副本集隔离pod
可以通过更改标签来从ReplicaSet的目标集中删除Pod。此技术可用于从服务中删除pod以进行调试,数据恢复等。以这种方式删除的Pod将自动替换(假设副本的数量也未更改)。
缩放副本集
只需更新.spec.replicas字段即可轻松扩展或缩小ReplicaSet 。ReplicaSet控制器确保具有匹配标签选择器的所需数量的pod可用且可操作。
ReplicaSet作为水平Pod自动缩放器目标
ReplicaSet也可以是 Horizontal Pod Autoscalers (HPA)的目标 。也就是说,HPA可以自动缩放ReplicaSet。以下是针对我们在上一个示例中创建的ReplicaSet的示例HPA。1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: frontend-scaler
spec:
scaleTargetRef:
kind: ReplicaSet
name: frontend
minReplicas: 3
maxReplicas: 10
targetCPUUtilizationPercentage: 50
将此清单保存hpa-rs.yaml到Kubernetes集群并将其提交到Kubernetes集群应该创建定义的HPA,该HPA根据复制的pod的CPU使用情况自动调整目标ReplicaSet。1
kubectl create -f https://k8s.io/examples/controllers/hpa-rs.yaml
或者,您可以使用该kubectl autoscale命令来完成相同的操作(并且它更容易!)1
kubectl autoscale rs frontend --max=10
ReplicaSet的替代品
部署(推荐)
Deployment是一个更高级别的API对象,它以类似的方式更新其底层ReplicaSet及其Pod kubectl rolling-update。如果您需要此滚动更新功能,则建议进行部署,因为kubectl rolling-update它们不同于声明式,服务器端,并具有其他功能。有关使用部署运行无状态应用程序的更多信息,请阅读使用部署运行无状态应用程序。
Bare Pods
与用户直接创建pod的情况不同,ReplicaSet会替换因任何原因而被删除或终止的pod,例如在节点故障或破坏性节点维护(例如内核升级)的情况下。因此,即使您的应用程序只需要一个pod,我们也建议您使用ReplicaSet。可以想象它与流程主管类似,只是它监控多个节点上的多个pod而不是单个节点上的单个进程。ReplicaSet将本地容器重新启动委派给节点上的某个代理程序(例如,Kubelet或Docker)。
Job
对于预期会自行终止的pod(即批处理作业),请使用Job而不是ReplicaSet。
DaemonSet
DaemonSet对于提供机器级功能的pod,例如机器监视或机器日志记录,请使用ReplicaSet而不是ReplicaSet。这些pod的生命周期与机器生命周期相关:pod需要在其他pod启动之前在机器上运行,并且当机器准备好重新启动/关闭时可以安全终止。
ReplicationController
注意:现在建议使用配置ReplicaSet的Deployment来设置复制。
ReplicationController确保pod副本的指定数量的在任何一个时间运行。换句话说,ReplicationController确保一个pod或一组同类pod总是可用。
- ReplicationController的工作原理
- 运行示例ReplicationController
- 编写ReplicationController规范
- 使用ReplicationControllers
- 常见的使用模式
- 编写复制程序
- ReplicationController的职责
- API对象
- ReplicationController的替代品
- 欲获得更多信息
ReplicationController的工作原理
如果存在太多pod,则ReplicationController将终止额外的pod。如果太少,ReplicationController将启动更多pod。与手动创建的pod不同,ReplicationController维护的pod在失败,删除或终止时会自动替换。例如,在内核升级等破坏性维护之后,会在节点上重新创建pod。因此,即使应用程序只需要一个pod,也应该使用ReplicationController。ReplicationController类似于进程管理程序,但是ReplicationController不是监视单个节点上的各个进程,而是监视多个节点上的多个pod。
在讨论中,ReplicationController通常缩写为“rc”或“rcs”,并且作为kubectl命令中的快捷方式。
一个简单的例子是创建一个ReplicationController对象,以无限期地可靠地运行Pod的一个实例。更复杂的用例是运行复制服务的几个相同副本,例如Web服务器。
运行示例ReplicationController
此示例ReplicationController配置运行nginx Web服务器的三个副本。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20#controllers/replication.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: nginx
spec:
replicas: 3
selector:
app: nginx
template:
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
通过下载示例文件然后运行此命令来运行示例作业:1
2$ kubectl create -f https://k8s.io/examples/controllers/replication.yaml
replicationcontroller/nginx created
使用以下命令检查ReplicationController的状态:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23$ kubectl describe replicationcontrollers/nginx
Name: nginx
Namespace: default
Selector: app=nginx
Labels: app=nginx
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 0 Running / 3 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- ---- ------ -------
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-qrm3m
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-3ntk0
20s 20s 1 {replication-controller } Normal SuccessfulCreate Created pod: nginx-4ok8v
这里创建了三个pod,但没有一个正在运行,可能是因为正在拉动图像。稍后,相同的命令可能会显示:
1
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
要以机器可读的形式列出属于ReplicationController的所有pod,可以使用如下命令:1
2
3 $ pods=$(kubectl get pods --selector=app=nginx --output=jsonpath={.items..metadata.name})
echo $pods
nginx-3ntk0 nginx-4ok8v nginx-qrm3m
这里,选择器与ReplicationController的选择器相同(在kubectl describe输出中看到 ,并以不同的形式显示replication.yaml。该--output=jsonpath选项指定一个表达式,它只从返回列表中的每个pod获取名称。
编写ReplicationController规范
与所有其他Kubernetes配置,一个ReplicationController需要apiVersion,kind和metadata领域。有关使用配置文件的一般信息,请参阅对象管理。
ReplicationController还需要一个.spec部分。
Pod模板
这.spec.template是唯一必需的领域.spec。
这.spec.template是一个pod模板。它与pod具有完全相同的架构,除了它是嵌套的并且没有apiVersion或kind。
除了Pod的必需字段之外,ReplicationController中的pod模板还必须指定适当的标签和适当的重新启动策略。对于标签,请确保不要与其他控制器重叠。请参阅pod选择器。
只允许.spec.template.spec.restartPolicy等于Always,如果未指定,则为默认值。
对于本地容器重新启动,ReplicationControllers委托给节点上的代理程序,例如Kubelet或Docker。
ReplicationController上的标签
ReplicationController本身可以有labels(.metadata.labels)。通常,您可以将它们设置为相同.spec.template.metadata.labels; 如果.metadata.labels未指定,则默认为.spec.template.metadata.labels。但是,允许它们不同,并且.metadata.labels不会影响ReplicationController的行为。
Pod选择器
该.spec.selector字段是标签选择器。ReplicationController管理具有与选择器匹配的标签的所有pod。它不区分它创建或删除的pod以及另一个人或进程创建或删除的pod。这允许在不影响正在运行的pod的情况下替换ReplicationController。
如果指定,则.spec.template.metadata.labels必须等于.spec.selector,否则将被API拒绝。如果.spec.selector未指定,则默认为.spec.template.metadata.labels。
此外,您通常不应创建任何标签与此选择器匹配的pod,可以直接创建,与另一个ReplicationController或其他控制器(如Job)匹配。如果这样做,ReplicationController会认为它创建了其他pod。Kubernetes并没有阻止你这样做。
如果最终有多个具有重叠选择器的控制器,则必须自己管理删除(见下文)。
多个副本
您可以通过设置.spec.replicas要同时运行的窗格数来指定应同时运行的窗格数。在任何时间运行的数字可能更高或更低,例如,如果副本只是增加或减少,或者如果正常关闭吊舱,并且提前开始更换。
如果未指定.spec.replicas,则默认为1。
使用ReplicationControllers
删除ReplicationController及其Pod
要删除ReplicationController及其所有pod,请使用kubectl delete。在删除ReplicationController本身之前,Kubectl会将ReplicationController缩放为零并等待它删除每个pod。如果此kubectl命令被中断,则可以重新启动它。
使用REST API或转到客户端库时,需要显式执行这些步骤(将副本扩展为0,等待窗格删除,然后删除ReplicationController)。
仅删除ReplicationController
您可以删除ReplicationController而不影响其任何pod。
使用kubectl,指定--cascade=false选项kubectl delete。
使用REST API或转到客户端库时,只需删除ReplicationController对象即可。
删除原始文件后,您可以创建一个新的ReplicationController来替换它。只要旧的和新.spec.selector的相同,那么新的将采用旧的pod。但是,它不会做任何努力使现有的pod匹配一个新的,不同的pod模板。要以受控方式将pod更新为新规范,请使用滚动更新。
从ReplicationController中隔离pod
可以通过更改标签来从ReplicationController的目标集中删除Pod。此技术可用于从服务中删除pod以进行调试,数据恢复等。以这种方式删除的Pod将自动替换(假设副本的数量也未更改)。
常见的使用模式
重新安排
如上所述,无论您是要保持运行1个pod还是1000个,ReplicationController都将确保存在指定数量的pod,即使在节点发生故障或pod终止时(例如,由于另一个控制剂)。
缩放
通过简单地更新replicas字段,ReplicationController可以手动或通过自动缩放控制代理轻松扩展或缩小副本数量。
滚动更新
ReplicationController旨在通过逐个替换pod来促进对服务的滚动更新。
如#1353中所述,建议的方法是创建一个具有1个副本的新ReplicationController,逐个扩展新的(+1)和旧(-1)控制器,然后在它达到0个副本后删除旧控制器。无论意外故障如何,这都可以预测更新pod的集合。
理想情况下,滚动更新控制器会考虑应用程序准备情况,并确保在任何给定时间内有足够数量的pod可以高效地运行。
这两个ReplicationControllers需要创建具有至少一个区分标签的pod,例如pod的主容器的image标签,因为它通常是图像更新,可以激发滚动更新。
滚动更新在客户端工具中实现 kubectl rolling-update。访问kubectl rolling-update任务以获得更具体的示例。
多个发行tracks
除了在滚动更新正在进行时运行多个版本的应用程序之外,通常使用多个版本跟踪长时间运行多个版本,甚至连续运行多个版本。轨道将按标签区分。
例如,服务可能会定位所有pod tier in (frontend), environment in (prod)。现在说你有10个复制的pod组成这个层。但是你希望能够’canary’这个组件的新版本。您可以replicas为大部分副本设置一个设置为9 的ReplicationController ,带有标签tier=frontend, environment=prod, track=stable,另一个replicas设置为1的带有标签的ReplicationController 用于canarytier=frontend, environment=prod, track=canary。现在该服务涵盖了canary和non-canary pods。但是你可以分别搞乱ReplicationControllers来测试,监视结果等。
将ReplicationControllers与Services一起使用
多个ReplicationControllers可以位于单个服务之后,例如,某些流量转到旧版本,有些流量转到新版本。
ReplicationController永远不会自行终止,但预计它不会像服务一样长寿。服务可以由多个ReplicationControllers控制的pod组成,并且预计可以在服务的生命周期内创建和销毁许多ReplicationController(例如,执行运行服务的pod的更新)。服务本身及其客户端都应该忽略维护服务pod的ReplicationControllers。
编写复制程序
由ReplicationController创建的Pod旨在是可互换的和语义相同的,尽管它们的配置可能随着时间的推移变得异构。这显然适用于复制的无状态服务器,但ReplicationControllers也可用于维护主选,分片和工作池应用程序的可用性。此类应用程序应使用动态工作分配机制,例如RabbitMQ工作队列,而不是静态/一次性定制每个pod的配置,这被视为反模式。执行的任何pod自定义,例如资源的垂直自动调整(例如,cpu或内存),应由另一个在线控制器进程执行,与ReplicationController本身不同。
ReplicationController的职责
ReplicationController只是确保所需数量的pod与其标签选择器匹配并且可以运行。目前,只有已终止的广告连播从其计数中排除。将来,可以考虑系统提供的准备情况和其他信息,我们可以对替换策略添加更多控制,并且我们计划发出可以由外部客户使用的事件,以实现任意复杂的替换和/或扩展下行政策。
ReplicationController永远受限于这种狭隘的责任。它本身不会执行准备就绪或活力探测。它不是执行自动缩放,而是由外部自动缩放器控制(如#492中所述),这将改变其replicas字段。我们不会将调度策略(例如,传播)添加到ReplicationController。它也不应该验证控制的pod与当前指定的模板匹配,因为这会妨碍自动调整大小和其他自动化过程。同样,完成期限,排序依赖性,配置扩展和其他功能属于其他地方。我们甚至计划分析批量pod创建的机制(#170)。
ReplicationController旨在成为可组合的构建块原语。我们希望在它和其他补充原语之上构建更高级别的API和/或工具,以便将来用户使用。kubectl目前支持的“宏”操作(运行,缩放,滚动更新)是概念验证的例子。例如,我们可以想象像Asgard管理ReplicationControllers,自动缩放器,服务,调度策略,canary等。
API对象
复制控制器是Kubernetes REST API中的顶级资源。有关API对象的更多详细信息,请访问: ReplicationController API对象。
ReplicationController的替代品
ReplicaSet
ReplicaSet是支持新的基于集合的标签选择器的下一代ReplicationController 。它主要用作Deployment协调pod创建,删除和更新的机制。请注意,除非您需要自定义更新编排或根本不需要更新,否则我们建议您使用“部署”而不是直接使用“副本集”。
部署(推荐)
Deployment是一个更高级别的API对象,它以类似的方式更新其基础副本集及其Pod kubectl rolling-update。如果您需要此滚动更新功能,则建议进行部署,因为kubectl rolling-update它们不同于声明式,服务器端,并具有其他功能。
pod
与用户直接创建pod的情况不同,ReplicationController替换因任何原因而被删除或终止的pod,例如在节点故障或破坏性节点维护(例如内核升级)的情况下。因此,即使您的应用程序只需要一个pod,我们也建议您使用ReplicationController。可以想象它与流程主管类似,只是它监控多个节点上的多个pod而不是单个节点上的单个进程。ReplicationController将本地容器重新启动委派给节点上的某个代理(例如,Kubelet或Docker)。
job
Job对于预期会自行终止的pod(即批处理作业),请使用而不是ReplicationController。
DaemonSet
DaemonSet对于提供机器级功能的pod,例如机器监视或机器日志记录,请使用而不是ReplicationController。这些pod的生命周期与机器生命周期相关:pod需要在其他pod启动之前在机器上运行,并且当机器准备好重新启动/关闭时可以安全终止。
欲获得更多信息
读取运行无状态AP复制控制器。
部署
一个部署控制器提供声明更新pod和 ReplicaSets。
您在Deployment对象中描述了所需的状态,Deployment控制器以受控速率将实际状态更改为所需状态。您可以定义部署以创建新的ReplicaSet,或者删除现有的部署并使用新的部署采用所有资源。
注意:您不应管理部署所拥有的ReplicaSet。应通过操作Deployment对象来涵盖所有用例。如果您的用例未在下面介绍,请考虑在主Kubernetes存储库中打开一个问题。
- 用例
- 创建部署
- 更新部署
- 回滚部署
- 扩展部署
- 暂停和恢复部署
- 部署状态
- 清理政策
- 用例
- 编写部署规范
- 部署的替代方案
用例
以下是部署的典型用例:
- 创建部署以部署副本集。ReplicaSet在后台创建Pod。检查卷展栏的状态以查看它是否成功。
- 通过更新Deployment的PodTemplateSpec来声明 Pod 的新状态。创建一个新的ReplicaSet,Deployment部署管理以受控速率将Pod从旧ReplicaSet移动到新ReplicaSet。每个新的ReplicaSet都会更新Deployment的修订版。
- 如果部署的当前状态不稳定,则回滚到早期的部署修订版。每次回滚都会更新Deployment的修订版。
- 扩展部署以促进更多负载。
- 暂停部署以将多个修复程序应用于其PodTemplateSpec,然后恢复它以启动新的部署。
- 使用部署的状态作为卷展栏卡住的指示符。
- 清理不再需要的旧ReplicaSet。
创建部署
以下是部署的示例。它创建一个ReplicaSet来调出三个Pod nginx:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22#controllers/nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
在这个例子中:
nginx-deployment创建名为的部署,由.metadata.name字段指示。- 部署创建三个复制的Pod,由
replicas字段指示。 - 该
selector字段定义了Deployment如何找到要管理的Pod。在这种情况下,您只需选择Pod模板(app: nginx)中定义的标签。但是,只要Pod模板本身满足规则,就可以使用更复杂的选择规则。
注意:
matchLabels是{key,value}对的映射。matchLabels映射中的单个{key,value} 等效matchExpressions于其元素,其键字段为“key”,运算符为“In”,值数组仅包含“value”。要求是AND。
- 该
template字段包含以下子字段:app: nginx使用该labels字段标记Pod 。- Pod模板的规范或.template.spec字段表示Pod 运行一个容器nginx,该容器在版本1.7.9下运行nginx Docker Hub映像。
- 创建一个容器并nginx使用该name字段命名。
- nginx在版本运行图像1.7.9。
- 打开端口,80以便容器可以发送和接受流量。
要创建此部署,请运行以下命令:1
kubectl create -f https://k8s.io/examples/controllers/nginx-deployment.yaml
注意:您可以指定
--record标志以写入在资源批注中执行的命令kubernetes.io/change-cause。它对于将来的内省非常有用,例如,可以查看每个Deployment修订版中执行的命令。
接下来,运行kubectl get deployments。输出类似于以下内容:1
2NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
检查群集中的“部署”时,将显示以下字段:
NAME列出群集中的部署名称。DESIRED显示应用程序的所需副本数,您在创建部署时定义这些副本。这是理想的状态。CURRENT显示当前正在运行的副本数量。UP-TO-DATE显示已更新以实现所需状态的副本数。AVAILABLE显示用户可以使用的应用程序副本数。AGE显示应用程序运行的时间。
请注意每个字段中的值如何与Deployment规范中的值相对应:
- 根据
.spec.replicas字段,所需副本的数量为3 。 - 根据
.status.replicas字段,当前副本的数量为0 。 - 根据
.status.updatedReplicas字段,最新副本的数量为0 。 - 根据
.status.availableReplicas字段,可用副本的数量为0 。
要查看“部署”卷展栏状态,请运行kubectl rollout status deployment.v1.apps/nginx-deployment。此命令返回以下输出:1
2Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
kubectl get deployments几秒钟后再次运行:1
2NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 18s
请注意,Deployment已创建所有三个副本,并且所有副本都是最新的(它们包含最新的Pod模板)并且可用(Pod状态至少为Deployment的.spec.minReadySeconds字段值准备就绪)。
要查看rs部署创建的ReplicaSet(),请运行kubectl get rs:1
2NAME DESIRED CURRENT READY AGE
nginx-deployment-2035384211 3 3 3 18s
请注意,ReplicaSet的名称始终格式为[DEPLOYMENT-NAME]-[POD-TEMPLATE-HASH-VALUE]。创建部署时会自动生成哈希值。
要查看为每个pod自动生成的标签,请运行kubectl get pods --show-labels。返回以下输出:1
2
3
4NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-2035384211-7ci7o 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
nginx-deployment-2035384211-kzszj 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
nginx-deployment-2035384211-qqcnn 1/1 Running 0 18s app=nginx,pod-template-hash=2035384211
创建的ReplicaSet确保始终有三个Pod nginx在运行。
注意:您必须在部署中指定适当的选择器和Pod模板标签(在本例中
app: nginx)。不要将标签或选择器与其他控制器(包括其他部署和StatefulSet)重叠。Kubernetes不会阻止您重叠,如果多个控制器具有重叠的选择器,那么这些控制器可能会发生冲突并出现意外行为。
Pod-template-hash标签
注意:请勿更改此标签。
pod-template-hash部署控制器将标签添加到部署创建或采用的每个ReplicaSet。
此标签可确保部署的子ReplicaSet不重叠。它是通过散列PodTemplateReplicaSet并使用生成的散列作为添加到ReplicaSet选择器,Pod模板标签以及ReplicaSet可能具有的任何现有Pod中的标签值生成的。
更新部署
注意:当且仅当部署的pod模板(即
.spec.template)更改时,才会触发Deployment的部署,例如,如果更新模板的标签或容器图像。其他更新(例如扩展部署)不会触发部署。
假设您现在想要更新nginx Pod以使用nginx:1.9.1镜像而不是nginx:1.7.9图像。1
2$ kubectl --record deployment.apps/nginx-deployment set image deployment.v1.apps/nginx-deployment
nginx=nginx:1.9.1 image updated
或者,您可以edit部署和改变.spec.template.spec.containers[0].image从nginx:1.7.9到nginx:1.9.1:
1 | $ kubectl edit deployment.v1.apps/nginx-deployment |
要查看卷展栏状态,请运行:1
2
3$ kubectl rollout status deployment.v1.apps/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
部署成功后,您可能需要get部署:1
2
3$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 36s
最新副本的数量表示Deployment已将副本更新为最新配置。当前副本表示此部署管理的副本总数,可用副本表示可用的当前副本数。
您可以运行kubectl get rs以查看部署通过创建新的ReplicaSet并将其扩展到3个副本来更新Pod,以及将旧的ReplicaSet缩减为0个副本。1
2
3
4$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 6s
nginx-deployment-2035384211 0 0 0 36s
get pods现在运行应该只显示新的Pod:1
2
3
4
5$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-khku8 1/1 Running 0 14s
nginx-deployment-1564180365-nacti 1/1 Running 0 14s
nginx-deployment-1564180365-z9gth 1/1 Running 0 14s
下次要更新这些Pod时,只需再次更新Deployment的pod模板。
部署可以确保在更新时只有一定数量的Pod可能会关闭。默认情况下,它确保至少比所需的Pod数量少25%(最大不可用25%)。
部署还可以确保在所需数量的Pod之上只能创建一定数量的Pod。默认情况下,它确保最多比所需数量的Pod多25%(最大浪涌25%)。
例如,如果仔细查看上面的部署,您将看到它首先创建了一个新的Pod,然后删除了一些旧的Pod并创建了新的Pod。在有足够数量的新Pod出现之前,它不会杀死旧的Pod,并且在足够数量的旧Pod被杀之前不会创建新的Pod。它确保可用Pod的数量至少为2,并且Pod的总数最多为4。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37$ kubectl describe deployments
Name: nginx-deployment
Namespace: default
CreationTimestamp: Thu, 30 Nov 2017 10:56:25 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=2
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-1564180365 (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m deployment-controller Scaled up replica set nginx-deployment-2035384211 to 3
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1564180365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-2035384211 to 0
在这里,您可以看到,当您第一次创建部署时,它创建了一个ReplicaSet(nginx-deployment-2035384211)并直接将其扩展到3个副本。更新部署时,它创建了一个新的ReplicaSet(nginx-deployment-1564180365)并将其扩展为1,然后将旧的ReplicaSet缩小为2,这样至少有2个Pod可用,最多创建了4个Pod一直。然后,它继续使用相同的滚动更新策略向上和向下扩展新旧ReplicaSet。最后,您将在新的ReplicaSet中拥有3个可用副本,并将旧的ReplicaSet缩小为0。
Rollover (aka multiple updates in-flight)
每次部署控制器观察到新的部署对象时,如果没有现有的ReplicaSet,则会创建ReplicaSet以显示所需的Pod。现有的ReplicaSet控制其标签匹配.spec.selector但模板不匹配的Pod .spec.template按比例缩小。最终,新的ReplicaSet将缩放到,.spec.replicas并且所有旧的ReplicaSet将缩放为0。
如果在现有部署过程中更新部署,则部署将根据更新创建新的ReplicaSet并开始向上扩展,并将翻转之前正在扩展的ReplicaSet - 它会将其添加到其列表中旧的ReplicaSet和将开始缩小它。
例如,假设您创建了一个部署以创建5个副本nginx:1.7.9,但是nginx:1.9.1当仅创建了3个副本时,则更新部署以创建5个副本nginx:1.7.9。在这种情况下,部署将立即开始杀死nginx:1.7.9它创建的3个Pod,并将开始创建 nginx:1.9.1Pod。nginx:1.7.9在更改课程之前,它不会等待创建5个副本。
标签选择器更新
通常不鼓励进行标签选择器更新,建议您事先规划选择器。在任何情况下,如果您需要执行标签选择器更新,请务必小心谨慎,并确保您已掌握所有含义。
注意:在API版本中
apps/v1,部署的标签选择器在创建后是不可变的。
- 选择器添加要求使用新标签更新部署规范中的pod模板标签,否则将返回验证错误。此更改是非重叠的,这意味着新选择器不会选择使用旧选择器创建的ReplicaSet和Pod,从而导致孤立所有旧ReplicaSet并创建新的ReplicaSet。
- 选择器更新 - 即更改选择器键中的现有值 - 导致与添加相同的行为。
- 选择器删除 - 即从部署选择器中删除现有密钥 - 不需要对pod模板标签进行任何更改。没有现有的ReplicaSet是孤立的,并且未创建新的ReplicaSet,但请注意,已删除的标签仍存在于任何现有的Pod和ReplicaSet中。
回滚部署
有时您可能想要回滚部署; 例如,当部署不稳定时,例如崩溃循环。默认情况下,所有Deployment的卷展栏历史记录都保留在系统中,以便您可以随时回滚(可以通过修改修订历史记录限制来更改)。
注意:触发Deployment的部署时会创建Deployment的修订版。这意味着当且仅当部署的pod模板(
.spec.template)发生更改时才会创建新修订,例如,如果更新模板的标签或容器图像。其他更新(例如扩展部署)不会创建部署版本,因此您可以方便地同时进行手动或自动扩展。这意味着当您回滚到早期版本时,仅回滚Deployment的pod模板部分。
假设您在更新部署时输入了拼写错误,方法是将图像名称nginx:1.91替换为nginx:1.9.1:
1 | $ kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.91 --record=true |
推出将被卡住。1
2$ kubectl rollout status deployment.v1.apps/nginx-deployment
Waiting for rollout to finish: 1 out of 3 new replicas have been updated...
按Ctrl-C可停止上面的卷展状态监视。有关卡片推出的更多信息, 请在此处阅读更多信息。
您将看到旧副本的数量(nginx-deployment-1564180365和nginx-deployment-2035384211)为2,新副本(nginx-deployment-3066724191)为1。1
2
3
4
5$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1564180365 3 3 3 25s
nginx-deployment-2035384211 0 0 0 36s
nginx-deployment-3066724191 1 1 0 6s
查看创建的Pod,您将看到由新ReplicaSet创建的1 Pod陷入图像拉环。1
2
3
4
5
6$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-1564180365-70iae 1/1 Running 0 25s
nginx-deployment-1564180365-jbqqo 1/1 Running 0 25s
nginx-deployment-1564180365-hysrc 1/1 Running 0 25s
nginx-deployment-3066724191-08mng 0/1 ImagePullBackOff 0 6s
注意: Deployment控制器将自动停止错误的卷展栏,并将停止扩展新的ReplicaSet。这取决于maxUnavailable您指定的rollingUpdate参数(特别是)。默认情况下,Kubernetes将值设置为25%。
1 | $ kubectl describe deployment |
要解决此问题,您需要回滚到稳定的以前版本的Deployment。
检查部署的部署历史记录
首先,检查此部署的修订版:1
2
3
4
5
6$ kubectl rollout history deployment.v1.apps/nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl create --filename=https://k8s.io/examples/controllers/nginx-deployment.yaml --record=true
2 kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true
3 kube ctl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.91 --record=true
CHANGE-CAUSEkubernetes.io/change-cause在创建时从部署批注复制到其修订版。您可以CHANGE-CAUSE通过以下方式指定消息:
- 注释部署
kubectl annotate deployment.v1.apps/nginx-deployment kubernetes.io/change-cause="image updated to 1.9.1" - 附加
--record标志以保存kubectl对资源进行更改的命令。 - 手动编辑资源的清单。
要进一步查看每个修订的详细信息,请运行:1
2
3
4
5
6
7
8
9
10
11
12
13
14$ kubectl rollout history deployment.v1.apps/nginx-deployment --revision=2
deployments "nginx-deployment" revision 2
Labels: app=nginx
pod-template-hash=1159050644
Annotations: kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
QoS Tier:
cpu: BestEffort
memory: BestEffort
Environment Variables: <none>
No volumes.
回滚到以前的版本
现在,您已决定撤消当前的卷展栏并回滚到上一版本:1
2$ kubectl rollout undo deployment.v1.apps/nginx-deployment
deployment.apps/nginx-deployment
或者,您可以通过在--to-revision以下位置指定回滚到特定修订:1
2$ kubectl rollout undo deployment.v1.apps/nginx-deployment --to-revision=2
deployment.apps/nginx-deployment
有关与推出相关的命令的更多详细信息,请阅读kubectl rollout。
部署现在回滚到以前的稳定版本。如您所见,DeploymentRollback从Deployment控制器生成用于回滚到版本2 的事件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46$ kubectl get deployment nginx-deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 30m
$ kubectl describe deployment nginx-deployment
Name: nginx-deployment
Namespace: default
CreationTimestamp: Sun, 02 Sep 2018 18:17:55 -0500
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision=4
kubernetes.io/change-cause=kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1 --record=true
Selector: app=nginx
Replicas: 3 desired | 3 updated | 3 total | 3 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=nginx
Containers:
nginx:
Image: nginx:1.9.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: nginx-deployment-c4747d96c (3/3 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 12m deployment-controller Scaled up replica set nginx-deployment-75675f5897 to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 2
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 1
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-c4747d96c to 3
Normal ScalingReplicaSet 11m deployment-controller Scaled down replica set nginx-deployment-75675f5897 to 0
Normal ScalingReplicaSet 11m deployment-controller Scaled up replica set nginx-deployment-595696685f to 1
Normal DeploymentRollback 15s deployment-controller Rolled back deployment "nginx-deployment" to revision 2
Normal ScalingReplicaSet 15s deployment-controller Scaled down replica set nginx-deployment-595696685f to 0
扩展部署
您可以使用以下命令扩展部署:1
2$ kubectl scale deployment.v1.apps/nginx-deployment --replicas=10
deployment.apps/nginx-deployment scaled
假设在群集中启用了水平pod自动缩放,则可以为Deployment设置自动缩放器,并根据现有Pod的CPU利用率选择要运行的最小和最大Pod数。
1 | $ kubectl autoscale deployment.v1.apps/nginx-deployment --min=10 --max=15 --cpu-percent=80 |
比例缩放
RollingUpdate Deployments支持同时运行多个版本的应用程序。当您或自动扩展器扩展正在部署(正在进行或暂停)的RollingUpdate部署时,部署控制器将平衡现有活动副本集(具有Pod的副本集)中的其他副本,以降低风险。这称为比例缩放。
例如,您正在运行具有10个副本的部署,maxSurge = 3和maxUnavailable = 2。1
2
3$ kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 10 10 10 10 50s
您更新到一个新的映像,该映像恰好在集群内部无法解析。1
2$ kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:sometag
deployment.apps/nginx-deployment image updated
图像更新使用ReplicaSet nginx-deployment-1989198191开始新的部署,但由于maxUnavailable您在上面提到的要求而被阻止 。1
2
3
4$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 5 5 0 9s
nginx-deployment-618515232 8 8 8 1m
然后出现一个新的部署扩展请求。自动缩放器将部署副本增加到15.部署控制器需要决定在哪里添加这些新的5个副本。如果您没有使用比例缩放,则所有5个都将添加到新的ReplicaSet中。通过比例缩放,您可以在所有ReplicaSet上传播其他副本。具有最多副本的ReplicaSets和较低比例的较大比例将转到具有较少副本的ReplicaSet。任何剩余物都会添加到具有最多副本的ReplicaSet中。零副本的ReplicaSet不会按比例放大。
在上面的示例中,3个副本将添加到旧的ReplicaSet中,2个副本将添加到新的ReplicaSet中。假设新副本变得健康,推出过程最终应将所有副本移动到新的ReplicaSet。1
2
3
4
5
6
7$ kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 15 18 7 8 7m
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1989198191 7 7 0 7m
nginx-deployment-618515232 11 11 11 7m
暂停和恢复部署
您可以在触发一个或多个更新之前暂停部署,然后恢复它。这将允许您在暂停和恢复之间应用多个修复,而不会触发不必要的部署。
例如,使用刚刚创建的部署:1
2
3
4
5
6$ kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 3 3 3 3 1m
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 1m
通过运行以下命令暂停:1
2$ kubectl rollout pause deployment.v1.apps/nginx-deployment
deployment.apps/nginx-deployment paused
然后更新部署的映像:1
2$ kubectl set image deployment.v1.apps/nginx-deployment nginx=nginx:1.9.1
deployment.apps/nginx-deployment image updated
请注意,没有新的卷展栏开始:1
2
3
4
5
6
7
8$ kubectl rollout history deployment.v1.apps/nginx-deployment
deployments "nginx"
REVISION CHANGE-CAUSE
1 <none>
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-2142116321 3 3 3 2m
您可以根据需要进行更多更新,例如,更新将使用的资源:1
2$ kubectl set resources deployment.v1.apps/nginx-deployment -c=nginx --limits=cpu=200m,memory=512Mi
deployment.apps/nginx-deployment resource requirements updated
暂停之前部署的初始状态将继续其功能,但只要部署暂停,部署的新更新将不会产生任何影响。
最后,恢复部署并观察一个新的ReplicaSet,提供所有新的更新:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23$ kubectl rollout resume deployment.v1.apps/nginx-deployment
deployment.apps/nginx-deployment resumed
$ kubectl get rs -w
NAME DESIRED CURRENT READY AGE
nginx-2142116321 2 2 2 2m
nginx-3926361531 2 2 0 6s
nginx-3926361531 2 2 1 18s
nginx-2142116321 1 2 2 2m
nginx-2142116321 1 2 2 2m
nginx-3926361531 3 2 1 18s
nginx-3926361531 3 2 1 18s
nginx-2142116321 1 1 1 2m
nginx-3926361531 3 3 1 18s
nginx-3926361531 3 3 2 19s
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 1 1 2m
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 20s
^C
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-2142116321 0 0 0 2m
nginx-3926361531 3 3 3 28s
注意:在恢复暂停部署之前,无法回滚暂停部署。
部署状态
部署在其生命周期中进入各种状态。它可以前进,同时推出新ReplicaSet,也可以是完整的,也可以不取得进展。
进步部署
当执行以下任务之一时,Kubernetes将部署标记为进度:
- 部署创建一个新的ReplicaSet。
- 部署正在扩展其最新的ReplicaSet。
- 部署正在缩减其旧的ReplicaSet。
- 新Pod已准备就绪或可用(至少准备MinReadySeconds)。
您可以使用监视部署的进度kubectl rollout status。
完成部署
Kubernetes 在具有以下特征时将部署标记为完成:
- 与部署关联的所有副本都已更新为您指定的最新版本,这意味着您已请求的任何更新已完成。
- 可以使用与部署关联的所有副本。
- 没有旧的部署副本正在运行。
您可以使用检查部署是否已完成kubectl rollout status。如果卷展栏成功完成,则kubectl rollout status返回零退出代码。
1 | kubectl rollout status deployment.v1.apps/nginx-deployment |
部署失败
您的部署可能会在尝试部署其最新的ReplicaSet时遇到困难,而无需完成。这可能是由于以下一些因素造成的:
- 配额不足
- 准备探针失败
- 图像拉错误
- 权限不足
- 限制范围
- 应用程序运行时配置错误
检测此情况的一种方法是在部署规范中指定截止时间参数:(.spec.progressDeadlineSeconds)。.spec.progressDeadlineSeconds表示部署控制器在指示(在“部署”状态中)部署进度已停止之前等待的秒数。
以下kubectl命令设置规范progressDeadlineSeconds以使控制器报告在10分钟后缺少部署进度:
1 | $ kubectl patch deployment.v1.apps/nginx-deployment -p '{"spec":{"progressDeadlineSeconds":600}}' |
超过截止日期后,Deployment控制器会向Deployment部署一个具有以下属性的DeploymentCondition .status.conditions:
- 类型=进展
- 状态=假
- 原因= ProgressDeadlineExceeded
有关状态条件的更多信息,请参阅Kubernetes API约定。
注意:除了报告状态条件之外,Kubernetes不对停顿的部署采取任何操作
Reason=ProgressDeadlineExceeded。更高级别的协调器可以利用它并相应地采取相应措施,例如,将部署回滚到其先前版本。
注意:如果您暂停部署,Kubernetes不会根据您指定的截止日期检查进度。您可以安全地在部署和暂停期间暂停部署,而不会触发超出截止日期的条件。
由于您设置的超时时间较短或者由于任何其他可被视为瞬态的错误,您可能会遇到部署的暂时性错误。例如,假设您的配额不足。如果您描述部署,您将注意到以下部分:
1 | $ kubectl describe deployment nginx-deployment |
如果您运行kubectl get deployment nginx-deployment -o yaml,部署状态可能如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25status:
availableReplicas: 2
conditions:
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: Replica set "nginx-deployment-4262182780" is progressing.
reason: ReplicaSetUpdated
status: "True"
type: Progressing
- lastTransitionTime: 2016-10-04T12:25:42Z
lastUpdateTime: 2016-10-04T12:25:42Z
message: Deployment has minimum availability.
reason: MinimumReplicasAvailable
status: "True"
type: Available
- lastTransitionTime: 2016-10-04T12:25:39Z
lastUpdateTime: 2016-10-04T12:25:39Z
message: 'Error creating: pods "nginx-deployment-4262182780-" is forbidden: exceeded quota:
object-counts, requested: pods=1, used: pods=3, limited: pods=2'
reason: FailedCreate
status: "True"
type: ReplicaFailure
observedGeneration: 3
replicas: 2
unavailableReplicas: 2
最终,一旦超出部署进度截止日期,Kubernetes将更新状态和进度条件的原因:1
2
3
4
5
6Conditions:
Type Status Reason
- ------ ------
Available True MinimumReplicasAvailable
Progressing False ProgressDeadlineExceeded
ReplicaFailure True FailedCreate
您可以通过缩小部署,缩小可能正在运行的其他控制器或增加命名空间中的配额来解决配额不足的问题。如果您满足配额条件,然后部署控制器完成“部署”卷展栏,您将看到部署状态更新成功条件(Status=True和Reason=NewReplicaSetAvailable)。1
2
3
4
5Conditions:
Type Status Reason
- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
Type=Available与Status=True您的部署具有最小可用性手段。最低可用性由部署策略中指定的参数决定。Type=Progressing和 Status=True表示您的部署正处于推出过程中并且正在进行中或已成功完成其进度并且所需的最小新副本可用(请参阅详细信息的条件原因 - 在我们的情况下 Reason=NewReplicaSetAvailable意味着部署完成)。
您可以使用检查部署是否未能进展kubectl rollout status。kubectl rollout status 如果部署已超过进度截止日期,则返回非零退出代码。
1 | $ kubectl rollout status deployment.v1.apps/nginx-deployment |
在失败的部署上运行
适用于完整部署的所有操作也适用于失败的部署。如果需要在“部署”窗格模板中应用多个调整,可以向上/向下缩放,回滚到以前的版本,甚至可以暂停它。
清理政策
您可以.spec.revisionHistoryLimit在部署中设置字段,以指定要保留此部署的旧ReplicaSet数。其余的将在后台进行垃圾收集。默认情况下,它是10。
注意:将此字段显式设置为0将导致清理部署的所有历史记录,从而部署将无法回滚。
用例
Canary部署
如果要使用部署将发布部署到用户或服务器的子集,则可以按照管理资源中描述的canary模式创建多个部署,每个版本一个 。
编写部署规范
与所有其他Kubernetes CONFIGS,部署需求apiVersion,kind以及metadata各个领域。有关使用配置文件的一般信息,请参阅部署应用程序,配置容器以及使用kubectl管理资源文档。
部署还需要一个.spec部分。
Pod模板
这.spec.template是唯一必需的领域.spec。
这.spec.template是一个pod模板。它与Pod具有完全相同的架构,除了它是嵌套的并且没有 apiVersion或kind。
除了Pod的必填字段外,部署中的pod模板还必须指定适当的标签和适当的重新启动策略。对于标签,请确保不要与其他控制器重叠。见选择器)。
只允许.spec.template.spec.restartPolicy等于Always,如果未指定,则为默认值。
副本
.spec.replicas是一个可选字段,指定所需Pod的数量。默认为1。
选择
.spec.selector是一个可选字段,用于指定 此部署所针对的Pod 的标签选择器。
.spec.selector必须匹配.spec.template.metadata.labels,否则它将被API拒绝。
在API版本apps/v1,.spec.selector并且.metadata.labels不默认.spec.template.metadata.labels,如果没有设置。所以必须明确设置它们。另请注意,.spec.selector在创建部署后,它是不可变的apps/v1。
部署可以终止其标签与选择器匹配的Pod,如果它们的模板不同.spec.template或者此类Pod的总数超过.spec.replicas。.spec.template如果Pod 的数量小于所需的数量,它会调出新的Pod 。
注意:您不应通过创建另一个部署或通过创建另一个控制器(如ReplicaSet或ReplicationController)来创建其标签与此选择器匹配的其他pod。如果您这样做,第一个部署认为它创建了这些其他pod。Kubernetes并没有阻止你这样做。
如果您有多个具有重叠选择器的控制器,控制器将相互争斗并且行为不正确。
战略
.spec.strategy指定用于替换旧Pod的策略。 .spec.strategy.type可以是“重新创建”或“RollingUpdate”。“RollingUpdate”是默认值。
重新创建部署
所有现有的Pod都会在创建新的Pod之前被杀死.spec.strategy.type==Recreate。
滚动更新部署
部署时会以滚动更新 方式更新Pod .spec.strategy.type==RollingUpdate。您可以指定maxUnavailable并maxSurge控制滚动更新过程。
maxUnavailable
.spec.strategy.rollingUpdate.maxUnavailable是一个可选字段,指定更新过程中可用的最大Pod数。该值可以是绝对数(例如,5)或所需Pod的百分比(例如,10%)。通过四舍五入计算绝对数字的百分比。如果.spec.strategy.rollingUpdate.maxSurge为0,则该值不能为0.默认值为25%。
例如,当此值设置为30%时,旧的ReplicaSet可以在滚动更新开始时立即按比例缩小到所需Pod的70%。准备好新的Pod后,可以进一步缩小旧的ReplicaSet,然后扩展新的ReplicaSet,确保在更新期间始终可用的Pod总数至少是所需Pod的70%。
Max Surge
.spec.strategy.rollingUpdate.maxSurge是一个可选字段,指定可以在所需数量的Pod上创建的最大Pod数。该值可以是绝对数(例如,5)或所需Pod的百分比(例如,10%)。如果MaxUnavailable为0,则该值不能为0.绝对数量是通过向上舍入的百分比计算的。默认值为25%。
例如,当此值设置为30%时,可以在滚动更新开始时立即按比例放大新的ReplicaSet,这样旧的和新的Pod的总数不会超过所需Pod的130%。一旦旧的Pod被杀死,新的ReplicaSet可以进一步扩展,确保在更新期间随时运行的Pod总数最多为所需Pod的130%。
进度截止日期
.spec.progressDeadlineSeconds是一个可选字段,指定在系统报告部署失败进度之前等待部署进度的秒数 - 表示为带有Type=Progressing,Status=False。的条件。以及Reason=ProgressDeadlineExceeded资源的状态。部署控制器将继续重试部署。将来,一旦实现自动回滚,部署控制器将在观察到这种情况后立即回滚部署。
如果指定,则此字段必须大于.spec.minReadySeconds。
Min Ready Seconds
.spec.minReadySeconds是一个可选字段,指定新创建的Pod应该在没有任何容器崩溃的情况下准备好的最小秒数,以使其可用。默认为0(Pod一旦准备好就会被视为可用)。要了解有关何时认为Pod已准备就绪的详细信息,请参阅容器探测器。
回滚
现场.spec.rollbackTo已被弃用的API版本extensions/v1beta1和apps/v1beta1,并在API版本不再支持开始apps/v1beta2。相反,应该使用回滚到先前版本中的kubectl rollout undo介绍。
修订历史限制
部署的修订历史记录存储在它控制的副本集中。
.spec.revisionHistoryLimit是一个可选字段,指定要保留以允许回滚的旧ReplicaSet的数量。其理想值取决于新部署的频率和稳定性。如果未设置此字段,则默认情况下将保留所有旧的ReplicaSet,消耗资源etcd并拥挤输出kubectl get rs。每个Deployment修订版的配置都存储在其ReplicaSet中; 因此,一旦删除旧的ReplicaSet,您将无法回滚到该部署版本。
更具体地说,将此字段设置为零意味着将清除所有具有0副本的旧ReplicaSet。在这种情况下,无法撤消新的“部署”卷展栏,因为它的修订历史记录已清除。
已暂停
.spec.paused是一个可选的布尔字段,用于暂停和恢复部署。暂停部署与未暂停部署之间的唯一区别是,暂停部署的PodTemplateSpec的任何更改都不会触发新的部署,只要它暂停即可。默认情况下,部署在创建时不会暂停。
部署的替代方案
kubectl滚动更新
kubectl rolling update以类似的方式更新Pod和ReplicationControllers。但建议使用部署,因为它们是声明性的,服务器端,并且具有其他功能,例如即使在滚动更新完成后回滚到任何先前的修订版。