框架相关(Spring)
Spring源码看过没有,会多少讲多少?
灵魂问题,,,自己发挥
各个组件
Resource
是对资源的抽象,每一个接口实现类都代表了一种资源类型,如 ClasspathResource 、 URLResource , FileSystemResource 等。每一个资源类型都封装了对某一种特定资源的访问策略。它是 spring 资源访问策略的一个基础实现,应用在很多场景。
BeanDefinition
用来抽象和描述一个具体 bean 对象。是描述一个 bean 对象的基本数据结构。
BeanDefinitionReader
BeanDefinitionReader 将外部资源对象描述的 bean 定义统一转化为统一的内部数据结构 BeanDefinition 。对应不同的描述需要有不同的 Reader 。如 XmlBeanDefinitionReader 用来读取 xml 描述配置的 bean 对象。

BeanFactory
用来定义一个很纯粹的 bean 容器。它是一个 bean 容器的必备结构。同时和外部应用环境等隔离。 BeanDefinition 是它的基本数据结构。它维护一个 BeanDefinitions Map, 并可根据 BeanDefinition 的描述进行 bean 的创建和管理。

ApplicationContext
从名字来看叫应用上下文,是和应用环境息息相关的。没错这个就是我们平时开发中经常直接使用打交道的一个类,应用上下文,或者也叫做 spring 容器。其实它的基本实现是会持有一个 BeanFactory 对象,并基于此提供一些包装和功能扩展。为什么要这么做呢?因为 BeanFactory 实现了一个容器基本结构和功能,但是与外部环境隔离。那么读取配置文件,并将配置文件解析成 BeanDefinition ,然后注册到 BeanFactory 的这一个过程的封装自然就需要 ApplicationContext 。 ApplicationContext 和应用环境细细相关,常见实现有 ClasspathXmlApplicationContext,FileSystemXmlApplicationContext,WebApplicationContext 等。 Classpath 、 xml 、 FileSystem 、 Web 等词都代表了应用和环境相关的一些意思,从字面上不难理解各自代表的含义。
当然 ApplicationContext 和 BeanFactory 的区别远不止于此,有:
资源访问功能:在 Resource 和 ResourceLoader 的基础上可以灵活的访问不同的资源。
支持不同的信息源。
支持应用事件:继承了接口 ApplicationEventPublisher ,这样在上下文中为 bean 之间提供了事件机制。

以上 5 个组件基本代表了 ioc 容器的一个最基本组成,而组件的组合是放在 ApplicationContext 的实现这一层来完成。

左边黄色部分是 ApplicationContext 体系继承结构,右边是 BeanFactory 的结构体系,两个结构是典型模板方法设计模式的使用。
从该继承体系可以看出:
BeanFactory 是一个 bean 工厂的最基本定义,里面包含了一个 bean 工厂的几个最基本的方法, getBean(…) 、 containsBean(…) 等 ,是一个很纯粹的bean工厂,不关注资源、资源位置、事件等。 ApplicationContext 是一个容器的最基本接口定义,它继承了 BeanFactory, 拥有工厂的基本方法。同时继承了 ApplicationEventPublisher 、 MessageSource 、 ResourcePatternResolver 等接口,使其 定义了一些额外的功能,如资源、事件等这些额外的功能。
AbstractBeanFactory 和 AbstractAutowireCapableBeanFactory 是两个模板抽象工厂类。 AbstractBeanFactory 提供了 bean 工厂的抽象基类,同时提供了 ConfigurableBeanFactory 的完整实现。 AbstractAutowireCapableBeanFactory 是继承了 AbstractBeanFactory 的抽象工厂,里面提供了 bean 创建的支持,包括 bean 的创建、依赖注入、检查等等功能,是一个核心的 bean 工厂基类。
ClassPathXmlApplicationContext之 所以拥有 bean 工厂的功能是通过持有一个真正的 bean 工厂 DefaultListableBeanFactory 的实例,并通过 代理 该工厂完成。
ClassPathXmlApplicationContext 的初始化过程是对本身容器的初始化同时也是对其持有的 DefaultListableBeanFactory 的初始化。
容器初始化过程

整个过程可以理解为是容器的初始化过程。第一个过程是 ApplicationContext 的职责范围,第二步是 BeanFactory 的职责范围。可以看出 ApplicationContext 是一个运行时的容器需要提供不容资源环境的支持,屏蔽不同环境的差异化。而 BeanDifinition 是内部关于 bean 定义的基本结构。 Bean 的创建就是基于它,回头会介绍一下改结构的定义。下面看一下整个容器的初始化过程。
容器的初始化是通过调用 refresh() 来实现。该方法是非常重要的一个方法,定义在 AbstractApplicationContext 接口里。 AbstractApplicationContext 是容器的最基础的一个抽象父类。也就是说在该里面定义了一个容器初始化的基本流程,流程里的各个方法有些有提供了具体实现,有些是抽象的 ( 因为不同的容器实例不一样 ) ,由继承它的每一个具体容器完成定制。看看 refresh 的基本流程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
beanFactory.destroySingletons();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
}
}

Bean 的创建过程
Bean的创建过程基本是BeanFactory所要完成的事情.
根据以上过程,将会重点带着以下两个个问题来理解核心代码:
1.Bean 的创建时机
bean 是在什么时候被创建的,有哪些规则。
2.Bean 的创建过程
bean 是怎么创建的,会选择哪个构造函数?依赖如何注入? InitializingBean 的 set 方法什么时候被调用?实现 ApplicationContextAware, BeanFactoryAware,BeanNameAware, ResourceLoaderAware 这些接口的 bean 的 set 方法何时被调用?
在解释这两个问题前,先看一下 BeanDefinition 接口的定义。
从该接口定义可以看出,通过 bean 定义能够得到 bean 的详细信息,如类名子、工厂类名称、 scope 、是否单例、是否抽象、是否延迟加载等等。基于此,来看一下以下两个问题:
问题 1 : Bean 的创建时机
bean 是在什么时候被创建的,有哪些规则?
容器初始化的时候会预先对单例和非延迟加载的对象进行预先初始化。其他的都是延迟加载是在第一次调用 getBean 的时候被创建。从 DefaultListableBeanFactory 的 preInstantiateSingletons 里可以看到这个规则的实现。
1 | public void preInstantiateSingletons() throws BeansException { |
从上面来看对于以下配置,只有 singletonBean 会被预先创建。1
2
3
4
5
6
7xml version="1.0" encoding="GB2312"
<beans default-autowire="byName">
<bean id="otherBean" class="com.test.OtherBean" scope="prototype"/>
<bean id="myBean" class="com.test.MyBean" lazy-init="true"/>
<bean id="singletonBean" class="com.test.SingletonBean"/>
</beans>
问题二:Bean 的创建过程
对于 bean 的创建过程其实都是通过调用工厂的 getBean 方法来完成的。这里面将会完成对构造函数的选择、依赖注入等。
无论预先创建还是延迟加载都是调用getBean实现,AbstractBeanFactory 定义了 getBean 的过程:
1 | protected Object doGetBean( |
GetBean 的大概过程:
1.先试着从单例缓存对象里获取。
2.从父容器里取定义,有则由父容器创建。
3.如果是单例,则走单例对象的创建过程:在 spring 容器里单例对象和非单例对象的创建过程是一样的。都会调用父类 AbstractAutowireCapableBeanFactory 的 createBean 方法。 不同的是单例对象只创建一次并且需要缓存起来。 DefaultListableBeanFactory 的父类 DefaultSingletonBeanRegistry 提供了对单例对象缓存等支持工作。所以是单例对象的话会调用 DefaultSingletonBeanRegistry 的 getSingleton 方法,它会间接调用 AbstractAutowireCapableBeanFactory 的 createBean 方法。
如果是 Prototype 多例则直接调用父类 AbstractAutowireCapableBeanFactory 的 createBean 方法。
bean的创建是由AbstractAutowireCapableBeanFactory来定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37protected Object createBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
AccessControlContext acc = AccessController.getContext();
return AccessController.doPrivileged(new PrivilegedAction() {
public Object run() {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
// Make sure bean class is actually resolved at this point.
resolveBeanClass(mbd, beanName);
// Prepare method overrides.
try {
mbd.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbd.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
Object bean = resolveBeforeInstantiation(beanName, mbd);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
Object beanInstance = doCreateBean(beanName, mbd, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
}, acc);
}
createBean 会调用 doCreateBean 方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args) {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = (BeanWrapper) this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
Class beanType = (instanceWrapper != null ? instanceWrapper.getWrappedClass() : null);
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
addSingletonFactory(beanName, new ObjectFactory() {
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set actualDependentBeans = new LinkedHashSet(dependentBeans.length);
for (int i = 0; i < dependentBeans.length; i++) {
String dependentBean = dependentBeans[i];
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
registerDisposableBeanIfNecessary(beanName, bean, mbd);
return exposedObject;
}
doCreateBean 的流程:
1.会创建一个 BeanWrapper 对象 用于存放实例化对象。
2.如果没有指定构造函数,会通过反射拿到一个默认的构造函数对象,并赋予 beanDefinition.resolvedConstructorOrFactoryMethod 。
3.调用 spring 的 BeanUtils 的 instantiateClass 方法,通过反射创建对象。
4.applyMergedBeanDefinitionPostProcessors
5.populateBean(beanName, mbd, instanceWrapper); 根据注入方式进行注入。根据是否有依赖检查进行依赖检查。
执行 bean 的注入里面会选择注入类型:
1 | if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME || |
6.initializeBean(beanName, exposedObject, mbd);
判断是否实现了 BeanNameAware 、 BeanClassLoaderAware 等 spring 提供的接口,如果实现了,进行默认的注入。同时判断是否实现了 InitializingBean 接口,如果是的话,调用 afterPropertySet 方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32protected Object initializeBean(String beanName, Object bean, RootBeanDefinition mbd) {
(bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
(bean instanceof BeanClassLoaderAware) {
((BeanClassLoaderAware) bean).setBeanClassLoader(getBeanClassLoader());
}
(bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(this);
}
Object wrappedBean = bean;
(mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
(mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
其中invokeInitMethods实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21protected void invokeInitMethods(String beanName, Object bean, RootBeanDefinition mbd)
throws Throwable {
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null || !mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isDebugEnabled()) {
logger.debug("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
((InitializingBean) bean).afterPropertiesSet();//调用afterPropertiesSet方法
}
String initMethodName = (mbd != null ? mbd.getInitMethodName() : null);
if (initMethodName != null && !(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, initMethodName, mbd.isEnforceInitMethod());
}
}
Spring xml ioc 容器常用标签和自定义标签
以 Xml 资源定义的容器配置是我们最常见的一种方式。
Spring 容器需要解析 xml 的标签,并把 xml 里 bean 的定义转化为内部的结构 BeanDifinition 。
Spring 的标签有很多种,其支持的常见的标签有:
| 标签 | 说明 | 例子 |
|---|---|---|
<bean> |
最常用的,定义一个普通 bean。 | <bean id="myBean" class="com.test.MyBean" lazy-init="true"/> |
<tx> |
如<tx: advice> 等,提供事务配置通用支持。 |
<tx:advice id="txAdvice"transaction-manager="transactionManager"> <tx:attributes> <tx:method name="save*"/> <tx:method name="remove*"/> <tx:method name="*" read-only="true"/> </tx:attributes> </tx:advice> |
<aop> |
<aop:config>,<aop: aspectj-autoproxy> 等提供代理 bean 通用配置支持。 |
<aop:configproxy-target-class="true"> <aop:advisor pointcut="..." advice-ref="txAdvice"/> <aop:advisorpointcut="..." advice-ref="fooAdvice"/> </aop:config> |
<util> |
提供在容器内配置一些JDK自带的工具类、集合类和常量的支持。 | <util:list id="list"list-class="java.util.ArrayList"><value>listValue1</value> <value>listValue2</value> </util:list> <util:map id="map"> <entry key="key1" value="mapValue1"></entry><entry key="key12" value="mapValue2"></entry> </util:map> |
<p> |
属性的简单访问。 | <bean id="loginAction" class="com.test.LoginAction" p:name="test"></bean> |
<lang> |
<lang:groovy> <lang:jruby>等,提供对动态脚本的支持。 |
<lang:groovy id="test" refresh-check-delay="5000" script-source="classpath:com/test/groovy/test.groovy"> </lang:groovy> |
<jee> |
<jee:jndi-lookup/>等,对一些javaEE规范的bean配置的简化,如jndi等。 |
<jee:jndi-lookup id="simple" jndi-name="jdbc/MyDataSource" cache="true" resource-ref="true" lookup-on-startup="false" expected-type="com.myapp.DefaultFoo" proxy-interface="com.myapp.Foo"/> |
基本上每一种标签都是用来定义一类 bean 的(P标签除外)。以上都是 spring 自带的一些标签,当然 spring 也支持自定义标签。其实 <tx><aop> 这些也可以认为是自定义标签,不过是由 spring 扩展的而已。
其实所有的bean定义都可以用bean标签来实现定义的。而衍生这种自定义标签来定义 bean 有几个好处:
见名知意。
对于同一类的通用 bean。封装不必要的配置,只给外部暴露一个简单易用的标签和一些需要配置的属性。很多时候对于一个框架通用的 bean ,我们不需要把 bean 的所有配置都暴露出来,甚至像类名、默认值等我们都想直接封装,这个时候就可以使用自定义标签了,如: <services:property-placeholder /> 可能这个标签就默认代表配置了一个支持 property placeholder 的通用 bean ,我们都不需要去知道配这样一个 bean 的类路径是什么。
可以说自定义标签是 spring 的 xml 容器的一个扩展点,本身 spring 自己的很多标签也是基于这个设计上面来构造出来的。
Spring 对于自定义(声明式)bean标签解析如何设计
Bean 的定义方式有千千万万种,无论是何种标签,无论是何种资源定义,无论是何种容器,最终的 bean 定义内部表示都将转换为内部的唯一结构: BeanDefinition 。外部的各种定义说白了就是为了方便配置。
Spring 提供对其支持的标签解析的天然支持。所以只要按照 spring 的规范编写 xml 配置文件。所有的配置,在启动时都会正常的被解析成 BeanDefinition 。但是如果我们要实现一个自定义标签,则需要提供对自定义标签的全套支持。
我们知道要去完成一个自定义标签,需要完成的事情有:
编写自定义标签 schema 定义文件,放在某个 classpath 下。
在 classpath 的在 META-INF 下面增加 spring.schemas 配置文件,指定 schema 虚拟路径和实际 xsd 的映射。我们在 xml 里的都是虚拟路径,如:
1 | xml version="1.0" encoding="UTF-8" |
头部的1
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
就是一个虚拟路径,其对应的真实路径在spring jar包里的META-INF/spring.schemas里面有映射到classpath定义:
1
http\://www.springframework.org/schema/beans/spring-beans-2.5.xsd=org/springframework/beans/factory/xml/spring-beans-2.5.xsd
- 增加一个 NamespaceHandler 和 BeanDefinitionParser ,用于解析自定义的标签,将自定义标签的 bean 解析成一个 BeanDefinition 返回。
在 classpath 的在 META-INF 下面增加 spring.handlers 配置文件,指定标签命名空间和 handlers 的映射。
为什么要做以上几个事情?我们来看看设计:
Spring 对标签解析的设计的过程如下:

解释:
Step 1: 将 xml 文件解析成 Dom 树。将 xml 文件解析成 dom 树的时候,需要 xml 标签定义 schema 来验证文件的语法结构。 Spring 约定将所有的 shema 的虚拟路径和真是文件路径映射定义在 classpath 的在 META-INF/spring.schemas 下面。在容器启动时 Spring 会扫描所有的 META-INF/spring.schemas 并将映射维护到一个 map 里。
如 spring jar 包里会有自带的标签的 schemas 映射,可以看一下部分配置:1
2
3
4
5
6
7
8
9
10
11http\://www.springframework.org/schema/aop/spring-aop-2.0.xsd = org/springframework/aop/config/spring-aop-2.0.xsd
http\://www.springframework.org/schema/aop/spring-aop-2.5.xsd = org/springframework/aop/config/spring-aop-2.5.xsd
http\://www.springframework.org/schema/aop/spring-aop.xsd = org/springframework/aop/config/spring-aop-2.5.xsd
http\://www.springframework.org/schema/beans/spring-beans-2.0.xsd = org/springframework/beans/factory/xml/spring-beans-2.0.xsd
http\://www.springframework.org/schema/beans/spring-beans-2.5.xsd = org/springframework/beans/factory/xml/spring-beans-2.5.xsd
http\://www.springframework.org/schema/beans/spring-beans.xsd = org/springframework/beans/factory/xml/spring-beans-2.5.xsd
http\://www.springframework.org/schema/context/spring-context-2.5.xsd = org/springframework/context/config/spring-context-2.5.xsd
http\://www.springframework.org/schema/context/spring-context.xsd = org/springframework/context/config/spring-context-2.5.xsd
http\://www.springframework.org/schema/jee/spring-jee-2.0.xsd = org/springframework/ejb/config/spring-jee-2.0.xsd
http\://www.springframework.org/schema/jee/spring-jee-2.5.xsd = org/springframework/ejb/config/spring-jee-2.5.xsd
......
等号左边是虚拟路径,右边是真是路径(classpath下的)。
虚拟路径用在我们的bean定义配置文件里,如:1
2
3
4
5
6
7
8<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-2.5.xsd>
<bean>
</beans>
beans里面的1
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
就是个虚拟路径。
Step 2: 将 dom 树解析成 BeanDifinition 。将定义 bean 的标签和 xml 定义解析成 BeanDefinition 的过程。如果是默认的 bean 标签, spring 会直接进行解析。而如果不是默认的 bean 标签,包括自定义和 spring 扩展的 <aop>、 <p>、 <util> 等标签,则需要提供专门的 xmlparser 来处理。 paorser由自己定义和编写,并通过handler注册到容器。Spring 约定了 META-INF/spring.handlers 文件,在这里面定义了标签命名空间和 handler 的映射。容器起来的时候会加载 handler , handler 会向容器注册该命名空间下的标签和解析器。在解析的自定义标签的时候, spring 会根据标签的命名空间和标签名找到一个解析器。由该解析器来完成对该标签内容的解析,并返回一个 BeanDefinition 。
以下是 spring jar 包自带的一些自定义标签扩展的 spring.handlers 文件,可以看到定义了 aop\p 等其扩展标签的 handlers 。1
2
3
4
5
6
7
8http\://www.springframework.org/schema/aop=org.springframework.aop.config.AopNamespaceHandler
http\://www.springframework.org/schema/context=org.springframework.context.config.ContextNamespaceHandler
http\://www.springframework.org/schema/jee=org.springframework.ejb.config.JeeNamespaceHandler
http\://www.springframework.org/schema/jms=org.springframework.jms.config.JmsNamespaceHandler
http\://www.springframework.org/schema/lang=org.springframework.scripting.config.LangNamespaceHandler
http\://www.springframework.org/schema/p=org.springframework.beans.factory.xml.SimplePropertyNamespaceHandler
http\://www.springframework.org/schema/tx=org.springframework.transaction.config.TxNamespaceHandler
http\://www.springframework.org/schema/util=org.springframework.beans.factory.xml.UtilNamespaceHandler
看看UtilNamespaceHandler的代码实现1
2
3
4
5
6
7
8public void init() {
registerBeanDefinitionParser("constant", new ConstantBeanDefinitionParser());
registerBeanDefinitionParser("property-path", new PropertyPathBeanDefinitionParser());
registerBeanDefinitionParser("list", new ListBeanDefinitionParser());
registerBeanDefinitionParser("set", new SetBeanDefinitionParser());
registerBeanDefinitionParser("map", new MapBeanDefinitionParser());
registerBeanDefinitionParser("properties", new PropertiesBeanDefinitionParser());
}
实现了标签和对应parser的映射注册。
ListBeanDefinitionParser的实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19private static class ListBeanDefinitionParser extends AbstractSingleBeanDefinitionParser {
protected Class getBeanClass(Element element) {
return ListFactoryBean.class;
}
protected void doParse(Element element, ParserContext parserContext, BeanDefinitionBuilder builder) {
String listClass = element.getAttribute("list-class");
List parsedList = parserContext.getDelegate().parseListElement(element, builder.getRawBeanDefinition());
builder.addPropertyValue("sourceList", parsedList);
if (StringUtils.hasText(listClass)) {
builder.addPropertyValue("targetListClass", listClass);
}
String scope = element.getAttribute(SCOPE_ATTRIBUTE);
if (StringUtils.hasLength(scope)) {
builder.setScope(scope);
}
}
}
这里父类代码不贴了,主要完成的是beanDifinition的生成。
源码实现
Spring 对于自定义(声明式)bean标签源码实现大概的源码结构如下:
XmlBeanDefinitionReader 是核心类,它接收 spring 容器传给它的资源 resource 文件,由它负责完成整个转换。它调用 DefaultDocumentLoader 来完成将 Resource 到 Dom 树的转换。调用 DefaultBeanDefinitionDocumentReader 完成将 Dom 树到 BeanDefinition 的转换。
具体的代码流程细节完全可以基于这个结构去阅读,下面就贴几个核心源码段:
源码段 1 : 加载 spring.shemas,在PluggableSchemaResolver.java里实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public class PluggableSchemaResolver implements EntityResolver {
/***定义schema location的映射文件路径***/
public static final String DEFAULT_SCHEMA_MAPPINGS_LOCATION = "META-INF/spring.schemas";
private static final Log logger = LogFactory.getLog(PluggableSchemaResolver.class);
private final ClassLoader classLoader;
private final String schemaMappingsLocation;
/** Stores the mapping of schema URL -> local schema path */
private Properties schemaMappings;
public PluggableSchemaResolver(ClassLoader classLoader) {
this.classLoader = classLoader;
this.schemaMappingsLocation = DEFAULT_SCHEMA_MAPPINGS_LOCATION;
}
public PluggableSchemaResolver(ClassLoader classLoader, String schemaMappingsLocation) {
Assert.hasText(schemaMappingsLocation, "'schemaMappingsLocation' must not be empty");
this.classLoader = classLoader;
this.schemaMappingsLocation = schemaMappingsLocation;
}
/**==========中间省略部分代码=========**/
/***此处完成schema的加载***/
protected String getSchemaMapping(String systemId) {
if (this.schemaMappings == null) {
if (logger.isDebugEnabled()) {
logger.debug("Loading schema mappings from [" + this.schemaMappingsLocation + "]");
}
try {
this.schemaMappings =
PropertiesLoaderUtils.loadAllProperties(this.schemaMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded schema mappings: " + this.schemaMappings);
}
}
catch (IOException ex) {
throw new FatalBeanException(
"Unable to load schema mappings from location [" + this.schemaMappingsLocation + "]", ex);
}
}
return this.schemaMappings.getProperty(systemId);
}
}
源码段 2 : 加载 spring.handlers,在 DefaultNamespaceHandlerResolver里实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56public class DefaultNamespaceHandlerResolver implements NamespaceHandlerResolver {
/**
* The location to look for the mapping files. Can be present in multiple JAR files.
*/
public static final String DEFAULT_HANDLER_MAPPINGS_LOCATION = "META-INF/spring.handlers";
/** Logger available to subclasses */
protected final Log logger = LogFactory.getLog(getClass());
/** ClassLoader to use for NamespaceHandler classes */
private final ClassLoader classLoader;
/** Resource location to search for */
private final String handlerMappingsLocation;
/** Stores the mappings from namespace URI to NamespaceHandler class name / instance */
private Map handlerMappings;
public DefaultNamespaceHandlerResolver() {
this(null, DEFAULT_HANDLER_MAPPINGS_LOCATION);
}
public DefaultNamespaceHandlerResolver(ClassLoader classLoader) {
this(classLoader, DEFAULT_HANDLER_MAPPINGS_LOCATION);
}
public DefaultNamespaceHandlerResolver(ClassLoader classLoader, String handlerMappingsLocation) {
Assert.notNull(handlerMappingsLocation, "Handler mappings location must not be null");
this.classLoader = (classLoader != null ? classLoader : ClassUtils.getDefaultClassLoader());
this.handlerMappingsLocation = handlerMappingsLocation;
}
/**==========中间省略部分代码=========**/
/************************
* Load the specified NamespaceHandler mappings lazily.
* 此处加载延迟加载spring.handlers,只有第一次自定义标签被解析到,才会被加载。
****************************/
private Map getHandlerMappings() {
if (this.handlerMappings == null) {
try {
Properties mappings =
PropertiesLoaderUtils.loadAllProperties(this.handlerMappingsLocation, this.classLoader);
if (logger.isDebugEnabled()) {
logger.debug("Loaded mappings [" + mappings + "]");
}
this.handlerMappings = new HashMap(mappings);
}
catch (IOException ex) {
IllegalStateException ise = new IllegalStateException(
"Unable to load NamespaceHandler mappings from location [" + this.handlerMappingsLocation + "]");
ise.initCause(ex);
throw ise;
}
}
return this.handlerMappings;
}
}
源码段3 : xml 到 dom 树的解析。
在 XmlBeanDefinitionReader.java 的 doLoadBeanDefinitions 方法里,调用 DefaultDocumentLoader 完成。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32protected int doLoadBeanDefinitions(InputSource inputSource, Resource resource)
throws BeanDefinitionStoreException {
try {
int validationMode = getValidationModeForResource(resource);
Document doc = this.documentLoader.loadDocument(
inputSource, getEntityResolver(), this.errorHandler, validationMode, isNamespaceAware());
return registerBeanDefinitions(doc, resource);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (SAXParseException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"Line " + ex.getLineNumber() + " in XML document from " + resource + " is invalid", ex);
}
catch (SAXException ex) {
throw new XmlBeanDefinitionStoreException(resource.getDescription(),
"XML document from " + resource + " is invalid", ex);
}
catch (ParserConfigurationException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Parser configuration exception parsing XML from " + resource, ex);
}
catch (IOException ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"IOException parsing XML document from " + resource, ex);
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(resource.getDescription(),
"Unexpected exception parsing XML document from " + resource, ex);
}
}
其中的1
getEntityResolver()
会完成spring.schemas的装载,里面会间接调用源码段1。穿进去的entityResolver作为标签解析使用。
源码段4 : dom 树到 Beandifinition:
在 XmlBeanDefinitionReader .java 的 doLoadBeanDefinitions 方法里,调用 BeanDefinitionDocumentReader 完成。
1 | public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException { |
AOP底层实现原理
代理设计模式
什么是代理模式
通过代理控制对象的访问,可以详细访问某个对象的方法,在这个方法调用处理,或调用后处理。既(AOP微实现) ,AOP核心技术面向切面编程。
代理模式应用场景
SpringAOP、事物原理、日志打印、权限控制、远程调用、安全代理 可以隐蔽真实角色
代理的分类
静态代理(静态定义代理类)
动态代理(动态生成代理类)
Jdk自带动态代理
Cglib 、javaassist(字节码操作库)
静态代理
什么是静态代理
由程序员创建或工具生成代理类的源码,再编译代理类。所谓静态也就是在程序运行前就已经存在代理类的字节码文件,代理类和委托类的关系在运行前就确定了。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public interface IUserDao {
void save();
}
public class UserDao implements IUserDao {
public void save() {
System.out.println("已经保存数据...");
}
}
代理类
public class UserDaoProxy implements IUserDao {
private IUserDao target;
public UserDaoProxy(IUserDao iuserDao) {
this.target = iuserDao;
}
public void save() {
System.out.println("开启事物...");
target.save();
System.out.println("关闭事物...");
}
}
什么是动态代理
1.代理对象,不需要实现接口
2.代理对象的生成,是利用JDK的API,动态的在内存中构建代理对象(需要我们指定创建代理对象/目标对象实现的接口的类型)
3.动态代理也叫做:JDK代理,接口代理
JDK动态代理
1)原理:是根据类加载器和接口创建代理类(此代理类是接口的实现类,所以必须使用接口 面向接口生成代理,位于java.lang.reflect包下)
2)实现方式:
通过实现InvocationHandler接口创建自己的调用处理器 IvocationHandler handler = new InvocationHandlerImpl(…);
通过为Proxy类指定ClassLoader对象和一组interface创建动态代理类Class clazz = Proxy.getProxyClass(classLoader,new Class[]{…});
通过反射机制获取动态代理类的构造函数,其参数类型是调用处理器接口类型Constructor constructor = clazz.getConstructor(new Class[]{InvocationHandler.class});
通过构造函数创建代理类实例,此时需将调用处理器对象作为参数被传入Interface Proxy = (Interface)constructor.newInstance(new Object[] (handler));
缺点:jdk动态代理,必须是面向接口,目标业务类必须实现接口1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 每次生成动态代理类对象时,实现了InvocationHandler接口的调用处理器对象
public class InvocationHandlerImpl implements InvocationHandler {
private Object target;// 这其实业务实现类对象,用来调用具体的业务方法
// 通过构造函数传入目标对象
public InvocationHandlerImpl(Object target) {
this.target = target;
}
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Object result = null;
System.out.println("调用开始处理");
result = method.invoke(target, args);
System.out.println("调用结束处理");
return result;
}
public static void main(String[] args) throws NoSuchMethodException, SecurityException, InstantiationException,
IllegalAccessException, IllegalArgumentException, InvocationTargetException {
// 被代理对象
IUserDao userDao = new UserDao();
InvocationHandlerImpl invocationHandlerImpl = new InvocationHandlerImpl(userDao);
ClassLoader loader = userDao.getClass().getClassLoader();
Class<?>[] interfaces = userDao.getClass().getInterfaces();
// 主要装载器、一组接口及调用处理动态代理实例
IUserDao newProxyInstance = (IUserDao) Proxy.newProxyInstance(loader, interfaces, invocationHandlerImpl);
newProxyInstance.save();
}
}
CGLIB动态代理
原理:利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
什么是CGLIB动态代理
使用cglib[Code Generation Library]实现动态代理,并不要求委托类必须实现接口,底层采用asm字节码生成框架生成代理类的字节码
CGLIB动态代理相关代码
1 | public class CglibProxy implements MethodInterceptor { |
CGLIB动态代理与JDK动态区别
java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
而cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
Spring中。
1、如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
2、如果目标对象实现了接口,可以强制使用CGLIB实现AOP
3、如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
JDK动态代理只能对实现了接口的类生成代理,而不能针对类 。 CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法 。 因为是继承,所以该类或方法最好不要声明成final ,final可以阻止继承和多态。
springcloud的整体架构
Eureka
心跳检测机制,如果某个实例在规定的时间内没有进行通讯则会自动被剔除掉,避免了某个实例挂掉而影响服务,Eureka就自动具有了注册中心、负载均衡、故障转移的功能。
Hystrix
Hystrix会在某个服务连续调用N次不响应的情况下,立即通知调用端调用失败,避免调用端持续等待而影响了整体服务。Hystrix间隔时间会再次检查此服务,如果服务恢复将继续提供服务。
Spring Cloud Config
解决分布式系统的配置管理方案。它包含了Client和Server两个部分,Server提供配置文件的存储、以接口的形式将配置文件的内容提供出去,Client通过接口获取数据、并依据此数据初始化自己的应用。
Spring Cloud Bus
通过轻量消息代理连接各个分布的节点。这会用在广播状态的变化(例如配置变化)或者其它的消息指令中。Spring Cloud Bus的一个核心思想是通过分布式的启动器对Spring Boot应用进行扩展,也可以用来建立一个或多个应用之间的通信频道。目前唯一实现的方式是用AMQP消息代理作为通道。 有了Spring Cloud Bus之后,当我们改变配置文件提交到版本库中时,会自动的触发对应实例的Refresh。
服务网关
Spring Cloud体系中支持API Gateway落地的技术就是Zuul。Spring Cloud Zuul路由是微服务架构中不可或缺的一部分,提供动态路由,监控,弹性,安全等的边缘服务。Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。 它的具体作用就是服务转发,接收并转发所有内外部的客户端调用。使用Zuul可以作为资源的统一访问入口,同时也可以在网关做一些权限校验等类似的功能。
链路跟踪
Spring Cloud Sleuth和Zipkin,Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长时间。从而让我们可以很方便的理清各微服务间的调用关系。Zipkin是Twitter的一个开源项目,允许开发者收集 Twitter 各个服务上的监控数据,并提供查询接口 。
Feign技术
利用此技术可以伪造接口实现。
负载均衡的算法有哪些
轮询(Round Robin)法
将所有请求,依次分发到每台服务器上,适合服务器硬件相同的场景。
- 优点:服务器请求数目相同;
- 缺点:服务器压力不一样,不适合服务器配置不同的情况,为了做到请求转移的绝对均衡,必须付出相当大的代价,因为为了保证pos变量修改的互斥性,需要引入重量级的悲观锁synchronized,这将会导致该段轮询代码的并发吞吐量发生明显的下降;
随机(Random)法
基于概率统计的理论,吞吐量越大,随机算法的效果越接近于轮询算法的效果。
- 优点:使用简单;
- 缺点:不适合机器配置不同的场景;
源地址哈希(Hash)法
源地址哈希的思想是获取客户端访问的IP地址值,通过哈希函数计算得到一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是要访问的服务器的序号。
- 优点:保证了相同客户端IP地址将会被哈希到同一台后端服务器,直到后端服务器列表变更。根据此特性可以在服务消费者与服务提供者之间建立有状态的session会话。
- 缺点:除非集群中服务器的非常稳定,基本不会上下线,否则一旦有服务器上线、下线,那么通过源地址哈希算法路由到的服务器是服务器上线、下线前路由到的服务器的概率非常低,如果是session则取不到session,如果是缓存则可能引发”雪崩”;
加权法
在轮询,随机,最少链接,Hash等算法的基础上,通过加权的方式,进行负载服务器分配。
- 优点:根据权重,调节转发服务器的请求数目;
- 缺点:使用相对复杂;
最小连接数(Least Connections)法
将请求分配到连接数最少的服务器上(目前处理请求最少的服务器)。
- 优点:根据服务器当前的请求处理情况,动态分配;
- 缺点:算法实现相对复杂,需要监控服务器请求连接数;
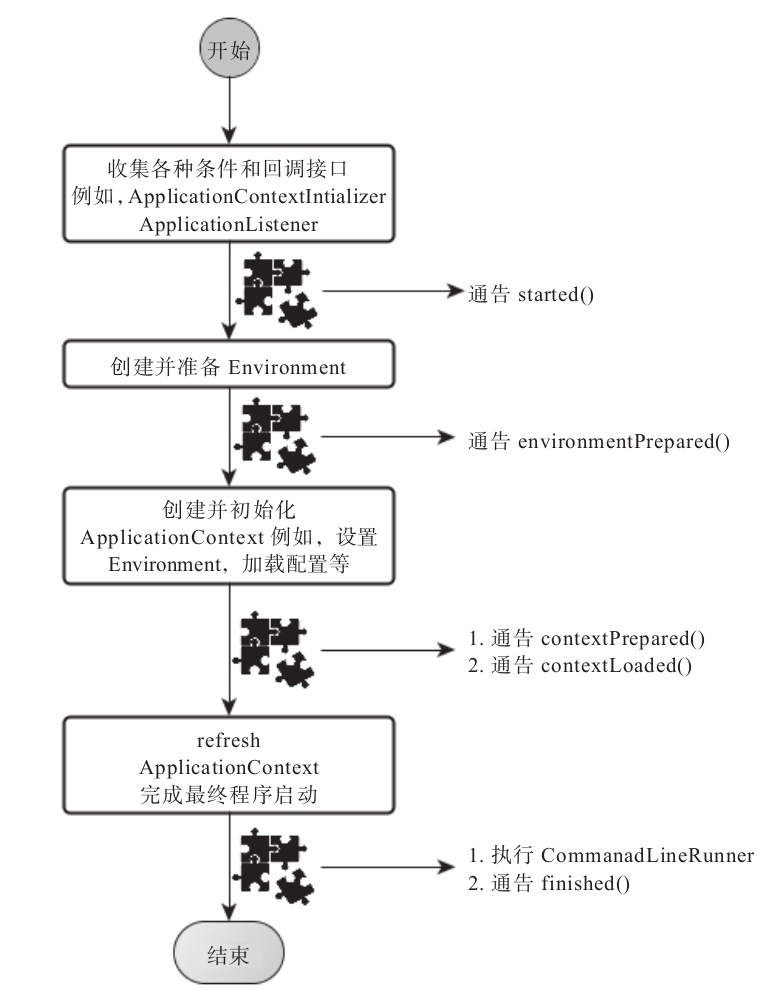
SpringBoot如何启动
- 如果我们使用的是SpringApplication的静态run方法,那么,这个方法里面首先要创建一个SpringApplication对象实例,然后调用这个创建好的SpringApplication的实例方法。在SpringApplication实例初始化的时候,它会提前做几件事情:
- 根据classpath里面是否存在某个特征类(org.springframework.web.context.ConfigurableWebApplicationContext)来决定是否应该创建一个为Web应用使用的ApplicationContext类型。
- 使用SpringFactoriesLoader在应用的classpath中查找并加载所有可用的ApplicationContextInitializer。
- 使用SpringFactoriesLoader在应用的classpath中查找并加载所有可用的ApplicationListener。
- 推断并设置main方法的定义类。
- SpringApplication实例初始化完成并且完成设置后,就开始执行run方法的逻辑了,方法执行伊始,首先遍历执行所有通过SpringFactoriesLoader可以查找到并加载的SpringApplicationRunListener。调用它们的started()方法,告诉这些SpringApplicationRunListener,“嘿,SpringBoot应用要开始执行咯!”。
- 创建并配置当前Spring Boot应用将要使用的Environment(包括配置要使用的PropertySource以及Profile)。
- 遍历调用所有SpringApplicationRunListener的environmentPrepared()的方法,告诉他们:“当前SpringBoot应用使用的Environment准备好了咯!”。
- 如果SpringApplication的showBanner属性被设置为true,则打印banner。
- 根据用户是否明确设置了applicationContextClass类型以及初始化阶段的推断结果,决定该为当前SpringBoot应用创建什么类型的ApplicationContext并创建完成,然后根据条件决定是否添加ShutdownHook,决定是否使用自定义的BeanNameGenerator,决定是否使用自定义的ResourceLoader,当然,最重要的,将之前准备好的Environment设置给创建好的ApplicationContext使用。
- ApplicationContext创建好之后,SpringApplication会再次借助Spring-FactoriesLoader,查找并加载classpath中所有可用的ApplicationContext-Initializer,然后遍历调用这些ApplicationContextInitializer的initialize(applicationContext)方法来对已经创建好的ApplicationContext进行进一步的处理。
- 遍历调用所有SpringApplicationRunListener的contextPrepared()方法。
- 最核心的一步,将之前通过@EnableAutoConfiguration获取的所有配置以及其他形式的IoC容器配置加载到已经准备完毕的ApplicationContext。
- 遍历调用所有SpringApplicationRunListener的contextLoaded()方法。
- 调用ApplicationContext的refresh()方法,完成IoC容器可用的最后一道工序。
- 查找当前ApplicationContext中是否注册有CommandLineRunner,如果有,则遍历执行它们。
- 正常情况下,遍历执行SpringApplicationRunListener的finished()方法、(如果整个过程出现异常,则依然调用所有SpringApplicationRunListener的finished()方法,只不过这种情况下会将异常信息一并传入处理)
去除事件通知点后,整个流程如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57public ConfigurableApplicationContext run(String... args) {
// 开启定时器,统计启动时间
StopWatch stopWatch = new StopWatch();
stopWatch.start();
ConfigurableApplicationContext context = null;
Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();
configureHeadlessProperty();
// 获取并初始化所有RunListener
SpringApplicationRunListeners listeners = getRunListeners(args);
// 发布启动事件
listeners.starting();
try {
ApplicationArguments applicationArguments = new DefaultApplicationArguments(
args);
// 准备好环境environment,即配置文件等
ConfigurableEnvironment environment = prepareEnvironment(listeners,
applicationArguments);
configureIgnoreBeanInfo(environment);
// 打印SpringBoot Logo
Banner printedBanner = printBanner(environment);
// 创建我们最常用的ApplicationContext
context = createApplicationContext();
// 获取异常报告器,在启动发生异常的时候用友好的方式提示用户
exceptionReporters = getSpringFactoriesInstances(
SpringBootExceptionReporter.class,
new Class[] { ConfigurableApplicationContext.class }, context);
// 准备Context,加载启动类作为source
prepareContext(context, environment, listeners, applicationArguments,
printedBanner);
// Spring初始化的核心逻辑,构建整个容器
refreshContext(context);
afterRefresh(context, applicationArguments);
// 停止计时,统计启动耗时
stopWatch.stop();
if (this.logStartupInfo) {
new StartupInfoLogger(this.mainApplicationClass)
.logStarted(getApplicationLog(), stopWatch);
}
listeners.started(context);
// 调用runner接口供应用自定义初始化
callRunners(context, applicationArguments);
}
catch (Throwable ex) {
// 处理启动中抛出的异常,使用异常报告器输出
handleRunFailure(context, ex, exceptionReporters, listeners);
throw new IllegalStateException(ex);
}
try {
listeners.running(context);
}
catch (Throwable ex) {
handleRunFailure(context, ex, exceptionReporters, null);
throw new IllegalStateException(ex);
}
return context;
}


什么是脑裂
什么是脑裂
脑裂(split-brain)就是“大脑分裂”,也就是本来一个“大脑”被拆分了两个或多个“大脑”,我们都知道,如果一个人有多个大脑,并且相互独立的话,那么会导致人体“手舞足蹈”,“不听使唤”。
脑裂通常会出现在集群环境中,比如ElasticSearch、Zookeeper集群,而这些集群环境有一个统一的特点,就是它们有一个大脑,比如ElasticSearch集群中有Master节点,Zookeeper集群中有Leader节点。
章着重来给大家讲一下Zookeeper中的脑裂问题,以及是如果解决脑裂问题的。
Zookeeper集群中的脑裂场景
对于一个集群,想要提高这个集群的可用性,通常会采用多机房部署,比如现在有一个由6台zkServer所组成的一个集群,部署在了两个机房:
正常情况下,此集群只会有一个Leader,那么如果机房之间的网络断了之后,两个机房内的zkServer还是可以相互通信的,如果不考虑过半机制,那么就会出现每个机房内部都将选出一个Leader。
这就相当于原本一个集群,被分成了两个集群,出现了两个“大脑”,这就是脑裂。
对于这种情况,我们也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务,如果过了一会,断了的网络突然联通了,那么此时就会出现问题了,两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。
刚刚在说明脑裂场景时,有一个前提条件就是没有考虑过半机制,所以实际上Zookeeper集群中是不会出现脑裂问题的,而不会出现的原因就跟过半机制有关。
过半机制
在领导者选举的过程中,如果某台zkServer获得了超过半数的选票,则此zkServer就可以成为Leader了。
过半机制的源码实现其实非常简单:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class QuorumMaj implements QuorumVerifier {
private static final Logger LOG = LoggerFactory.getLogger(QuorumMaj.class);
int half;
// n表示集群中zkServer的个数(准确的说是参与者的个数,参与者不包括观察者节点)
public QuorumMaj(int n){
this.half = n/2;
}
// 验证是否符合过半机制
public boolean containsQuorum(Set<Long> set){
// half是在构造方法里赋值的
// set.size()表示某台zkServer获得的票数
return (set.size() > half);
}
}
大家仔细看一下上面方法中的注释,核心代码就是下面两行:1
2this.half = n/2;
return (set.size() > half);
举个简单的例子: 如果现在集群中有5台zkServer,那么half=5/2=2,那么也就是说,领导者选举的过程中至少要有三台zkServer投了同一个zkServer,才会符合过半机制,才能选出来一个Leader。
那么有一个问题我们想一下,选举的过程中为什么一定要有一个过半机制验证? 因为这样不需要等待所有zkServer都投了同一个zkServer就可以选举出来一个Leader了,这样比较快,所以叫快速领导者选举算法呗。
那么再来想一个问题,过半机制中为什么是大于,而不是大于等于呢?
这就是更脑裂问题有关系了,比如回到上文出现脑裂问题的场景:
当机房中间的网络断掉之后,机房1内的三台服务器会进行领导者选举,但是此时过半机制的条件是set.size() > 3,也就是说至少要4台zkServer才能选出来一个Leader,所以对于机房1来说它不能选出一个Leader,同样机房2也不能选出一个Leader,这种情况下整个集群当机房间的网络断掉后,整个集群将没有Leader。
而如果过半机制的条件是set.size() >= 3,那么机房1和机房2都会选出一个Leader,这样就出现了脑裂。所以我们就知道了,为什么过半机制中是大于,而不是大于等于。就是为了防止脑裂。
如果假设我们现在只有5台机器,也部署在两个机房:
此时过半机制的条件是set.size() > 2,也就是至少要3台服务器才能选出一个Leader,此时机房件的网络断开了,对于机房1来说是没有影响的,Leader依然还是Leader,对于机房2来说是选不出来Leader的,此时整个集群中只有一个Leader。
所以,我们可以总结得出,有了过半机制,对于一个Zookeeper集群,要么没有Leader,要没只有1个Leader,这样就避免了脑裂问题。
有痛点才有创新,一个技术肯定都是为了解决某个痛点才出现的。
Saga模式与TCC的区别
各种形态的分布式事务
分布式事务有多种主流形态,包括:
- 基于消息实现的分布式事务
- 基于补偿实现的分布式事务
- 基于TCC实现的分布式事务
- 基于SAGA实现的分布式事务
- 基于2PC实现的分布式事务
这些形态的原理已经在很多文章中进行了剖析,用“分布式事务”关键字就能搜到对应的文章,本文不再赘述这些形态的原理,并将重点放在如何根据业务选择对应的分布式事务形态上。
何时选择单机事务
这个相信大家都很清楚,在条件允许的情况下,我们应该尽可能地使用单机事务,因为单机事务里,无需额外协调其他数据源,减少了网络交互时间消耗以及协调时所需的存储IO消耗,在修改等量业务数据的情况下,单机事务将会有更高的性能。
但单机数据库由于 业务逻辑解耦等因素进行了数据库垂直拆分、或者由于单机数据库性能压力等因素进行了数据库水平拆分之后,数据分布于多个数据库,这时若需要对多个数据库的数据进行协调变更,则需要引入分布式事务。
分布式事务的模式有很多种,那究竟要怎么选择适合业务的模式呢?以下我们将从使用场景、性能、开发成本这几个方面进行分析。
何时选择基于消息实现的事务
基于消息实现的事务适用于分布式事务的提交或回滚只取决于事务发起方的业务需求,其他数据源的数据变更跟随发起方进行的业务场景。
举个例子,假设存在业务规则:某笔订单成功后,为用户加一定的积分。
在这条规则里,管理订单数据源的服务为事务发起方,管理积分数据源的服务为事务跟随者。
从这个过程可以看到,基于消息队列实现的事务存在以下操作:
订单服务创建订单,提交本地事务
订单服务发布一条消息
积分服务收到消息后加积分
我们可以看到它的整体流程是比较简单的,同时业务开发工作量也不大:
- 编写订单服务里订单创建的逻辑
- 编写积分服务里增加积分的逻辑
可以看到该事务形态过程简单,性能消耗小,发起方与跟随方之间的流量峰谷可以使用队列填平,同时业务开发工作量也基本与单机事务没有差别,都不需要编写反向的业务逻辑过程。因此基于消息队列实现的事务是我们除了单机事务外最优先考虑使用的形态。
何时选择利用补偿实现的事务?
但是基于消息实现的事务并不能解决所有的业务场景,例如以下场景:某笔订单完成时,同时扣掉用户的现金。
这里事务发起方是管理订单库的服务,但对整个事务是否提交并不能只由订单服务决定,因为还要确保用户有足够的钱,才能完成这笔交易,而这个信息在管理现金的服务里。这里我们可以引入基于补偿实现的事务,其流程如下:
- 创建订单数据,但暂不提交本地事务
- 订单服务发送远程调用到现金服务,以扣除对应的金额
- 上述步骤成功后提交订单库的事务
以上这个是正常成功的流程,异常流程需要回滚的话,将额外发送远程调用到现金服务以加上之前扣掉的金额。
以上流程比基于消息队列实现的事务的流程要复杂,同时开发的工作量也更多:
- 编写订单服务里创建订单的逻辑
- 编写现金服务里扣钱的逻辑
- 编写现金服务里补偿返还的逻辑
可以看到,该事务流程相对于基于消息实现的分布式事务更为复杂,需要额外开发相关的业务回滚方法,也失去了服务间流量削峰填谷的功能。但其仅仅只比基于消息的事务复杂多一点,若不能使用基于消息队列的最终一致性事务,那么可以优先考虑使用基于补偿的事务形态。
(题外话:阿里GTS也是利用补偿实现,只不过补偿代码自动生成,无需业务干预,同时接管应用数据源,禁止业务修改处于全局事务状态中的记录。)
何时选择利用TCC实现的事务
然而基于补偿的事务形态也并非能实现所有的需求,如以下场景:某笔订单完成时,同时扣掉用户的现金,但交易未完成,也未被取消时,不能让客户看到钱变少了。
这时我们可以引入TCC,其流程如下:
- 订单服务创建订单
- 订单服务发送远程调用到现金服务,冻结客户的现金
- 提交订单服务数据
- 订单服务发送远程调用到现金服务,扣除客户冻结的现金
以上是正常完成的流程,若为异常流程,则需要发送远程调用请求到现金服务,撤销冻结的金额。
以上流程比基于补偿实现的事务的流程要复杂,同时开发的工作量也更多:
- 订单服务编写创建订单的逻辑
- 现金服务编写冻结现金的逻辑
- 现金服务编写扣除现金的逻辑
- 现金服务编写解冻现金的逻辑
TCC实际上是最为复杂的一种情况,其能处理所有的业务场景,但无论出于性能上的考虑,还是开发复杂度上的考虑,都应该尽量避免该类事务。
何时选择利用SAGA实现的事务?
saga是30年前的一篇数据库论文提到的概念。 论文中定义saga事务是一个长事务,整个事务可以由多个本地事务组成,每个本地事务有相应的执行模块和补偿模块,当saga事务中任意一个事务出错了,可以调用相关事务进行对应的补偿恢复,达到事务的最终一致性。
由于分布式系统中网络带来的不可靠性,saga调用服务提出了服务应该支持幂等,在服务调用超时重试情况下,不至于产生问题。
saga事务没有准备阶段,不具备隔离性,如果多个saga事务同时操作同一资源会遇到多线程临界资源的情况,产生数据丢失或者脏数据。
为解决隔离性,可以参考TCC模式,在业务层加入session及锁机制保证操作串型化,通过业务层面达到隔离效果。
saga在分布式架构下,采用事务驱动方式,让服务进行相关交互,业务方订阅相关领域事件即可。 通过事件方式降低系统复杂度,提升系统扩展性,但要注意事件循环依赖的问题。
SAGA可以看做一个异步的、利用队列实现的补偿事务。
其适用于无需马上返回业务发起方最终状态的场景,例如:你的请求已提交,请稍后查询或留意通知 之类。
将上述补偿事务的场景用SAGA改写,其流程如下:
- 订单服务创建最终状态未知的订单记录,并提交事务
- 现金服务扣除所需的金额,并提交事务
- 订单服务更新订单状态为成功,并提交事务
以上为成功的流程,若现金服务扣除金额失败,那么,最后一步订单服务将会更新订单状态为失败。
其业务编码工作量比补偿事务多一点,包括以下内容:
- 订单服务创建初始订单的逻辑
- 订单服务确认订单成功的逻辑
- 订单服务确认订单失败的逻辑
- 现金服务扣除现金的逻辑
- 现金服务补偿返回现金的逻辑
但其相对于补偿事务形态有性能上的优势,所有的本地子事务执行过程中,都无需等待其调用的子事务执行,减少了加锁的时间,这在事务流程较多较长的业务中性能优势更为明显。同时,其利用队列进行进行通讯,具有削峰填谷的作用。
因此该形式适用于不需要同步返回发起方执行最终结果、可以进行补偿、对性能要求较高、不介意额外编码的业务场景。
但当然SAGA也可以进行稍微改造,变成与TCC类似、可以进行资源预留的形态。
2PC事务
其适用于参与者较少,单个本地事务执行时间较少,并且参与者自身可用性很高的场景,否则,其很可能导致性能下降严重。
并非一种事务形态就能打遍天下
通过分析我们可以发现,并不存在一种事务形态能解决所有的问题,我们需要根据特定的业务场景选择合适的事务形态。甚至于有时需要混合多种事务形态才能更好的完成目标,如 上面提到的 订单、积分、钱包混合的场景:订单的成功与否需要依赖于钱包的余额,但不依赖于积分的多少,因此可以混合基于消息的事务形态以加积分 及 基于补偿的事务形态以确保扣钱成功,从而得到一个性能更好,编码量更少的形态。
然而目前很多框架都专注于某单一方面的事务形态,如TCC单独一个框架,可靠消息单独一个框架,SAGA单独一个框架,他们各自独立,容易导致以下问题:
- 由于前期只采用了其中一种类型事务的框架,因为工具目前只有锤子,引入其他工具又涉及测试、阅读代码等过程,因此把所有问题都看做钉子,导致性能偏低或者实现不够优雅
- 由于不同框架管理事务的形态可能不一致,导致不能很好的协调工作,如某一个TCC框架和另一个基于消息的事务框架无法很好融合。
事务隔离级别
Spring事务的隔离级别
ISOLATION_DEFAULT: 这是一个 PlatfromTransactionManager 默认的隔离级别,使用数据库默认的事务隔离级别.
另外四个与 JDBC的隔离级别相对应:
ISOLATION_READ_UNCOMMITTED: 这是事务最低的隔离级别,它允许令外一个事务可以看到这个事务未提交的数据,
这种隔离级别会产生脏读,不可重复读和幻像读。
ISOLATION_READ_COMMITTED: 保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据ISOLATION_REPEATABLE_READ: 这种事务隔离级别可以防止脏读,不可重复读。但是可能出现幻像读。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了避免下面的情况产生(不可重复读)。ISOLATION_SERIALIZABLE这是花费最高代价但是最可靠的事务隔离级别。事务被处理为顺序执行。除了防止脏读,不可重复读外,还避免了幻像读。
其中的一些概念的说明:
脏读: 指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据, 那么另外一 个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
不可重复读: 指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。 那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
幻觉读:指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及 到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,就会发生操作第一个事务的用户发现表中还有 没有修改的数据行,也就是说幻像读是指同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集,此时发生幻像读,就好象发生了幻觉一样。
事务的传播行为和隔离级别之间有什么联系
事务传播行为
事务传播行为(为了解决业务层方法之间互相调用的事务问题): 当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
支持当前事务的情况
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
不支持当前事务的情况
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况
TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
隔离级别
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的REPEATABLE_READ隔离级别 Oracle 默认采用的READ_COMMITTED隔离级别。TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。

如何理解Spring中的AOP 和 IOC,以及DI,读过Spring源码没有?
AOP

什么是aop
- AOP(Aspect Oriented Programming)称为面向切面编程,在程序开发中主要用来解决一些系统层面上的问题,比如日志,事务,权限等待,Struts2的拦截器设计就是基于AOP的思想,是个比较经典的例子。
- 在不改变原有的逻辑的基础上,增加一些额外的功能。代理也是这个功能,读写分离也能用aop来做。
- AOP可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。OOP引入封装、继承、多态等概念来建立一种对象层次结构,用于模拟公共行为的一个集合。不过OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
- AOP技术恰恰相反,它利用一种称为”横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为”Aspect”,即切面。所谓”切面”,简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
- 使用”横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事物。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
AOP的相关概念
(1)横切关注点:对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点
(2)Aspect(切面):通常是一个类,里面可以定义切入点和通知
(3)JointPoint(连接点):程序执行过程中明确的点,一般是方法的调用。被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
(4)Advice(通知):AOP在特定的切入点上执行的增强处理,有before(前置),after(后置),afterReturning(最终),afterThrowing(异常),around(环绕)
(5)Pointcut(切入点):就是带有通知的连接点,在程序中主要体现为书写切入点表达式
(6)weave(织入):将切面应用到目标对象并导致代理对象创建的过程
(7)introduction(引入):在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
(8)AOP代理(AOP Proxy):AOP框架创建的对象,代理就是目标对象的加强。Spring中的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类
(9)目标对象(Target Object): 包含连接点的对象。也被称作被通知或被代理对象。POJO
Advice通知类型介绍
(1)Before:在目标方法被调用之前做增强处理,@Before只需要指定切入点表达式即可
(2)AfterReturning:在目标方法正常完成后做增强,@AfterReturning除了指定切入点表达式后,还可以指定一个返回值形参名returning,代表目标方法的返回值
(3)AfterThrowing:主要用来处理程序中未处理的异常,@AfterThrowing除了指定切入点表达式后,还可以指定一个throwing的返回值形参名,可以通过该形参名
来访问目标方法中所抛出的异常对象
(4)After:在目标方法完成之后做增强,无论目标方法时候成功完成。@After可以指定一个切入点表达式
(5)Around:环绕通知,在目标方法完成前后做增强处理,环绕通知是最重要的通知类型,像事务,日志等都是环绕通知,注意编程中核心是一个ProceedingJoinPoint
AOP使用场景
- Authentication 权限
- Caching 缓存
- Context passing 内容传递
- Error handling 错误处理
- Lazy loading 懒加载
- Debugging 调试
- logging, tracing, profiling and monitoring 记录跟踪 优化 校准
- Performance optimization 性能优化
- Persistence 持久化
- Resource pooling 资源池
- Synchronization 同步
- Transactions 事务
使用AOP的几种方式
1.经典的基于代理的AOP
2.@AspectJ注解驱动的切面
3.纯POJO切面(纯粹通过<aop:fonfig>标签配置)
4.注入式AspectJ切面
IOC
IoC 全称为 Inversion of Control,翻译为 “控制反转”,它还有一个别名为 DI(Dependency Injection),即依赖注入。
如何理解“控制反转”好呢?理解好它的关键在于我们需要回答如下四个问题:
- 谁控制谁
- 控制什么
- 为何是反转
- 哪些方面反转了
在回答这四个问题之前,我们先看 IOC 的定义:
所谓 IOC ,就是由 Spring IOC 容器来负责对象的生命周期和对象之间的关系
上面这句话是整个 IoC 理论的核心。如何来理解这句话?我们引用一个例子来走阐述(看完该例子上面四个问题也就不是问题了)。
已找女朋友为例(对于程序猿来说这个值得探究的问题)。一般情况下我们是如何来找女朋友的呢?首先我们需要根据自己的需求(漂亮、身材好、性格好)找一个妹子,然后到处打听她的兴趣爱好、微信、电话号码,然后各种投其所好送其所要,最后追到手。如下:
1 | /** |
这就是我们通常做事的方式,如果我们需要某个对象,一般都是采用这种直接创建的方式(new BeautifulGirl()),这个过程复杂而又繁琐,而且我们必须要面对每个环节,同时使用完成之后我们还要负责销毁它,在这种情况下我们的对象与它所依赖的对象耦合在一起。
其实我们需要思考一个问题?我们每次用到自己依赖的对象真的需要自己去创建吗?我们知道,我们依赖对象其实并不是依赖该对象本身,而是依赖它所提供的服务,只要在我们需要它的时候,它能够及时提供服务即可,至于它是我们主动去创建的还是别人送给我们的,其实并不是那么重要。再说了,相比于自己千辛万苦去创建它还要管理、善后而言,直接有人送过来是不是显得更加好呢?
这个给我们送东西的“人” 就是 IoC,在上面的例子中,它就相当于一个婚介公司,作为一个婚介公司它管理着很多男男女女的资料,当我们需要一个女朋友的时候,直接跟婚介公司提出我们的需求,婚介公司则会根据我们的需求提供一个妹子给我们,我们只需要负责谈恋爱,生猴子就行了。你看,这样是不是很简单明了。
诚然,作为婚介公司的 IoC 帮我们省略了找女朋友的繁杂过程,将原来的主动寻找变成了现在的被动接受(符合我们的要求),更加简洁轻便。你想啊,原来你还得鞍马前后,各种巴结,什么东西都需要自己去亲力亲为,现在好了,直接有人把现成的送过来,多么美妙的事情啊。所以,简单点说,IoC 的理念就是让别人为你服务
在没有引入 IoC 的时候,被注入的对象直接依赖于被依赖的对象,有了 IoC 后,两者及其他们的关系都是通过 Ioc Service Provider 来统一管理维护的。被注入的对象需要什么,直接跟 IoC Service Provider 打声招呼,后者就会把相应的被依赖对象注入到被注入的对象中,从而达到 IOC Service Provider 为被注入对象服务的目的。所以 IoC 就是这么简单!原来是需要什么东西自己去拿,现在是需要什么东西让别人(IOC Service Provider)送过来
现在在看上面那四个问题,答案就显得非常明显了:
- 谁控制谁:在传统的开发模式下,我们都是采用直接 new 一个对象的方式来创建对象,也就是说你依赖的对象直接由你自己控制,但是有了 IOC 容器后,则直接由 IoC 容器来控制。所以“谁控制谁”,当然是 IoC 容器控制对象。
- 控制什么:控制对象。
- 为何是反转:没有 IoC 的时候我们都是在自己对象中主动去创建被依赖的对象,这是正转。但是有了 IoC 后,所依赖的对象直接由 IoC 容器创建后注入到被注入的对象中,依赖的对象由原来的主动获取变成被动接受,所以是反转。
哪些方面反转了:所依赖对象的获取被反转了。
妹子有了,但是如何拥有妹子呢?这也是一门学问。可能你比较牛逼,刚刚出生的时候就指腹为婚了。
- 大多数情况我们还是会考虑自己想要什么样的妹子,所以还是需要向婚介公司打招呼的。
- 还有一种情况就是,你根本就不知道自己想要什么样的妹子,直接跟婚介公司说,我就要一个这样的妹子。
所以,IOC Service Provider 为被注入对象提供被依赖对象也有如下几种方式:构造方法注入、stter方法注入、接口注入。
构造器注入
构造器注入,顾名思义就是被注入的对象通过在其构造方法中声明依赖对象的参数列表,让外部知道它需要哪些依赖对象。1
2
3YoungMan(BeautifulGirl beautifulGirl){
this.beautifulGirl = beautifulGirl;
}
构造器注入方式比较直观,对象构造完毕后就可以直接使用,这就好比你出生你家里就给你指定了你媳妇。
setter 方法注入
对于 JavaBean 对象而言,我们一般都是通过 getter 和 setter 方法来访问和设置对象的属性。所以,当前对象只需要为其所依赖的对象提供相对应的 setter 方法,就可以通过该方法将相应的依赖对象设置到被注入对象中。如下:1
2
3
4
5
6
7public class YoungMan {
private BeautifulGirl beautifulGirl;
public void setBeautifulGirl(BeautifulGirl beautifulGirl) {
this.beautifulGirl = beautifulGirl;
}
}
相比于构造器注入,setter 方式注入会显得比较宽松灵活些,它可以在任何时候进行注入(当然是在使用依赖对象之前),这就好比你可以先把自己想要的妹子想好了,然后再跟婚介公司打招呼,你可以要林志玲款式的,赵丽颖款式的,甚至凤姐哪款的,随意性较强。
接口方式注入
接口方式注入显得比较霸道,因为它需要被依赖的对象实现不必要的接口,带有侵入性。一般都不推荐这种方式。
DI
DI(Dependency Injection)依赖注入:就是指对象是被动接受依赖类而不是自己主动去找,换句话说就是指对象不是从容器中查找它依赖的类,而是在容器实例化对象的时候主动将它依赖的类注入给它。
依赖注入发生的时间
当 Spring IOC 容器完成了 Bean 定义资源的定位、载入和解析注册以后,IOC 容器中已经管理类 Bean定义的相关数据,但是此时 IOC 容器还没有对所管理的 Bean 进行依赖注入,依赖注入在以下两种情况发生:
1)、用户第一次调用 getBean()方法时,IOC 容器触发依赖注入。
2)、当用户在配置文件中将<bean>元素配置了 lazy-init=false 属性,即让容器在解析注册 Bean 定义时进行预实例化,触发依赖注入。
BeanFactory 接口定义了 Spring IOC 容器的基本功能规范,是 Spring IOC 容器所应遵守的最底层和最基本的编程规范。BeanFactory 接口中定义了几个 getBean()方法,就是用户向 IOC 容器索取管理的Bean 的方法,我们通过分析其子类AbstractBeanFactory 的具体实现,理解 Spring IOC 容器在用户索取 Bean 时如何完成依赖注入。
AbstractBeanFactory 的 getBean()相关方法的源码如下:
1 | //获取IOC容器中指定名称的Bean |
通过上面对向 IOC 容器获取 Bean 方法的分析,我们可以看到在 Spring 中,如果 Bean 定义的单例模式(Singleton),则容器在创建之前先从缓存中查找,以确保整个容器中只存在一个实例对象。如果 Bean定义的是原型模式(Prototype),则容器每次都会创建一个新的实例对象。除此之外,Bean 定义还可以通过其指定的生命周期范围来创建。
上面的源码只是定义了根据 Bean 定义的模式,采取的不同创建 Bean 实例对象的策略,具体的 Bean实例 对象的创 建过程 由实现了AbstractBeanFactory接口 的匿名内 部类的createBean()方法 完成,AbstractBeanFactory使 用 委 派 模 式 , 具 体 的 Bean 实 例 创 建 过 程 交 由 其 实 现 类AbstractAutowireCapableBeanFactory 完成,我们继续分析AbstractAutowireCapableBeanFactory的 createBean()方法的源码,理解其创建 Bean 实例的具体实现过程。
开始实例化
AbstractAutowireCapableBeanFactory 类实现了 AbstractBeanFactory接口,创建容器指定的 Bean 实例对象,同时还对创建的 Bean 实例对象进行初始化处理。其创建 Bean 实例对象的方法源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179//创建Bean实例对象
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
if (logger.isDebugEnabled()) {
logger.debug("Creating instance of bean '" + beanName + "'");
}
RootBeanDefinition mbdToUse = mbd;
// Make sure bean class is actually resolved at this point, and
// clone the bean definition in case of a dynamically resolved Class
// which cannot be stored in the shared merged bean definition.
//判断需要创建的Bean是否可以实例化,即是否可以通过当前的类加载器加载
Class<?> resolvedClass = resolveBeanClass(mbd, beanName);
if (resolvedClass != null && !mbd.hasBeanClass() && mbd.getBeanClassName() != null) {
mbdToUse = new RootBeanDefinition(mbd);
mbdToUse.setBeanClass(resolvedClass);
}
// Prepare method overrides.
//校验和准备Bean中的方法覆盖
try {
mbdToUse.prepareMethodOverrides();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(mbdToUse.getResourceDescription(),
beanName, "Validation of method overrides failed", ex);
}
try {
// Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
//如果Bean配置了初始化前和初始化后的处理器,则试图返回一个需要创建Bean的代理对象
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
}
catch (Throwable ex) {
throw new BeanCreationException(mbdToUse.getResourceDescription(), beanName,
"BeanPostProcessor before instantiation of bean failed", ex);
}
try {
//创建Bean的入口
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
if (logger.isDebugEnabled()) {
logger.debug("Finished creating instance of bean '" + beanName + "'");
}
return beanInstance;
}
catch (BeanCreationException ex) {
// A previously detected exception with proper bean creation context already...
throw ex;
}
catch (ImplicitlyAppearedSingletonException ex) {
// An IllegalStateException to be communicated up to DefaultSingletonBeanRegistry...
throw ex;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbdToUse.getResourceDescription(), beanName, "Unexpected exception during bean creation", ex);
}
}
//真正创建Bean的方法
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
//封装被创建的Bean对象
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
final Object bean = instanceWrapper.getWrappedInstance();
//获取实例化对象的类型
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
//调用PostProcessor后置处理器
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
//向容器中缓存单例模式的Bean对象,以防循环引用
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//这里是一个匿名内部类,为了防止循环引用,尽早持有对象的引用
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
//Bean对象的初始化,依赖注入在此触发
//这个exposedObject在初始化完成之后返回作为依赖注入完成后的Bean
Object exposedObject = bean;
try {
//将Bean实例对象封装,并且Bean定义中配置的属性值赋值给实例对象
populateBean(beanName, mbd, instanceWrapper);
//初始化Bean对象
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
//获取指定名称的已注册的单例模式Bean对象
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
//根据名称获取的已注册的Bean和正在实例化的Bean是同一个
if (exposedObject == bean) {
//当前实例化的Bean初始化完成
exposedObject = earlySingletonReference;
}
//当前Bean依赖其他Bean,并且当发生循环引用时不允许新创建实例对象
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
//获取当前Bean所依赖的其他Bean
for (String dependentBean : dependentBeans) {
//对依赖Bean进行类型检查
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
//注册完成依赖注入的Bean
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
通过上面的源码注释,我们看到具体的依赖注入实现其实就在以下两个方法中:
1)、createBeanInstance()方法,生成 Bean 所包含的 java 对象实例。
2)、populateBean()方法,对 Bean 属性的依赖注入进行处理。
下面继续分析这两个方法的代码实现。
选择 Bean 实例化策略
在 createBeanInstance()方法中,根据指定的初始化策略,使用简单工厂、工厂方法或者容器的自动装配特性生成 Java 实例对象,创建对象的源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86//创建Bean的实例对象
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// Make sure bean class is actually resolved at this point.
//检查确认Bean是可实例化的
Class<?> beanClass = resolveBeanClass(mbd, beanName);
//使用工厂方法对Bean进行实例化
if (beanClass != null && !Modifier.isPublic(beanClass.getModifiers()) && !mbd.isNonPublicAccessAllowed()) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Bean class isn't public, and non-public access not allowed: " + beanClass.getName());
}
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
if (mbd.getFactoryMethodName() != null) {
//调用工厂方法实例化
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
// Shortcut when re-creating the same bean...
//使用容器的自动装配方法进行实例化
boolean resolved = false;
boolean autowireNecessary = false;
if (args == null) {
synchronized (mbd.constructorArgumentLock) {
if (mbd.resolvedConstructorOrFactoryMethod != null) {
resolved = true;
autowireNecessary = mbd.constructorArgumentsResolved;
}
}
}
if (resolved) {
if (autowireNecessary) {
//配置了自动装配属性,使用容器的自动装配实例化
//容器的自动装配是根据参数类型匹配Bean的构造方法
return autowireConstructor(beanName, mbd, null, null);
}
else {
//使用默认的无参构造方法实例化
return instantiateBean(beanName, mbd);
}
}
// Need to determine the constructor...
//使用Bean的构造方法进行实例化
Constructor<?>[] ctors = determineConstructorsFromBeanPostProcessors(beanClass, beanName);
if (ctors != null ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_CONSTRUCTOR ||
mbd.hasConstructorArgumentValues() || !ObjectUtils.isEmpty(args)) {
//使用容器的自动装配特性,调用匹配的构造方法实例化
return autowireConstructor(beanName, mbd, ctors, args);
}
// No special handling: simply use no-arg constructor.
//使用默认的无参构造方法实例化
return instantiateBean(beanName, mbd);
}
//使用默认的无参构造方法实例化Bean对象
protected BeanWrapper instantiateBean(final String beanName, final RootBeanDefinition mbd) {
try {
Object beanInstance;
final BeanFactory parent = this;
//获取系统的安全管理接口,JDK标准的安全管理API
if (System.getSecurityManager() != null) {
//这里是一个匿名内置类,根据实例化策略创建实例对象
beanInstance = AccessController.doPrivileged((PrivilegedAction<Object>) () ->
getInstantiationStrategy().instantiate(mbd, beanName, parent),
getAccessControlContext());
}
else {
//将实例化的对象封装起来
beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent);
}
BeanWrapper bw = new BeanWrapperImpl(beanInstance);
initBeanWrapper(bw);
return bw;
}
catch (Throwable ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Instantiation of bean failed", ex);
}
}
经过对上面的代码分析,我们可以看出,对使用工厂方法和自动装配特性的 Bean 的实例化相当比较清楚,调用相应的工厂方法或者参数匹配的构造方法即可完成实例化对象的工作,但是对于我们最常使用的默认无参构造方法就需要使用相应的初始化策略(JDK 的反射机制或者 CGLib)来进行初始化了,在方法 getInstantiationStrategy().instantiate()中就具体实现类使用初始策略实例化对象。
执行 Bean 实例化
在使用默认的无参构造方法创建 Bean 的实例化对象时,方法 getInstantiationStrategy().instantiate()调用了 SimpleInstantiationStrategy 类中的实例化 Bean 的方法,其源码如下:
1 | //使用初始化策略实例化Bean对象 |
通过上面的代码分析,我们看到了如果 Bean 有方法被覆盖了,则使用 JDK 的反射机制进行实例化,否则,使用 CGLib 进行实例化。instantiateWithMethodInjection() 方 法 调 用SimpleInstantiationStrategy 的 子 类CGLibSubclassingInstantiationStrategy 使用 CGLib 来进行初始化,其源码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43//使用CGLIB进行Bean对象实例化
public Object instantiate(@Nullable Constructor<?> ctor, @Nullable Object... args) {
//创建代理子类
Class<?> subclass = createEnhancedSubclass(this.beanDefinition);
Object instance;
if (ctor == null) {
instance = BeanUtils.instantiateClass(subclass);
}
else {
try {
Constructor<?> enhancedSubclassConstructor = subclass.getConstructor(ctor.getParameterTypes());
instance = enhancedSubclassConstructor.newInstance(args);
}
catch (Exception ex) {
throw new BeanInstantiationException(this.beanDefinition.getBeanClass(),
"Failed to invoke constructor for CGLIB enhanced subclass [" + subclass.getName() + "]", ex);
}
}
// SPR-10785: set callbacks directly on the instance instead of in the
// enhanced class (via the Enhancer) in order to avoid memory leaks.
Factory factory = (Factory) instance;
factory.setCallbacks(new Callback[] {NoOp.INSTANCE,
new LookupOverrideMethodInterceptor(this.beanDefinition, this.owner),
new ReplaceOverrideMethodInterceptor(this.beanDefinition, this.owner)});
return instance;
}
private Class<?> createEnhancedSubclass(RootBeanDefinition beanDefinition) {
//CGLIB中的类
Enhancer enhancer = new Enhancer();
//将Bean本身作为其基类
enhancer.setSuperclass(beanDefinition.getBeanClass());
enhancer.setNamingPolicy(SpringNamingPolicy.INSTANCE);
if (this.owner instanceof ConfigurableBeanFactory) {
ClassLoader cl = ((ConfigurableBeanFactory) this.owner).getBeanClassLoader();
enhancer.setStrategy(new ClassLoaderAwareGeneratorStrategy(cl));
}
enhancer.setCallbackFilter(new MethodOverrideCallbackFilter(beanDefinition));
enhancer.setCallbackTypes(CALLBACK_TYPES);
//使用CGLIB的createClass方法生成实例对象
return enhancer.createClass();
}
}
CGLib 是一个常用的字节码生成器的类库,它提供了一系列 API 实现 Java 字节码的生成和转换功能。JDK 的动态代理只能针对接口,如果一个类没有实现任何接口,要对其进行动态代理只能使用 CGLib。
准备依赖注入
在前面的分析中我们已经了解到 Bean 的依赖注入主要分为两个步骤,首先调用 createBeanInstance()方法生成 Bean 所包含的 Java 对象实例。然后,调用 populateBean()方法,对 Bean 属性的依赖注入进行处理。
上面我们已经分析了容器初始化生成 Bean 所包含的 Java 实例对象的过程,现在我们继续分析生成对象后,Spring IOC 容器是如何将 Bean 的属性依赖关系注入 Bean 实例对象中并设置好的,回到AbstractAutowireCapableBeanFactory 的 populateBean()方法,对属性依赖注入的代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201//将Bean属性设置到生成的实例对象上
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) {
if (bw == null) {
if (mbd.hasPropertyValues()) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Cannot apply property values to null instance");
}
else {
// Skip property population phase for null instance.
return;
}
}
// Give any InstantiationAwareBeanPostProcessors the opportunity to modify the
// state of the bean before properties are set. This can be used, for example,
// to support styles of field injection.
boolean continueWithPropertyPopulation = true;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) {
continueWithPropertyPopulation = false;
break;
}
}
}
}
if (!continueWithPropertyPopulation) {
return;
}
//获取容器在解析Bean定义资源时为BeanDefiniton中设置的属性值
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
//对依赖注入处理,首先处理autowiring自动装配的依赖注入
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME ||
mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
MutablePropertyValues newPvs = new MutablePropertyValues(pvs);
// Add property values based on autowire by name if applicable.
//根据Bean名称进行autowiring自动装配处理
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_NAME) {
autowireByName(beanName, mbd, bw, newPvs);
}
// Add property values based on autowire by type if applicable.
//根据Bean类型进行autowiring自动装配处理
if (mbd.getResolvedAutowireMode() == RootBeanDefinition.AUTOWIRE_BY_TYPE) {
autowireByType(beanName, mbd, bw, newPvs);
}
pvs = newPvs;
}
//对非autowiring的属性进行依赖注入处理
boolean hasInstAwareBpps = hasInstantiationAwareBeanPostProcessors();
boolean needsDepCheck = (mbd.getDependencyCheck() != RootBeanDefinition.DEPENDENCY_CHECK_NONE);
if (hasInstAwareBpps || needsDepCheck) {
if (pvs == null) {
pvs = mbd.getPropertyValues();
}
PropertyDescriptor[] filteredPds = filterPropertyDescriptorsForDependencyCheck(bw, mbd.allowCaching);
if (hasInstAwareBpps) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof InstantiationAwareBeanPostProcessor) {
InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp;
pvs = ibp.postProcessPropertyValues(pvs, filteredPds, bw.getWrappedInstance(), beanName);
if (pvs == null) {
return;
}
}
}
}
if (needsDepCheck) {
checkDependencies(beanName, mbd, filteredPds, pvs);
}
}
if (pvs != null) {
//对属性进行注入
applyPropertyValues(beanName, mbd, bw, pvs);
}
}
//解析并注入依赖属性的过程
protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) {
if (pvs.isEmpty()) {
return;
}
//封装属性值
MutablePropertyValues mpvs = null;
List<PropertyValue> original;
if (System.getSecurityManager() != null) {
if (bw instanceof BeanWrapperImpl) {
//设置安全上下文,JDK安全机制
((BeanWrapperImpl) bw).setSecurityContext(getAccessControlContext());
}
}
if (pvs instanceof MutablePropertyValues) {
mpvs = (MutablePropertyValues) pvs;
//属性值已经转换
if (mpvs.isConverted()) {
// Shortcut: use the pre-converted values as-is.
try {
//为实例化对象设置属性值
bw.setPropertyValues(mpvs);
return;
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
//获取属性值对象的原始类型值
original = mpvs.getPropertyValueList();
}
else {
original = Arrays.asList(pvs.getPropertyValues());
}
//获取用户自定义的类型转换
TypeConverter converter = getCustomTypeConverter();
if (converter == null) {
converter = bw;
}
//创建一个Bean定义属性值解析器,将Bean定义中的属性值解析为Bean实例对象的实际值
BeanDefinitionValueResolver valueResolver = new BeanDefinitionValueResolver(this, beanName, mbd, converter);
// Create a deep copy, resolving any references for values.
//为属性的解析值创建一个拷贝,将拷贝的数据注入到实例对象中
List<PropertyValue> deepCopy = new ArrayList<>(original.size());
boolean resolveNecessary = false;
for (PropertyValue pv : original) {
//属性值不需要转换
if (pv.isConverted()) {
deepCopy.add(pv);
}
//属性值需要转换
else {
String propertyName = pv.getName();
//原始的属性值,即转换之前的属性值
Object originalValue = pv.getValue();
//转换属性值,例如将引用转换为IOC容器中实例化对象引用
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
//转换之后的属性值
Object convertedValue = resolvedValue;
//属性值是否可以转换
boolean convertible = bw.isWritableProperty(propertyName) &&
!PropertyAccessorUtils.isNestedOrIndexedProperty(propertyName);
if (convertible) {
//使用用户自定义的类型转换器转换属性值
convertedValue = convertForProperty(resolvedValue, propertyName, bw, converter);
}
// Possibly store converted value in merged bean definition,
// in order to avoid re-conversion for every created bean instance.
//存储转换后的属性值,避免每次属性注入时的转换工作
if (resolvedValue == originalValue) {
if (convertible) {
//设置属性转换之后的值
pv.setConvertedValue(convertedValue);
}
deepCopy.add(pv);
}
//属性是可转换的,且属性原始值是字符串类型,且属性的原始类型值不是
//动态生成的字符串,且属性的原始值不是集合或者数组类型
else if (convertible && originalValue instanceof TypedStringValue &&
!((TypedStringValue) originalValue).isDynamic() &&
!(convertedValue instanceof Collection || ObjectUtils.isArray(convertedValue))) {
pv.setConvertedValue(convertedValue);
//重新封装属性的值
deepCopy.add(pv);
}
else {
resolveNecessary = true;
deepCopy.add(new PropertyValue(pv, convertedValue));
}
}
}
if (mpvs != null && !resolveNecessary) {
//标记属性值已经转换过
mpvs.setConverted();
}
// Set our (possibly massaged) deep copy.
//进行属性依赖注入
try {
bw.setPropertyValues(new MutablePropertyValues(deepCopy));
}
catch (BeansException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Error setting property values", ex);
}
}
分析上述代码,我们可以看出,对属性的注入过程分以下两种情况:
1)、属性值类型不需要强制转换时,不需要解析属性值,直接准备进行依赖注入。
2)、属性值需要进行类型强制转换时,如对其他对象的引用等,首先需要解析属性值,然后对解析后的属性值进行依赖注入。
对属性值的解析是在 BeanDefinitionValueResolver 类中的 resolveValueIfNecessary()方法中进行的,对属性值的依赖注入是通过 bw.setPropertyValues()方法实现的,在分析属性值的依赖注入之前,我们先分析一下对属性值的解析过程
解析属性注入规则
当容器在对属性进行依赖注入时,如果发现属性值需要进行类型转换,如属性值是容器中另一个 Bean实例对象的引用,则容器首先需要根据属性值解析出所引用的对象,然后才能将该引用对象注入到目标实例对象的属性上去,对属性进行解析的由 resolveValueIfNecessary()方法实现。
Spring IOC 容器是如何将属性的值注入到 Bean 实例对象中去的:
1)、对于集合类型的属性,将其属性值解析为目标类型的集合后直接赋值给属性。
2)、对于非集合类型的属性,大量使用了 JDK 的反射机制,通过属性的 getter()方法获取指定属性注入以前的值,同时调用属性的 setter()方法为属性设置注入后的值。看到这里相信很多人都明白了 Spring的 setter()注入原理
Spring DI运行时序图
如何理解分布式事务,为什么会出现这个问题,如何去解决,了解哪些分布式事务中间件?
分布式中间件,我自己了解的就有
- seata
- tx-lcn
- easyTransaction
- serviceComb
Dubbo有了解没有?
阿里开源的一款分布式框架。
Hystrix功能和在项目中怎么使用的?Hystrix怎么检测断路器是否要开启/关闭?Hystrix实现原理?除Hystrix之外的其他熔断限流中间件有了解没有,了解多少说多少?
在一个分布式系统中,必然会有部分系统的调用会失败。Hystrix是一个通过添加超时容错和失败容错逻辑来帮助你控制这些分布式系统的交互。Hystrix通过隔离服务之间的访问,阻止他们之间的级联故障以及提供后背选项来实现这些,所有新而这些都用来提高系统的整体弹性。
Hystrix被设计用来解决一下几个方面
- 通过第三方(一般来源网络)的调用,给与保护和控制延迟和失败。
- 在复杂的分布式系统中复制级联失败。
- 快速失败和修复。
- 在可能的情况下,回滚挥着优雅的失败。
- 实现几乎实时监控,警报和操作控制。
复杂的分布式体系结构中的应用程序具有许多依赖关系,每个依赖关系都会在某些时候不可避免的失败。如果主机应用程序未与这些外部的故障隔离,那么可能会被这些故障拖垮。
例如:一个依赖30个SOA服务的系统,每个服务99.99%可用。
99.99%的30次方 ≈ 99.7%
0.3% 意味着一亿次请求 会有 3,000,00次失败
换算成时间大约每月有2个小时服务不稳定.
随着服务依赖数量的变多,服务不稳定的概率会成指数性提高.
而实际中可能更糟糕。
Hystrix设计模式
设计详解(命令模式)
流程图
流程说明
- 构造一个HystrixCommand或者HystrixObserverCommand对象,把需要调用的依赖放在run()中
- 执行execute/queue做同步或者异步执行
- 是否做了缓存
- 熔断是否打开
- 线程池/队列/信号量是否满了
- 调用run()或者construct()
- 计算熔断健康度(成功,失败,拒绝,超时)的数据,上报给熔断器,用于统计从而判断熔断器状态,可以根据这些数据来决定是否进行熔断,例如:错误率在80%以上,接口等待超过预定的时间等。
- 获取Fallback,如果fallback失败,系统报错,所以要尽量防止fallback报错,当然也可以在fallback上加上一层fallback
- 返回执行结果
功能介绍
熔断器
下图显示了HystrixCommand或者HystrixObserverCommand如何与HystrixCircuitBreaker及其逻辑和决策流程。包括计数器在断路器中的行为方式。
熔断行为
断路器打开还是关闭的步骤如下
- 假定请求的量超过预定的阈值(circuitBreakerRequestVolumeThreshold)
- 再假定错误百分比超过了设定的百分比(circuitBreakerErrorThresholdPercentage)
- 断路器会从close状态到open状态
- 当打开的状态,会短路所有针对该断路器的请求
- 过了一定时间(circuitBreakerSleepWindowInMilliseconds(短路超过一定时间会重新去请求)),下一个请求将通过,不会被短路(当前是half-open状态)。如果这个请求失败了,则断路器在睡眠窗口期间返回open状态,如果请求成功,则断路器返回close状态,并重新回到第一步逻辑判断。
隔离
Hystrix使用璧仓模式来隔离彼此的依赖关系,并限制对其中任何一个的并发访问。

线程和线程池
客户端(第三方,网络调用等)依赖和请求线程运行在不同的线程上,这个将他们从调用线程隔离开来,这样调用者就可以从一个耗时太长的依赖中隔离。如下图所示,也可以为不同的请求开启不同的线程池,彼此之间不相互干扰。


(注:上图右边表示的是信号量模式)
线程隔离
1、线程隔离的好处:
- 整个应用的即是在客户端调用失效的情况下也能健康的运行,线程池能够保证这个线程下面的失效不会影响应用其他部分的运行
- 当失效的客户端调用回复的时候,这个线程池也会被清理并且应用会立马回复健康,比tomcat那种长时间的恢复要好很多
简而言之,线程隔离能够允许在不引起中断的情况下优雅的处理第三方调用的各种问题。
2、线程隔离的缺点
- 主要缺点是增加了上下文切换的开销,每个明亮的执行都涉及到队列,调度和上下文切换。不过NetFix在设计这个系统的时候,已经决定接受这笔开销,以换取他的好处。
信号量隔离
你可以使用信号量(或者计数器)来限制当前依赖调用的并发数,而不是使用线程池或者队列。如果客户端是可信的,且能快速返回,可以使用信号量来代替线程隔离,降低开销。信号量的大小可以动态调节,线程池却不行。
HystrixCommand和HystrixObserverCommand提供信号量隔离在下面两个地方:
- Fallback:当Hystrix检索fallback的时候,他心总是调用tomcat线程上执行此操作
- 如果你设置execution.isolation.strategy为SEMAPHORE的时候,Hystrix会使用信号量代替线程池去限制当前调用Command的并发数。
请求合并
设置某个时间内的请求,合并为一个发送,例如:id和ids参数
请求缓存
仪表盘
Hystrix仪表盘
主要用来实时监控Hystrix的各项指标信息。通过Hystrix DashBoard反馈的实时信息,可以帮助我们快速防线系统中存在的问题,从而及时地采取对应措施。
开启仪表盘
1、在服务实例中新增spring-boot-starter-actuator,监控模块已开启监控相关的端点,并且映入断路器依赖:spring-cloud-starter-hystrix
2、确保在服务实例的主类中已经使用了@EnableCircuitBreaker注解,开启了断路器功能。

使用案例
1 | public class MyHystrixCommand extends HystrixCommand<String> { |
配置
几个主要的配置信息:在构造方法中通过Setter设置
1.1、execution.isolation. thread.timeoutinMilliseconds: 该属性用来配 置HystrixCommand执行的超时时间, 单位为毫秒。当HystrixCommand执行 时间超过该配置值之后, Hystrix会将该执行命令标记为TIMEOUT并进入服务降级 处理逻辑。默认值1000
1.2、execution.isolation.semaphore.maxConcurrentRequests:当HystrixCommand的隔离策略使用信号量的时候,该属性用来配置信号量的大小(并发请求数)。 当最大并发请求数达到该设置值时, 后续的请求将会被拒绝。默认值10
1.3、circuitBreaker.requestVolumeThreshold该属性设置滚动窗口中将使断路器跳闸的最小请求数量,默认值:20
1.4、circuitBreaker.sleepWindowInMilliseconds 断路器跳闸后,在此值的时间的内,hystrix会拒绝新的请求,只有过了这个时间断路器才会打开闸门
默认值:5000
1.5、circuitBreaker.errorThresholdPercentage 设置失败百分比的阈值。如果失败比率超过这个值,则断路器跳闸并且进入fallback逻辑
默认值:50
1.6、metrics.rollingStats.timeInMilliseconds 滚动窗口时间大小,默认10s
Feign了解多少说多少?
Feign
feign是声明式的web service客户端,它让微服务之间的调用变得更简单了,类似controller调用service。Spring Cloud集成了Ribbon和Eureka,可在使用Feign时提供负载均衡的http客户端。
因为feign底层是使用了ribbon作为负载均衡的客户端,而ribbon的负载均衡也是依赖于eureka 获得各个服务的地址,所以要引入eureka-client。
Feign原理
- 启动时,程序会进行包扫描,扫描所有包下所有@FeignClient注解的类,并将这些类注入到spring的IOC容器中。当定义的Feign中的接口被调用时,通过JDK的动态代理来生成RequestTemplate。
- RequestTemplate中包含请求的所有信息,如请求参数,请求URL等。
- RequestTemplate声场Request,然后将Request交给client处理,这个client默认是JDK的HTTPUrlConnection,也可以是OKhttp、Apache的HTTPClient等。
- 最后client封装成LoadBaLanceClient,结合ribbon负载均衡地发起调用。
Zookeeper,了解多少说多少?
ZooKeeper是一个分布式的开源协调服务,用于分布式应用程序。它公开了一组简单的原子操作,分布式应用程序可以构建这些原子操作,以实现更高级别的服务,以实现同步,配置维护以及组和命名。
它的设计易于编程,并使用在熟悉的文件系统目录树结构之后设计的数据模型。它运行在Java中,并且对Java和C都有绑定。
周所周知,协调服务是很难做到的。它们特别容易出现诸如竞态条件和死锁等错误。ZooKeeper背后的动机是减轻分布式应用程序从头开始实施协调服务的责任。
设计目标
Zookeeper是简单的。Zookeeper允许分布式进程之间彼此协调,通过一个共享的分级命名空间,它非常像标准的文件系统。
ZooKeeper实现非常重视高性能,高可用性,严格有序的访问。ZooKeeper的性能方面意味着它可以在大型分布式系统中使用。
可靠性方面使其不会成为单点故障。严格的排序意味着可以在客户端实现复杂的同步原子操作。
Zookeeper是可复制的。 与它协调的分布式进程一样,ZooKeeper本身也可以在称为集合的一组主机上进行复制。
组成ZooKeeper服务的服务器必须彼此了解。它们保持状态的内存映像,以及持久存储中的事务日志和快照。只要大多数服务器可用,ZooKeeper服务就可用。
客户端连接到单个ZooKeeper服务器。客户端维护一个TCP连接,通过它发送请求,获取响应,获取观看事件并发送心跳。如果与服务器的TCP连接中断,则客户端将连接到其他服务器。
Zookeeper是有序的。 ZooKeeper使用反映所有ZooKeeper事务顺序的数字标记每个更新。后续操作可以使用该顺序来实现更高级别的抽象,例如同步原子操作。
Zookeeper是非常快的。 它在“读取主导”工作负载中速度特别快。ZooKeeper应用程序在数千台计算机上运行,并且在读取比写入更常见的情况下表现最佳,比率大约为10:1。
数据模型和分层名称空间
ZooKeeper提供的名称空间非常类似于标准文件系统。名称是由斜线(/)分隔的一系列路径元素。ZooKeeper名称空间中的每个节点都由一个路径标识。
节点和临时节点
与标准文件系统不同的是,ZooKeeper命名空间中的每个节点都可以拥有与其相关的数据以及子级。这就像拥有一个允许文件也是目录的文件系统。(ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等,因此存储在每个节点的数据通常很小,在字节到千字节范围内。)我们使用术语 znode来表明我们正在谈论ZooKeeper数据节点。
Znodes维护一个stat结构,包括数据更改,ACL更改和时间戳的版本号,以允许缓存验证和协调更新。每次znode的数据更改时,版本号都会增加。例如,每当客户端检索数据时,它也会收到数据的版本。
存储在名称空间中每个节点上的数据是以原子方式读取和写入的。读取获取与znode关联的所有数据字节,写入将替换所有数据。每个节点都有一个访问控制列表(ACL),限制谁可以做什么。
ZooKeeper也有临时节点的概念。只要创建znode的会话处于活动状态,就会存在这些znode。当会话结束时,znode被删除。
有条件的更新和监视
ZooKeeper支持观察的概念。客户可以在znode上设置观察器。当znode更改时,将触发并删除观察器。
当观察被触发时,客户端收到一个数据包,说明znode已经改变。如果客户端和其中一个Zoo Keeper服务器之间的连接断开,客户端将收到本地通知。
担保
ZooKeeper非常快速且非常简单。但是,由于其目标是构建更复杂的服务(如同步)的基础,因此它提供了一系列保证。这些是:
- 顺序一致性 - 客户端的更新将按照它们发送的顺序进行应用。
- 原子性 - 更新成功或失败。没有部分结果。
- 单系统映像 - 无论服务器连接到哪个服务器,客户端都会看到相同的服务视图。
- 可靠性 - 一旦应用更新,它将一直持续到客户覆盖更新为止。
- 及时性 - 系统的客户视图保证在特定时间范围内是最新的。
简单的API
ZooKeeper的设计目标之一是提供一个非常简单的编程接口。因此,它仅支持以下操作:
- 创建——在树中的某个位置创建一个节点
- 删除——删除节点
- 存在——测试某个位置是否存在节点
- 获取数据——从节点读取数据
- 设定数据——将数据写入节点
- 得到子节点——检索节点的子节点列表
- 同步——等待数据传播
能用zookeeper做什么
1、 命名服务
这个似乎最简单,在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现,不见不散了。
2、 配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。好吧,现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
3、 集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。新机器加入 也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了。
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
4、 分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。厕所有言:来也冲冲,去也冲冲,用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
5、队列管理
两种类型的队列:
1、 同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
终于了解完我们能用zookeeper做什么了,可是作为一个程序员,我们总是想狂热了解zookeeper是如何做到这一点的,单点维护一个文件系统没有什么难度,可是如果是一个集群维护一个文件系统保持数据的一致性就非常困难了。
分布式与数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、 容错
一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力
把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能
让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster)
对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any)
对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
我们关注的重点还是在如何保证数据在集群所有机器的一致性,这就涉及到paxos算法。
数据一致性与paxos算法
据说Paxos算法的难理解与算法的知名度一样令人敬仰,所以我们先看如何保持数据的一致性,这里有个原则就是:
在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。
Paxos算法解决的什么问题呢,解决的就是保证每个节点执行相同的操作序列。好吧,这还不简单,master维护一个全局写队列,所有写操作都必 须放入这个队列编号,那么无论我们写多少个节点,只要写操作是按编号来的,就能保证一致性。没错,就是这样,可是如果master挂了呢。
Paxos算法通过投票来对写操作进行全局编号,同一时刻,只有一个写操作被批准,同时并发的写操作要去争取选票,只有获得过半数选票的写操作才会 被批准(所以永远只会有一个写操作得到批准),其他的写操作竞争失败只好再发起一轮投票,就这样,在日复一日年复一年的投票中,所有写操作都被严格编号排 序。编号严格递增,当一个节点接受了一个编号为100的写操作,之后又接受到编号为99的写操作(因为网络延迟等很多不可预见原因),它马上能意识到自己 数据不一致了,自动停止对外服务并重启同步过程。任何一个节点挂掉都不会影响整个集群的数据一致性(总2n+1台,除非挂掉大于n台)。
Paxos算法
角色(核心就3个角色)
Client:客户端,发起请求并等待返回。
Proposer(提案者):处理客户端请求,将客户端的请求发送到集群中,以便决定这个值是否可以被批准。
Acceptor(接受者):负责处理接收到的提议,他们的回复就是一次投票。会存储一些状态来决定是否接收一个值。
Learner(学习者):当有同一个value的协议被超过一半的Acceptor采纳并发送消息给Learner时,Learner采纳该协议值。
Leader:一个特殊的Proposer。
Basic-Paxos算法
核心实现Paxos Instance主要包括两个阶段:
准备阶段(prepare phase)和提议阶段(accept phase)
简单来说,Basic Paxos 是一个经典两阶段提交(2PC)
第一阶段:
- 1a prepare 准备: proposer向acceptors提出一个协议,这里的协议就是期望的“一致性内容”
- 1a promise 承诺: acceptor承诺只接收最大协议号的协议(包括prepare和accept),并拒绝比当前协议号N小的协议,回复proposer之前接收的所有协议值。如果当前协议号N比之前都小,那么回复拒绝。
第二阶段:
- 2a Accept Request 发起“accept”请求:proposer收到acceptor反馈的足够的承诺后,给协议设最大值,如果没回复,随便设置一个值。发送”accept”请求给选定值的acceptors.
- 2b Accepted: acceptor接受协议(该acceptor之前没有承诺过大于该协议号的协议),并通知给proposer和learner

其中prepare阶段的作用,如下图所示:
1.S1首先发起accept(1,red),并在S1,S2和S3达成多数派,red在S1,S2,S3上持久化
2.随 后S5发起accept(5,blue),在S3,S4和S5达成多数派,blue在S
3,S4和S5持久化
3.最后的结果是,S1和S2的值是red,而S4和S5的值是blue,s3存在异议,red覆盖了blue?
解决方案:
- 将提议进行排序,可以为每个提议赋予一个唯一的ID,规定这个ID越大越新,很明显(5,blue)和(1,red),5比1大,所以保留blue
- 采用两阶段方法,拒绝旧提议。
Muti-Paxos算法
很多文章有误解说Muti-Paxos是一阶段提交,那是仅限于leader稳定时。刚选出来一个新的leader时,依然是二阶段提交如下图:
如果leader稳定,不需要prepare和promise步骤,如下图(图中Proposer就是一个Leader):
Multi Paxos中leader用于避免活锁(例如1个leader,4个Proposer,2个提议A,2个提议B不能达成一致,导致活锁),但leader的存在会带来其他问题,一是如何选举和保持唯一leader(虽然无leader或多leader不影响一致性,但影响决议进程progress),二是充当leader的节点会承担更多压力,如何均衡节点的负载。Mencius[1]提出节点轮流担任leader,以达到均衡负载的目的;租约(lease)可以帮助实现唯一leader,但leader故障情况下可导致服务短期不可用。
Muti-Paxos在google chubby中的应用
Google Chubby是一个高可用分布式锁服务,被设计成一个需要访问中心化节点的分布式锁服务。本文只分析chubby服务端的实现。
Chubby服务端的基本架构大致分为三层
① 最底层是容错日志系统(Fault-Tolerant Log),通过Paxos算法能够保证集群所有机器上的日志完全一致,同时具备较好的容错性。
② 日志层之上是Key-Value类型的容错数据库(Fault-Tolerant DB),其通过下层的日志来保证一致性和容错性。
③ 存储层之上的就是Chubby对外提供的分布式锁服务和小文件存储服务。

Paxos算法用于保证集群内各个副本节点的日志能够保持一致,Chubby事务日志(Transaction Log)中的每一个Value对应Paxos算法中的一个Instance(对应Proposer),由于Chubby需要对外提供不断的服务,因此事务日志会无限增长,于是在整个Chubby运行过程中,会存在多个Paxos Instance,同时,Chubby会为每个Paxos Instance都按序分配一个全局唯一的Instance编号,并将其顺序写入到事务日志中去。
在Paxos中,每一个Paxos Instance都需要进行一轮或多轮的Prepare->Promise->Propose->Accept这样完整的二阶段请求过程来完成对一个提议值的选定,为了保证正确性的前提下尽可能地提高算法运行性能,可以让多个Instance共用一套序号分配机制,并将Prepare->Promise合并为一个阶段。具体做法如下:
① 当某个副本节点通过选举成为Master后,就会使用新分配的编号N来广播一个Prepare消息,该Prepare消息会被所有未达成一致的Instance和目前还未开始的Instance共用。
② 当Acceptor接收到Prepare消息后,必须对多个Instance同时做出回应,这通常可以通过将反馈信息封装在一个数据包中来实现,假设最多允许K个Instance同时进行提议值的选定,那么:
- 当前之多存在K个未达成一致的Instance,将这些未决的Instance各自最后接受的提议值封装进一个数据包,并作为Promise消息返回。
- 同时,判断N是否大于当前Acceptor的highestPromisedNum值(当前已经接受的最大的提议编号值),如果大于,那么就标记这些未决Instance和所有未来的Instance的highestPromisedNum的值为N,这样,这些未决Instance和所有未来Instance都不能再接受任何编号小于N的提议。
③ Master对所有未决Instance和所有未来Instance分别执行Propose->Accept阶段的处理,如果Master能够一直稳定运行的话,那么在接下来的算法运行过程中,就不再需要进行Prepare->Promise处理了。但是,一旦Master发现Acceptor返回了一个Reject消息,说明集群中存在另一个Master并且试图使用更大的提议编号发送了Prepare消息,此时,当前Master就需要重新分配新的提议编号并再次进行Prepare->Promise阶段的处理。
可见chubby就是一个典型的Muti-Paxos算法应用,在Master稳定运行的情况下,只需要使用同一个编号来依次执行每一个Instance的Promise->Accept阶段处理。
sentinel,了解多少说多少?
Sentinel 是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
Sentinel 和之前常用的熔断降级库 Netflix Hystrix 有什么异同呢?Sentinel官网有一个对比的文章,这里摘抄一个总结的表格
| 对比内容 | Sentinel | Hystrix |
|---|---|---|
| 隔离策略 | 信号量隔离 | 线程池隔离/信号量隔离 |
| 熔断降级策略 | 基于响应时间或失败比率 | 基于失败比率 |
| 实时指标实现 | 滑动窗口 | 滑动窗口(基于 RxJava) |
| 规则配置 | 支持多种数据源 | 支持多种数据源 |
| 扩展性 | 多个扩展点 | 插件的形式 |
| 基于注解的支持 | 支持 | 支持 |
| 限流 | 基于 QPS,支持基于调用关系的限流 | 不支持 |
| 流量整形 | 支持慢启动、匀速器模式 | 不支持 |
| 系统负载保护 | 支持 | 不支持 |
| 控制台 | 开箱即用,可配置规则、查看秒级监控、机器发现等 | 不完善 |
| 常见框架的适配 | Servlet、Spring Cloud、Dubbo、gRPC 等 | Servlet、Spring Cloud Netflix |
原理解析
感兴趣的可以看这篇文章
Spring Cloud Alibaba,了解多少说多少?
Spring Cloud 是基于 Spring Boot 设计的一套微服务规范,并增强了应用上下文。Spring Cloud Alibaba 采用阿里中间件作为基础,实现了 Spring Cloud 的微服务规范。
对XA、TCC的理解,了解哪些分布式事务框架,有什么缺点?
事务拥有以下四个特性,习惯上被称为 ACID 特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
常见分布式事务模型 ACID 实现分析
X/Open XA 协议
最早的分布式事务模型是 X/Open 国际联盟提出的 X/Open Distributed Transaction Processing(DTP)模型,也就是大家常说的 X/Open XA 协议,简称XA 协议。
DTP 模型中包含一个全局事务管理器(TM,Transaction Manager)和多个资源管理器(RM,Resource Manager)。全局事务管理器负责管理全局事务状态与参与的资源,协同资源一起提交或回滚;资源管理器则负责具体的资源操作。
XA 协议描述了 TM 与 RM 之间的接口,允许多个资源在同一分布式事务中访问。
基于 DTP 模型的分布式事务流程大致如下:

- 应用程序(AP,Application)向 TM 申请开始一个全局事务。
- 针对要操作的 RM,AP 会先向 TM 注册(TM 负责记录 AP 操作过哪些 RM,即分支事务),TM 通过 XA 接口函数通知相应 RM 开启分布式事务的子事务,接着 AP 就可以对该 RM 管理的资源进行操作。
- 当 AP 对所有 RM 操作完毕后,AP 根据执行情况通知 TM 提交或回滚该全局事务,TM 通过 XA 接口函数通知各 RM 完成操作。TM 会先要求各个 RM 做预提交,所有 RM 返回成功后,再要求各 RM 做正式提交,XA 协议要求,一旦 RM 预提交成功,则后续的正式提交也必须能成功;如果任意一个 RM 预提交失败,则 TM 通知各 RM 回滚。
- 所有 RM 提交或回滚完成后,全局事务结束。
原子性
XA 协议使用 2PC(Two Phase Commit,两阶段提交)原子提交协议来保证分布式事务原子性。
两阶段提交是指将提交过程分为两个阶段,即准备阶段(投票阶段)和提交阶段(执行阶段):

- 准备阶段
TM 向每个 RM 发送准备消息。如果 RM 的本地事务操作执行成功,则返回成功;如果 RM 的本地事务操作执行失败,则返回失败。
- 提交阶段
如果 TM 收到了所有 RM 回复的成功消息,则向每个 RM 发送提交消息;否则发送回滚消息;RM 根据 TM 的指令执行提交或者回滚本地事务操作,释放所有事务处理过程中使用的锁资源。
隔离性
XA 协议中没有描述如何实现分布式事务的隔离性,但是 XA 协议要求DTP 模型中的每个 RM 都要实现本地事务,也就是说,基于 XA 协议实现的分布式事务的隔离性是由每个 RM 本地事务的隔离性来保证的,当一个分布式事务的所有子事务都是隔离的,那么这个分布式事务天然的就实现了隔离性。
以 MySQL 来举例,MySQL 使用 2PL(Two-Phase Locking,两阶段锁)机制来控制本地事务的并发,保证隔离性。2PL 与 2PC 类似,也是将锁操作分为加锁和解锁两个阶段,并且保证两个阶段完全不相交。加锁阶段,只加锁,不放锁。解锁阶段,只放锁,不加锁。

如上图所示,在一个本地事务中,每执行一条更新操作之前,都会先获取对应的锁资源,只有获取锁资源成功才会执行该操作,并且一旦获取了锁资源就会持有该锁资源直到本事务执行结束。
MySQL 通过这种 2PL 机制,可以保证在本地事务执行过程中,其他并发事务不能操作相同资源,从而实现了事务隔离。
一致性
前面提到一致性有两层语义,一层是确保事务执行结束后,数据库从一个一致状态转变为另一个一致状态。另一层语义是事务执行过程中的中间状态不能被观察到。
前一层语义的实现很简单,通过原子性、隔离性以及 RM 自身一致性的实现就可以保证。至于后一层语义,我们先来看看单个 RM 上的本地事务是怎么实现的。还是以 MySQL 举例,MySQL 通过 MVCC(Multi Version Concurrency Control,多版本并发控制)机制,为每个一致性状态生成快照(Snapshot),每个事务看到的都是各Snapshot对应的一致性状态,从而也就保证了本地事务的中间状态不会被观察到。
虽然单个 RM 上实现了Snapshot,但是在分布式应用架构下,会遇到什么问题呢?
如上图所示,在 RM1 的本地子事务提交完毕到 RM2 的本地子事务提交完毕之间,只能读到 RM1 上子事务执行的内容,读不到 RM2 上的子事务。也就是说,虽然在单个 RM 上的本地事务是一致的,但是从全局来看,一个全局事务执行过程的中间状态被观察到了,全局一致性就被破坏了。
XA 协议并没有定义怎么实现全局的 Snapshot,像 MySQL 官方文档里就建议使用串行化的隔离级别来保证分布式事务一致性:
“As with nondistributed transactions, SERIALIZABLE may be preferred if your applications are sensitive to read phenomena. REPEATABLE READ may not be sufficient for distributed transactions.”(对于分布式事务来说,可重复读隔离级别不足以保证事务一致性,如果你的程序有全局一致性读要求,可以考虑串行化隔离级别.)
当然,由于串行化隔离级别的性能较差,所以很多分布式数据库都自己实现了分布式 MVCC 机制来提供全局的一致性读。一个基本思路是用一个集中式或者逻辑上单调递增的东西来控制生成全局 Snapshot,每个事务或者每条 SQL 执行时都去获取一次,从而实现不同隔离级别下的一致性。比如 Google 的 Spanner 就是用 TrueTime 来控制访问全局 Snapshot。
小结
XA 协议通常实现在数据库资源层,直接作用于资源管理器上。因此,基于 XA 协议实现的分布式事务产品,无论是分布式数据库,还是分布式事务框架,对业务几乎都没有侵入,就像使用普通数据库一样。
XA 协议严格保障事务 ACID 特性,能够满足所有业务领域的功能需求,但是,这同样是一把双刃剑。
由于隔离性的互斥要求,在事务执行过程中,所有的资源都被锁定,只适用于执行时间确定的短事务。同时,整个事务期间都是独占数据,对于热点数据的并发性能可能会很低,实现了分布式 MVCC 或乐观锁(optimistic locking)以后,性能可能会有所提升。
同时,为了保障一致性,要求所有 RM 同等可信、可靠,要求故障恢复机制可靠、快速,在网络故障隔离的情况下,服务基本不可用。
TCC 模型
TCC(Try-Confirm-Cancel)分布式事务模型相对于 XA 等传统模型,其特征在于它不依赖资源管理器(RM)对分布式事务的支持,而是通过对业务逻辑的分解来实现分布式事务。
TCC 模型认为对于业务系统中一个特定的业务逻辑,其对外提供服务时,必须接受一些不确定性,即对业务逻辑初步操作的调用仅是一个临时性操作,调用它的主业务服务保留了后续的取消权。如果主业务服务认为全局事务应该回滚,它会要求取消之前的临时性操作,这就对应从业务服务的取消操作。而当主业务服务认为全局事务应该提交时,它会放弃之前临时性操作的取消权,这对应从业务服务的确认操作。每一个初步操作,最终都会被确认或取消。
因此,针对一个具体的业务服务,TCC 分布式事务模型需要业务系统提供三段业务逻辑:
- 初步操作 Try:完成所有业务检查,预留必须的业务资源。
- 确认操作 Confirm:真正执行的业务逻辑,不作任何业务检查,只使用 Try 阶段预留的业务资源。因此,只要 Try 操作成功,Confirm 必须能成功。另外,Confirm 操作需满足幂等性,保证一笔分布式事务有且只能成功一次。
- 取消操作 Cancel:释放 Try 阶段预留的业务资源。同样的,Cancel 操作也需要满足幂等性。

TCC 分布式事务模型包括三部分:
- 主业务服务:主业务服务为整个业务活动的发起方,服务的编排者,负责发起并完成整个业务活动。
- 从业务服务:从业务服务是整个业务活动的参与方,负责提供 TCC 业务操作,实现初步操作(Try)、确认操作(Confirm)、取消操作(Cancel)三个接口,供主业务服务调用。
- 业务活动管理器:业务活动管理器管理控制整个业务活动,包括记录维护 TCC 全局事务的事务状态和每个从业务服务的子事务状态,并在业务活动提交时调用所有从业务服务的 Confirm 操作,在业务活动取消时调用所有从业务服务的 Cancel 操作。
一个完整的 TCC 分布式事务流程如下:
主业务服务首先开启本地事务;
主业务服务向业务活动管理器申请启动分布式事务主业务活动;
然后针对要调用的从业务服务,主业务活动先向业务活动管理器注册从业务活动,然后调用从业务服务的 Try 接口;
当所有从业务服务的 Try 接口调用成功,主业务服务提交本地事务;若调用失败,主业务服务回滚本地事务;
若主业务服务提交本地事务,则 TCC 模型分别调用所有从业务服务的 Confirm 接口;若主业务服务回滚本地事务,则分别调用 Cancel 接口;
所有从业务服务的 Confirm 或 Cancel 操作完成后,全局事务结束。
原子性
TCC 模型也使用 2PC 原子提交协议来保证事务原子性。Try 操作对应2PC 的一阶段准备(Prepare);Confirm 对应 2PC 的二阶段提交(Commit),Cancel 对应 2PC 的二阶段回滚(Rollback),可以说 TCC 就是应用层的 2PC。
隔离性
TCC 分布式事务模型仅提供两阶段原子提交协议,保证分布式事务原子性。事务的隔离交给业务逻辑来实现。
隔离的本质是控制并发,防止并发事务操作相同资源而引起的结果错乱。
举个例子,比如金融行业里管理用户资金,当用户发起交易时,一般会先检查用户资金,如果资金充足,则扣除相应交易金额,增加卖家资金,完成交易。如果没有事务隔离,用户同时发起两笔交易,两笔交易的检查都认为资金充足,实际上却只够支付一笔交易,结果两笔交易都支付成功,导致资损。
可以发现,并发控制是业务逻辑执行正确的保证,但是像两阶段锁这样的并发访问控制技术要求一直持有数据库资源锁直到整个事务执行结束,特别是在分布式事务架构下,要求持有锁到分布式事务第二阶段执行结束,也就是说,分布式事务会加长资源锁的持有时间,导致并发性能进一步下降。
因此,TCC 模型的隔离性思想就是通过业务的改造,在第一阶段结束之后,从底层数据库资源层面的加锁过渡为上层业务层面的加锁,从而释放底层数据库锁资源,放宽分布式事务锁协议,提高业务并发性能。
还是以上面的例子举例:
第一阶段:检查用户资金,如果资金充足,冻结用户本次交易资金,这笔资金被业务隔离,不允许除本事务之外的其它并发事务动用。
第二阶段:扣除第一阶段预冻结的用户资金,增加卖家资金,完成交易。
采用业务加锁的方式,隔离用户冻结资金,在第一阶段结束后直接释放底层资源锁,该用户和卖家的其他交易都可以立刻并发执行,而不用等到整个分布式事务结束,可以获得更高的并发交易能力。
一致性
再来看看 TCC 分布式事务模型下的一致性实现。与 XA 协议实现一致性第一层语义类似,通过原子性保证事务的原子提交、业务隔离性控制事务的并发访问,实现分布式事务的一致性状态转变。
至于第二层语义:事务的中间状态不能被观察到。我们来看看,在 SOA分布式应用环境下是否是必须的。
还是以账务服务举例。转账业务(用户 A -> 用户 B),由交易服务和账务服务组成分布式事务,交易服务作为主业务服务,账务服务作为从业务服务,账务服务的 Try 操作预冻结用户 A 的资金;Commit 操作扣除用户 A 的预冻结资金,增加用户 B 的可用资金;Cancel 操作解冻用户 A 的预冻结资金。
当账务服务执行完 Try 阶段后,交易主业务就可以 Commit 了,然后由TCC 框架调用账务的 Commit 阶段。在账务 Commit 阶段还没执行结束的时候,用户 A 可以查询到自己的余额已扣除,但是,此时用户 B 的可用资金还没增加。
从系统的角度来看,确实有问题与不确定性。在第一阶段执行结束到第二阶段执行结束之间,有一段时间的延时,在这段时间内,看似任何用户都不享有这笔资产。
但是,从用户的角度来考虑这个问题的话,这个时间间隔可能就无所谓或者根本就不存在。特别是当这个时间间隔仅仅是几秒钟,对于具体沟通资产转移的用户来讲,这个过程是隐蔽的或确实可以接受的,且保证了结果的最终一致性。
当然,对于这样的系统,如果确实需要查看系统的某个一致性状态,可以采用额外的方法实现。
一般来讲,服务之间的一致性比服务内部的一致性要更加容易弱化,这也是为什么 XA 等直接在资源层面上实现通用分布式事务的模型会注重一致性的保证,而当上升到服务层面,服务与服务之间已经实现了功能的划分,逻辑的解耦,也就更容易弱化一致性,这就是 SOA 架构下 BASE 理论的最终一致性思想。
BASE 理论是指 BA(Basic Availability,基本业务可用性);S(Soft state,柔性状态);E(Eventual consistency,最终一致性)。该理论认为为了可用性、性能与降级服务的需要,可以适当降低一点一致性的要求,即“基本可用,最终一致”。
业内通常把严格遵循 ACID 的事务称为刚性事务;而基于 BASE 思想实现的事务称为柔性事务。柔性事务并不是完全放弃了 ACID,仅仅是放宽了一致性要求:事务完成后的一致性严格遵循,事务中的一致性可适当放宽。
小结
TCC 分布式事务模型的业务实现特性决定了其可以跨 DB、跨服务实现资源管理,将对不同的 DB 访问、不同的业务操作通过 TCC 模型协调为一个原子操作,解决了分布式应用架构场景下的事务问题。
TCC 模型通过 2PC 原子提交协议保证分布式事务的的原子性,把资源层的隔离性上升到业务层,交给业务逻辑来实现。TCC 的每个操作对于资源层来说,就是单个本地事务的使用,操作结束则本地事务结束,规避了资源层在 2PC 和 2PL 下对资源占用导致的性能低下问题。
同时,TCC 模型也可以根据业务需要,做一些定制化的功能,比如交易异步化实现削峰填谷等。
但是,业务接入 TCC 模型需要拆分业务逻辑成两个阶段,并实现 Try、Confirm、Cancel 三个接口,定制化程度高,开发成本高。
总结
本文首先介绍了典型的分布式事务的架构场景。分布式事务刚开始是为解决单服务多数据库资源的场景而诞生的。随着技术的发展,特别是 SOA 分布式应用架构以及微服务时代的到来,服务变成了基本业务单元。因此,又产生了跨服务的分布式事务需求。
然后从 XA 和 TCC 两种常用的分布式事务模型入手,介绍了其实现机制,着重分析了各模型是如何实现分布式事务 ACID 特性的。