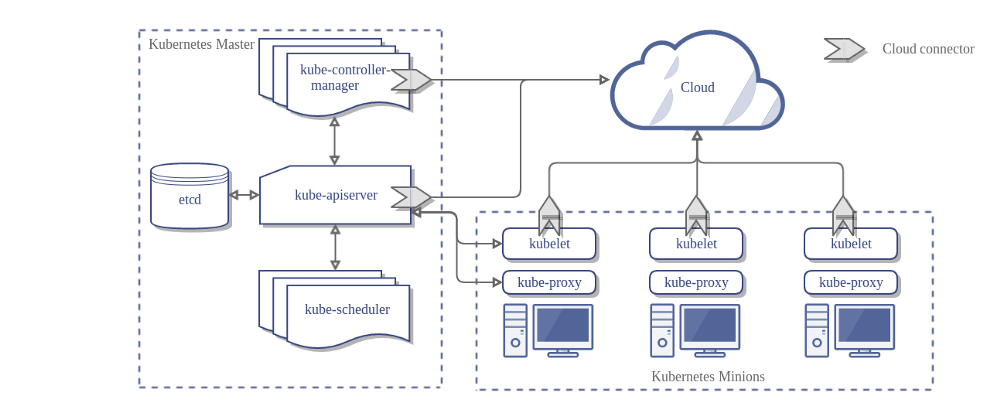
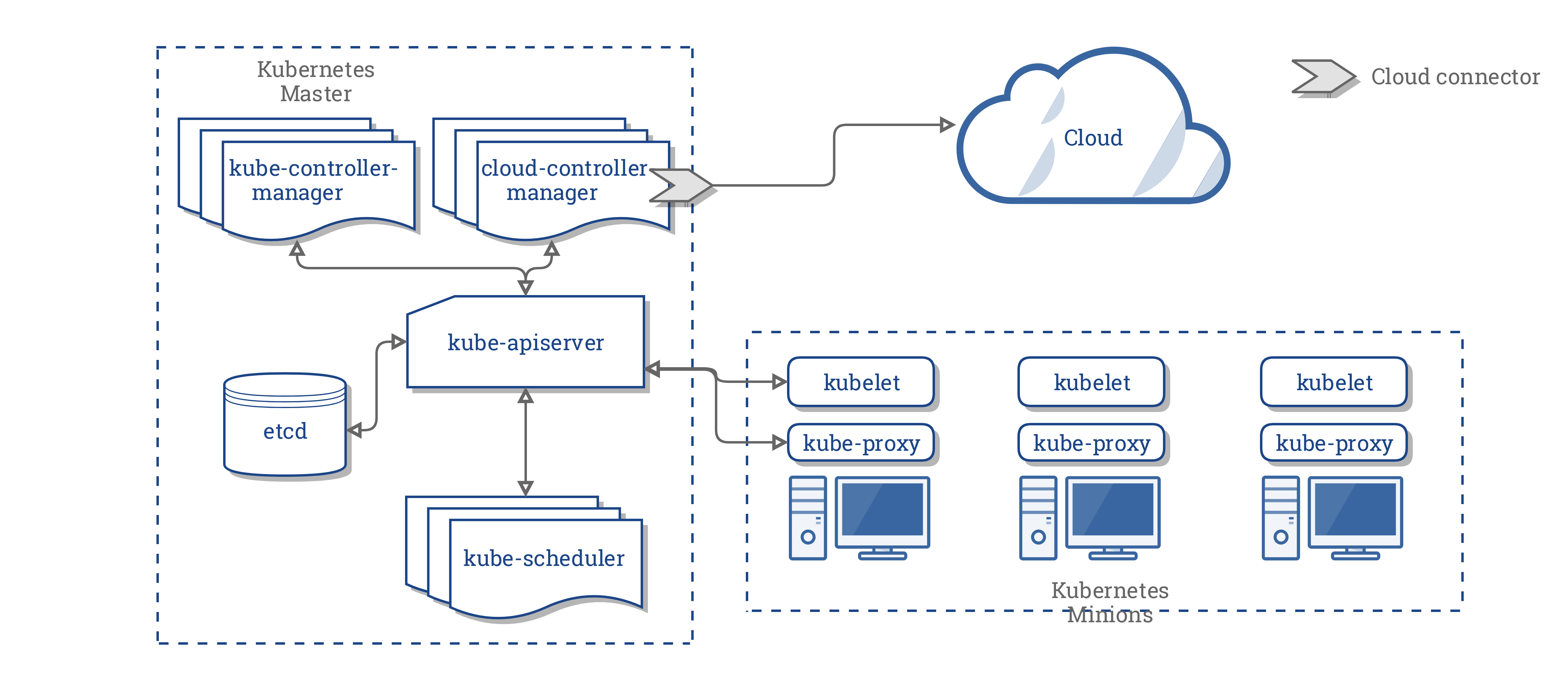
JAVA知识
ArrayList和LinkList有什么区别
- ArrayList是数组实现的集合操作,而LinkedList是链表实现的集合操作,(LinkedList是双向链表,有next也有previous)。
- 只是用List集合中的get()方法根据索引取数据的时候,ArrayList的时间复杂度为“O(1)”,而LinkedList的时间复杂度为“O(n)”(n为集合的长度),因为LinkedList要移动指针。
- ArrayList在使用的时候默认的初始化数组的长度为10,如果空间不足则会采用2倍的形式进行容量的扩充,如果保存大数据的时候有可能造成垃圾的产生以及性能的下降,这个时候就可以用LinkedList子类保存。对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
JDK动态代理与CGLib动态代理的区别
- 区别
- java动态代理是利用反射机制生成一个实现代理接口的匿名类,在调用具体方法前调用InvokeHandler来处理。
- 而cglib动态代理是利用asm开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
- 如果目标对象实现了接口,默认情况下会采用JDK的动态代理实现AOP
- 如果目标对象实现了接口,可以强制使用CGLIB实现AOP
- 如果目标对象没有实现了接口,必须采用CGLIB库,spring会自动在JDK动态代理和CGLIB之间转换
- 如何强制使用CGLIB实现AOP?
- 添加CGLIB库,
SPRING_HOME/cglib/*.jar - 在spring配置文件中加入
<aop:aspectj-autoproxy proxy-target-class="true"/>
- 添加CGLIB库,
JDK动态代理和CGLIB字节码生成的区别
- JDK动态代理只能对实现了接口的类生成代理,而不能针对类
- CGLIB是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法
因为是继承,所以该类或方法最好不要声明成final
代码实现
1 | package com.lf.shejimoshi.proxy.entity; |
Java中序列化有哪些方式
Java原生序列化
Java原生序列化方法即通过Java原生流(InputStream和OutputStream之间的转化)的方式进行转化。需要注意的是JavaBean实体类必须实现Serializable接口,否则无法序列化。Java原生序列化代码示例如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55package serialize;
import java.io.BufferedInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.List;
/**
*
* @author liqqc
*
*/
public class JavaSerialize {
public static void main(String[] args) throws ClassNotFoundException, IOException {
new JavaSerialize().start();
}
public void start() throws IOException, ClassNotFoundException {
User u = new User();
List<User> friends = new ArrayList<>();
u.setUserName("张三");
u.setPassWord("123456");
u.setUserInfo("张三是一个很牛逼的人");
u.setFriends(friends);
User f1 = new User();
f1.setUserName("李四");
f1.setPassWord("123456");
f1.setUserInfo("李四是一个很牛逼的人");
User f2 = new User();
f2.setUserName("王五");
f2.setPassWord("123456");
f2.setUserInfo("王五是一个很牛逼的人");
friends.add(f1);
friends.add(f2);
Long t1 = System.currentTimeMillis();
ByteArrayOutputStream out = new ByteArrayOutputStream();
ObjectOutputStream obj = new ObjectOutputStream(out);
for(int i = 0; i<10; i++) {
obj.writeObject(u);
}
System.out.println("java serialize: " +(System.currentTimeMillis() - t1) + "ms; 总大小:" + out.toByteArray().length );
Long t2 = System.currentTimeMillis();
ObjectInputStream ois = new ObjectInputStream(new BufferedInputStream(new java.io.ByteArrayInputStream(out.toByteArray())));
User user = (User) ois.readObject();
System.out.println("java deserialize: " + (System.currentTimeMillis() - t2) + "ms; User: " + user);
}
}
Json序列化
Json序列化一般会使用jackson包,通过ObjectMapper类来进行一些操作,比如将对象转化为byte数组或者将json串转化为对象。现在的大多数公司都将json作为服务器端返回的数据格式。比如调用一个服务器接口,通常的请求为xxx.json?a=xxx&b=xxx的形式。Json序列化示例代码如下所示:
1 | package serialize; |
FastJson序列化
fastjson 是由阿里巴巴开发的一个性能很好的Java 语言实现的 Json解析器和生成器。特点:速度快,测试表明fastjson具有极快的性能,超越任其他的java json parser。功能强大,完全支持java bean、集合、Map、日期、Enum,支持范型和自省。无依赖,能够直接运行在Java SE 5.0以上版本1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51package serialize;
import java.util.ArrayList;
import java.util.List;
import com.alibaba.fastjson.JSON;
/**
*
* @author liqqc
*
*/
public class FastJsonSerialize {
public static void main(String[] args) {
new FastJsonSerialize().start();
}
public void start(){
User u = new User();
List<User> friends = new ArrayList<>();
u.setUserName("张三");
u.setPassWord("123456");
u.setUserInfo("张三是一个很牛逼的人");
u.setFriends(friends);
User f1 = new User();
f1.setUserName("李四");
f1.setPassWord("123456");
f1.setUserInfo("李四是一个很牛逼的人");
User f2 = new User();
f2.setUserName("王五");
f2.setPassWord("123456");
f2.setUserInfo("王五是一个很牛逼的人");
friends.add(f1);
friends.add(f2);
//序列化
Long t1 = System.currentTimeMillis();
String text = null;
for(int i = 0; i<10; i++) {
text = JSON.toJSONString(u);
}
System.out.println("fastJson serialize: " +(System.currentTimeMillis() - t1) + "ms; 总大小:" + text.getBytes().length);
//反序列化
Long t2 = System.currentTimeMillis();
User user = JSON.parseObject(text, User.class);
System.out.println("fastJson serialize: " + (System.currentTimeMillis() -t2) + "ms; User: " + user);
}
}
ProtoBuff序列化
ProtocolBuffer是一种轻便高效的结构化数据存储格式,可以用于结构化数据序列化。适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。
- 优点:跨语言;序列化后数据占用空间比JSON小,JSON有一定- 的格式,在数据量上还有可以压缩的空间。
缺点:它以二进制的方式存储,无法直接读取编辑,除非你有 .proto 定义,否则无法直接读出 Protobuffer的任何内容。
其与thrift的对比:两者语法类似,都支持版本向后兼容和向前兼容,thrift侧重点是构建跨语言的可伸缩的服务,支持的语言多,同时提供了全套RPC解决方案,可以很方便的直接构建服务,不需要做太多其他的工作。 Protobuffer主要是一种序列化机制,在数据序列化上进行性能比较,Protobuffer相对较好。
ProtoBuff序列化对象可以很大程度上将其压缩,可以大大减少数据传输大小,提高系统性能。对于大量数据的缓存,也可以提高缓存中数据存储量。原始的ProtoBuff需要自己写.proto文件,通过编译器将其转换为java文件,显得比较繁琐。百度研发的jprotobuf框架将Google原始的protobuf进行了封装,对其进行简化,仅提供序列化和反序列化方法。其实用上也比较简洁,通过对JavaBean中的字段进行注解就行,不需要撰写.proto文件和实用编译器将其生成.java文件,百度的jprotobuf都替我们做了这些事情了。
一个带有jprotobuf注解的JavaBean如下所示1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128package serialize;
import java.io.Serializable;
import java.util.List;
import com.baidu.bjf.remoting.protobuf.FieldType;
import com.baidu.bjf.remoting.protobuf.annotation.Protobuf;
public class User implements Serializable {
private static final long serialVersionUID = -7890663945232864573L;
(fieldType = FieldType.INT32, required = false, order = 1)
private Integer userId;
(fieldType = FieldType.STRING, required = false, order = 2)
private String userName;
(fieldType = FieldType.STRING, required = false, order = 3)
private String passWord;
(fieldType = FieldType.STRING, required = false, order = 4)
private String userInfo;
(fieldType = FieldType.OBJECT, required = false, order = 5)
private List<User> friends;
public Integer getUserId() {
return userId;
}
public void setUserId(Integer userId) {
this.userId = userId;
}
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassWord() {
return passWord;
}
public void setPassWord(String passWord) {
this.passWord = passWord;
}
public String getUserInfo() {
return userInfo;
}
public void setUserInfo(String userInfo) {
this.userInfo = userInfo;
}
public List<User> getFriends() {
return friends;
}
public void setFriends(List<User> friends) {
this.friends = friends;
}
public String toString() {
return "User [userId=" + userId + ", userName=" + userName + ", passWord=" + passWord + ", userInfo=" + userInfo
+ ", friends=" + friends + "]";
}
}
package serialize;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import com.baidu.bjf.remoting.protobuf.Codec;
import com.baidu.bjf.remoting.protobuf.ProtobufProxy;
/**
*
* @author liqqc
*
*/
public class ProtoBuffSerialize {
public static void main(String[] args) throws IOException {
new ProtoBuffSerialize().start();
}
public void start() throws IOException {
Codec<User> studentClassCodec = ProtobufProxy.create(User.class, false);
User u2 = new User();
List<User> friends = new ArrayList<>();
u2.setUserName("张三");
u2.setPassWord("123456");
u2.setUserInfo("张三是一个很牛逼的人");
u2.setFriends(friends);
User f1 = new User();
f1.setUserName("李四");
f1.setPassWord("123456");
f1.setUserInfo("李四是一个很牛逼的人");
User f2 = new User();
f2.setUserName("王五");
f2.setPassWord("123456");
f2.setUserInfo("王五是一个很牛逼的人");
friends.add(f1);
friends.add(f2);
Long stime_jpb_encode = System.currentTimeMillis();
byte[] bytes = null;
for(int i = 0; i<10; i++) {
bytes = studentClassCodec.encode(u2);
}
System.out.println("jprotobuf序列化耗时:" + (System.currentTimeMillis() - stime_jpb_encode) + "ms; 总大小:" + bytes.length);
Long stime_jpb_decode = System.currentTimeMillis();
User user = studentClassCodec.decode(bytes);
Long etime_jpb_decode = System.currentTimeMillis();
System.out.println("jprotobuf反序列化耗时:"+ (etime_jpb_decode-stime_jpb_decode) + "ms; User: " + user);
}
}
序列化底层实现
1 | public class SerialDemo { |
object.out文件如下
注:上图中0000000h-000000c0h表示行号;0-f表示列;行后面的文字表示对这行16进制的解释;对上述字节码所表述的内容感兴趣的可以对照相关的资料,查阅一下每一个字符代表的含义,这里不在探讨!
类似于我们Java代码编译之后的.class文件,每一个字符都代表一定的含义。序列化和反序列化的过程就是生成和解析上述字符的过程!
序列化图示:
反序列化图示:
相关注意事项
1、序列化时,只对对象的状态进行保存,而不管对象的方法;
2、当一个父类实现序列化,子类自动实现序列化,不需要显式实现Serializable接口;
3、当一个对象的实例变量引用其他对象,序列化该对象时也把引用对象进行序列化;
4、并非所有的对象都可以序列化,至于为什么不可以,有很多原因了,比如:
安全方面的原因,比如一个对象拥有private,public等field,对于一个要传输的对象,比如写到文件,或者进行RMI传输等等,在序列化进行传输的过程中,这个对象的private等域是不受保护的;
资源分配方面的原因,比如socket,thread类,如果可以序列化,进行传输或者保存,也无法对他们进行重新的资源分配,而且,也是没有必要这样实现;
5、声明为static和transient类型的成员数据不能被序列化。因为static代表类的状态,transient代表对象的临时数据。
6、序列化运行时使用一个称为 serialVersionUID 的版本号与每个可序列化类相关联,该序列号在反序列化过程中用于验证序列化对象的发送者和接收者是否为该对象加载了与序列化兼容的类。为它赋予明确的值。显式地定义serialVersionUID有两种用途:
在某些场合,希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有相同的serialVersionUID;
在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
7、Java有很多基础类已经实现了serializable接口,比如String,Vector等。但是也有一些没有实现serializable接口的;
8、如果一个对象的成员变量是一个对象,那么这个对象的数据成员也会被保存!这是能用序列化解决深拷贝的重要原因;
并发编程的包,AQS和普通锁相比有什么好处
队列同步器AbstractQueuedSynchronizer,是用来构建锁或者其他同步组件的基础框架,它使用一个int成员表示同步状态,通过内部的FIFO队列来完成资源获取线程的排序工作。
AQS的设计
AQS的设计是基于模板方法模式的,也就是说,使用者需要继承AQS并重写指定的方法,随后将AQS组合在自定义同步组件的实现中,并调用AQS提供的模板方法,而这些模板方法将会调用使用者重写的方法。1
private volatile int state;
AQS使用一个int的成员变量来表示同步状态。1
2
3protected final void setState(int newState) {
state = newState;
}
setState方法用来设置同步状态1
2
3protected final int getState() {
return state;
}
getState方法用来获取同步状态1
2
3
4protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
compareAndSetState方法使用CAS操作来讲同步状态设置为给定的值
AQS中的同步队列
最开始就提到过AQS内部维护着一个FIFO的队列。而AQS就是依赖这个同步队列来完成同步状态的管理,当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构造成一个节点Node,并将其加入同步队列,同时会阻塞当前线程,当同步状态释放时,会把首节点中的线程唤醒,使其再次尝试获取同步状态。
同步队列中节点属性1
2//共享锁对应的节点
static final Node SHARED = new Node();
因为如果是共享锁,线程可以被多个线程获得。所以将这个属性定义为一个常量。
1
2 //独占锁对应的节点
static final Node EXCLUSIVE = null;
独占锁因为只能对一个线程获得,所以设置为null,当某个线程获得锁时,将该线程对应的赋予这个属性1
2//节点的等待状态
volatile int waitStatus;
节点的等待状态有4个
- CANCELLED:值为1,由于在同步队列中等待的线程等待超时或被中断,需要从同步队列中取消等待,节点进入该状态将不会变化
- SINGAL:值为-1,后继节点的线程处于等待状态,当前节点如果释放了同步状态,将会通知后继节点,使后继节点得以运行
- CONDITION:值为-2,节点在等待队列中(这个在Condition的博客里会讲到),节点线程等待在Condition上,当其他线程对Condition调用了singal后,该节点会从等待队列转移到同步队列,加入到对同步状态的获取中去
- PROPAGEATE:值为-3,表示下一次共享式同步状态获取将会无条件被传播下去
1
2//前驱节点,当节点加入同步队列时被设置(尾部添加)
volatile Node prev;
同步队列中某个节点的前驱节点1
2//后继节点
volatile Node next;
同步队列中某个节点的后继节点1
2//等待队列的后继节点。如果当前节点是共享的,那么这个字段将是一个SHARED常量
Node nextWaiter;
这个是等待队列的后继节点(不是同步队列)1
2//获取同步状态的线程
volatile Thread thread;
当前获取到同步状态的线程
节点时构成同步队列的基础,AQS拥有首节点和尾节点,没有成功获取到同步状态的节点会加入到同步队列的尾部,同步队列的结构如下图所示

同步器AQS包含两个节点类型的引用,一个指向头结点,一个指向尾节点。
同步队列的操作
- 将节点加入到同步队列:当一个线程成功获取了同步状态(或者锁),其他线程将无法获取到同步状态,转而被构造成节点并加入到同步队列中,而这个加入队列的过程必须要保证线程安全。AQS提供了一个基于CAS的设置尾节点的方法:compareAndSerTail,它需要传递当前线程认为的尾节点和当前节点,只有设置成功后,当前节点才正式与之前的尾节点建立关联。

- 将节点设置为首节点:同步队列遵循FIFO,首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,会唤醒后继节点,而后继节点将会在获取同步状态成功时将自己设置为首节点。

设置首节点是通过成功获取同步状态的线程完成的,由于只有一个线程能成功获取到同步状态,因此设置头节点并不需要使用CAS来保证,它只需要将首节点设置为原首节点的后继节点并断开原首节点的next引用即可。
synchronized底层实现,加在方法上和加在同步代码块中编译后的区别、类锁、对象锁。
概念
synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象。
一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞
1 | /** |
当两个并发线程(thread1和thread2)访问同一个对象(syncThread)中的synchronized代码块时,在同一时刻只能有一个线程得到执行,另一个线程受阻塞,必须等待当前线程执行完这个代码块以后才能执行该代码块。Thread1和thread2是互斥的,因为在执行synchronized代码块时会锁定当前的对象,只有执行完该代码块才能释放该对象锁,下一个线程才能执行并锁定该对象。
我们再把SyncThread的调用稍微改一下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Thread thread1 = new Thread(new SyncThread(), "SyncThread1");
Thread thread2 = new Thread(new SyncThread(), "SyncThread2");
thread1.start();
thread2.start();
//结果如下:
SyncThread1:0
SyncThread2:1
SyncThread1:2
SyncThread2:3
SyncThread1:4
SyncThread2:5
SyncThread2:6
SyncThread1:7
SyncThread1:8
SyncThread2:9
不是说一个线程执行synchronized代码块时其它的线程受阻塞吗?为什么上面的例子中thread1和thread2同时在执行。这是因为synchronized只锁定对象,每个对象只有一个锁(lock)与之相关联,而上面的代码等同于下面这段代码:1
2
3
4
5
6SyncThread syncThread1 = new SyncThread();
SyncThread syncThread2 = new SyncThread();
Thread thread1 = new Thread(syncThread1, "SyncThread1");
Thread thread2 = new Thread(syncThread2, "SyncThread2");
thread1.start();
thread2.start();
这时创建了两个SyncThread的对象syncThread1和syncThread2,线程thread1执行的是syncThread1对象中的synchronized代码(run),而线程thread2执行的是syncThread2对象中的synchronized代码(run);我们知道synchronized锁定的是对象,这时会有两把锁分别锁定syncThread1对象和syncThread2对象,而这两把锁是互不干扰的,不形成互斥,所以两个线程可以同时执行。
当一个线程访问对象的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该对象中的非synchronized(this)同步代码块。
多个线程访问synchronized和非synchronized代码块1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58class Counter implements Runnable{
private int count;
public Counter() {
count = 0;
}
public void countAdd() {
synchronized(this) {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
//非synchronized代码块,未对count进行读写操作,所以可以不用synchronized
public void printCount() {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + " count:" + count);
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void run() {
String threadName = Thread.currentThread().getName();
if (threadName.equals("A")) {
countAdd();
} else if (threadName.equals("B")) {
printCount();
}
}
}
//调用代码
Counter counter = new Counter();
Thread thread1 = new Thread(counter, "A");
Thread thread2 = new Thread(counter, "B");
thread1.start();
thread2.start();
//结果如下
A:0
B count:1
A:1
B count:2
A:2
B count:3
A:3
B count:4
A:4
B count:5
上面代码中countAdd是一个synchronized的,printCount是非synchronized的。从上面的结果中可以看出一个线程访问一个对象的synchronized代码块时,别的线程可以访问该对象的非synchronized代码块而不受阻塞。
指定要给某个对象加锁
1 | /** |
在AccountOperator 类中的run方法里,我们用synchronized 给account对象加了锁。这时,当一个线程访问account对象时,其他试图访问account对象的线程将会阻塞,直到该线程访问account对象结束。也就是说谁拿到那个锁谁就可以运行它所控制的那段代码。
当有一个明确的对象作为锁时,就可以用类似下面这样的方式写程序。1
2
3
4
5
6
7
8public void method3(SomeObject obj)
{
//obj 锁定的对象
synchronized(obj)
{
// todo
}
}
当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的对象来充当锁:1
2
3
4
5
6
7
8
9
10
11
12
13
14class Test implements Runnable
{
private byte[] lock = new byte[0]; // 特殊的instance变量
public void method()
{
synchronized(lock) {
// todo 同步代码块
}
}
public void run() {
}
}
说明:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
修饰一个方法
Synchronized修饰一个方法很简单,就是在方法的前面加synchronized,public synchronized void method(){//todo}; synchronized修饰方法和修饰一个代码块类似,只是作用范围不一样,修饰代码块是大括号括起来的范围,而修饰方法范围是整个函数。如将【Demo1】中的run方法改成如下的方式,实现的效果一样。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public synchronized void run() {
for (int i = 0; i < 5; i ++) {
try {
System.out.println(Thread.currentThread().getName() + ":" + (count++));
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
//Synchronized作用于整个方法的写法。
//写法一
public synchronized void method()
{
// todo
}
//写法二
public void method()
{
synchronized(this) {
// todo
}
}
写法一修饰的是一个方法,写法二修饰的是一个代码块,但写法一与写法二是等价的,都是锁定了整个方法时的内容。
在用synchronized修饰方法时要注意以下几点:
- synchronized关键字不能继承。
虽然可以使用synchronized来定义方法,但synchronized并不属于方法定义的一部分,因此,synchronized关键字不能被继承。如果在父类中的某个方法使用了synchronized关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized关键字才可以。当然,还可以在子类方法中调用父类中相应的方法,这样虽然子类中的方法不是同步的,但子类调用了父类的同步方法,因此,子类的方法也就相当于同步了。这两种方式的例子代码如下:
在子类方法中加上synchronized关键字1
2
3
4
5
6class Parent {
public synchronized void method() { }
}
class Child extends Parent {
public synchronized void method() { }
}
在子类方法中调用父类的同步方法1
2
3
4
5
6class Parent {
public synchronized void method() { }
}
class Child extends Parent {
public void method() { super.method(); }
}
- 在定义接口方法时不能使用synchronized关键字。
- 构造方法不能使用synchronized关键字,但可以使用synchronized代码块来进行同步。
修饰一个静态的方法
1 | /** |
syncThread1和syncThread2是SyncThread的两个对象,但在thread1和thread2并发执行时却保持了线程同步。这是因为run中调用了静态方法method,而静态方法是属于类的,所以syncThread1和syncThread2相当于用了同一把锁。这与Demo1是不同的。
修饰一个类
1 | /** |
其效果和【Demo5】是一样的,synchronized作用于一个类T时,是给这个类T加锁,T的所有对象用的是同一把锁。
总结
- 无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态方法或一个类,则它取得的锁是对类,该类所有的对象同一把锁。
- 每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码。
实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
锁升级的过程。
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象
- 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象
- 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象
Java中提供了两种实现同步的基础语义:synchronized方法和synchronized块
1 | public class SyncTest { |
当SyncTest.java被编译成class文件的时候,synchronized关键字和synchronized方法的字节码略有不同,我们可以用javap -v 命令查看class文件对应的JVM字节码信息,部分信息如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39{
public void syncBlock();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter // monitorenter指令进入同步块
4: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
7: ldc #3 // String hello block
9: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
12: aload_1
13: monitorexit // monitorexit指令退出同步块
14: goto 22
17: astore_2
18: aload_1
19: monitorexit // monitorexit指令退出同步块
20: aload_2
21: athrow
22: return
Exception table:
from to target type
4 14 17 any
17 20 17 any
public synchronized void syncMethod();
descriptor: ()V
flags: ACC_PUBLIC, ACC_SYNCHRONIZED //添加了ACC_SYNCHRONIZED标记
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #5 // String hello method
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
}
从上面的中文注释处可以看到,对于synchronized关键字而言,javac在编译时,会生成对应的monitorenter和monitorexit指令分别对应synchronized同步块的进入和退出,有两个monitorexit指令的原因是:为了保证抛异常的情况下也能释放锁,所以javac为同步代码块添加了一个隐式的try-finally,在finally中会调用monitorexit命令释放锁。而对于synchronized方法而言,javac为其生成了一个ACC_SYNCHRONIZED关键字,在JVM进行方法调用时,发现调用的方法被ACC_SYNCHRONIZED修饰,则会先尝试获得锁。
在JVM底层,对于这两种synchronized语义的实现大致相同。
锁的几种形式
传统的锁(也就是下文要说的重量级锁)依赖于系统的同步函数,在linux上使用mutex互斥锁,最底层实现依赖于futex,关于futex可以看我之前的文章,这些同步函数都涉及到用户态和内核态的切换、进程的上下文切换,成本较高。对于加了synchronized关键字但运行时并没有多线程竞争,或两个线程接近于交替执行的情况,使用传统锁机制无疑效率是会比较低的。
在JDK 1.6之前,synchronized只有传统的锁机制,因此给开发者留下了synchronized关键字相比于其他同步机制性能不好的印象。
在JDK 1.6引入了两种新型锁机制:偏向锁和轻量级锁,它们的引入是为了解决在没有多线程竞争或基本没有竞争的场景下因使用传统锁机制带来的性能开销问题。
在看这几种锁机制的实现前,我们先来了解下对象头,它是实现多种锁机制的基础。
对象头
因为在Java中任意对象都可以用作锁,因此必定要有一个映射关系,存储该对象以及其对应的锁信息(比如当前哪个线程持有锁,哪些线程在等待)。一种很直观的方法是,用一个全局map,来存储这个映射关系,但这样会有一些问题:需要对map做线程安全保障,不同的synchronized之间会相互影响,性能差;另外当同步对象较多时,该map可能会占用比较多的内存。
所以最好的办法是将这个映射关系存储在对象头中,因为对象头本身也有一些hashcode、GC相关的数据,所以如果能将锁信息与这些信息共存在对象头中就好了。
在JVM中,对象在内存中除了本身的数据外还会有个对象头,对于普通对象而言,其对象头中有两类信息:mark word和类型指针。另外对于数组而言还会有一份记录数组长度的数据。
类型指针是指向该对象所属类对象的指针,mark word用于存储对象的HashCode、GC分代年龄、锁状态等信息。在32位系统上mark word长度为32字节,64位系统上长度为64字节。为了能在有限的空间里存储下更多的数据,其存储格式是不固定的,在32位系统上各状态的格式如下:
可以看到锁信息也是存在于对象的mark word中的。当对象状态为偏向锁(biasable)时,mark word存储的是偏向的线程ID;当状态为轻量级锁(lightweight locked)时,mark word存储的是指向线程栈中Lock Record的指针;当状态为重量级锁(inflated)时,为指向堆中的monitor对象的指针。
重量级锁
重量级锁是我们常说的传统意义上的锁,其利用操作系统底层的同步机制去实现Java中的线程同步。
重量级锁的状态下,对象的mark word为指向一个堆中monitor对象的指针。
一个monitor对象包括这么几个关键字段:cxq(下图中的ContentionList),EntryList ,WaitSet,owner。
其中cxq ,EntryList ,WaitSet都是由ObjectWaiter的链表结构,owner指向持有锁的线程。
当一个线程尝试获得锁时,如果该锁已经被占用,则会将该线程封装成一个ObjectWaiter对象插入到cxq的队列尾部,然后暂停当前线程。当持有锁的线程释放锁前,会将cxq中的所有元素移动到EntryList中去,并唤醒EntryList的队首线程。
如果一个线程在同步块中调用了Object#wait方法,会将该线程对应的ObjectWaiter从EntryList移除并加入到WaitSet中,然后释放锁。当wait的线程被notify之后,会将对应的ObjectWaiter从WaitSet移动到EntryList中。
以上只是对重量级锁流程的一个简述,其中涉及到的很多细节,比如ObjectMonitor对象从哪来?释放锁时是将cxq中的元素移动到EntryList的尾部还是头部?notfiy时,是将ObjectWaiter移动到EntryList的尾部还是头部?
关于具体的细节,会在重量级锁的文章中分析。
轻量级锁
JVM的开发者发现在很多情况下,在Java程序运行时,同步块中的代码都是不存在竞争的,不同的线程交替的执行同步块中的代码。这种情况下,用重量级锁是没必要的。因此JVM引入了轻量级锁的概念。
线程在执行同步块之前,JVM会先在当前的线程的栈帧中创建一个Lock Record,其包括一个用于存储对象头中的 mark word(官方称之为Displaced Mark Word)以及一个指向对象的指针。下图右边的部分就是一个Lock Record。
加锁过程
在线程栈中创建一个Lock Record,将其obj(即上图的Object reference)字段指向锁对象。
直接通过CAS指令将Lock Record的地址存储在对象头的mark word中,如果对象处于无锁状态则修改成功,代表该线程获得了轻量级锁。如果失败,进入到步骤3。
如果是当前线程已经持有该锁了,代表这是一次锁重入。设置Lock Record第一部分(Displaced Mark Word)为null,起到了一个重入计数器的作用。然后结束。
走到这一步说明发生了竞争,需要膨胀为重量级锁。
解锁过程
遍历线程栈,找到所有obj字段等于当前锁对象的Lock Record。
如果Lock Record的Displaced Mark Word为null,代表这是一次重入,将obj设置为null后continue。
如果Lock Record的Displaced Mark Word不为null,则利用CAS指令将对象头的mark word恢复成为Displaced Mark Word。如果成功,则continue,否则膨胀为重量级锁。
偏向锁
Java是支持多线程的语言,因此在很多二方包、基础库中为了保证代码在多线程的情况下也能正常运行,也就是我们常说的线程安全,都会加入如synchronized这样的同步语义。但是在应用在实际运行时,很可能只有一个线程会调用相关同步方法。比如下面这个demo:
1 | import java.util.ArrayList; |
在这个demo中为了保证对list操纵时线程安全,对addString方法加了synchronized的修饰,但实际使用时却只有一个线程调用到该方法,对于轻量级锁而言,每次调用addString时,加锁解锁都有一个CAS操作;对于重量级锁而言,加锁也会有一个或多个CAS操作(这里的’一个‘、’多个‘数量词只是针对该demo,并不适用于所有场景)。
在JDK1.6中为了提高一个对象在一段很长的时间内都只被一个线程用做锁对象场景下的性能,引入了偏向锁,在第一次获得锁时,会有一个CAS操作,之后该线程再获取锁,只会执行几个简单的命令,而不是开销相对较大的CAS命令。我们来看看偏向锁是如何做的。
对象创建
当JVM启用了偏向锁模式(1.6以上默认开启),当新创建一个对象的时候,如果该对象所属的class没有关闭偏向锁模式(什么时候会关闭一个class的偏向模式下文会说,默认所有class的偏向模式都是是开启的),那新创建对象的mark word将是可偏向状态,此时mark word中的thread id(参见上文偏向状态下的mark word格式)为0,表示未偏向任何线程,也叫做匿名偏向(anonymously biased)。
加锁过程
case 1:当该对象第一次被线程获得锁的时候,发现是匿名偏向状态,则会用CAS指令,将mark word中的thread id由0改成当前线程Id。如果成功,则代表获得了偏向锁,继续执行同步块中的代码。否则,将偏向锁撤销,升级为轻量级锁。
case 2:当被偏向的线程再次进入同步块时,发现锁对象偏向的就是当前线程,在通过一些额外的检查后(细节见后面的文章),会往当前线程的栈中添加一条Displaced Mark Word为空的Lock Record中,然后继续执行同步块的代码,因为操纵的是线程私有的栈,因此不需要用到CAS指令;由此可见偏向锁模式下,当被偏向的线程再次尝试获得锁时,仅仅进行几个简单的操作就可以了,在这种情况下,synchronized关键字带来的性能开销基本可以忽略。
case 3.当其他线程进入同步块时,发现已经有偏向的线程了,则会进入到撤销偏向锁的逻辑里,一般来说,会在safepoint中去查看偏向的线程是否还存活,如果存活且还在同步块中则将锁升级为轻量级锁,原偏向的线程继续拥有锁,当前线程则走入到锁升级的逻辑里;如果偏向的线程已经不存活或者不在同步块中,则将对象头的mark word改为无锁状态(unlocked),之后再升级为轻量级锁。
由此可见,偏向锁升级的时机为:当锁已经发生偏向后,只要有另一个线程尝试获得偏向锁,则该偏向锁就会升级成轻量级锁。当然这个说法不绝对,因为还有批量重偏向这一机制。
解锁过程
当有其他线程尝试获得锁时,是根据遍历偏向线程的lock record来确定该线程是否还在执行同步块中的代码。因此偏向锁的解锁很简单,仅仅将栈中的最近一条lock record的obj字段设置为null。需要注意的是,偏向锁的解锁步骤中并不会修改对象头中的thread id。
下图展示了锁状态的转换流程:

另外,偏向锁默认不是立即就启动的,在程序启动后,通常有几秒的延迟,可以通过命令 -XX:BiasedLockingStartupDelay=0来关闭延迟。
批量重偏向与撤销
从上文偏向锁的加锁解锁过程中可以看出,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时将偏向锁撤销为无锁状态或升级为轻量级/重量级锁。safe point这个词我们在GC中经常会提到,其代表了一个状态,在该状态下所有线程都是暂停的(大概这么个意思),详细可以看这篇文章。总之,偏向锁的撤销是有一定成本的,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降。因此,JVM中增加了一种批量重偏向/撤销的机制。
存在如下两种情况:
一个线程创建了大量对象并执行了初始的同步操作,之后在另一个线程中将这些对象作为锁进行之后的操作。这种case下,会导致大量的偏向锁撤销操作。
存在明显多线程竞争的场景下使用偏向锁是不合适的,例如生产者/消费者队列。
批量重偏向(bulk rebias)机制是为了解决第一种场景。批量撤销(bulk revoke)则是为了解决第二种场景。
其做法是:以class为单位,为每个class维护一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的mark word中也有该字段,其初始值为创建该对象时,class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其mark word的Thread Id 改成当前线程Id。
当达到重偏向阈值后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
Java运行时区域及各个区域的作用、对GC的了解、Java内存模型及为什么要这么设计?
Java运行时区域及各个区域的作用
Java虚拟机所管理的内存将会包括一下几个运行时数据区域

程序计数器
程序计数器(Program Counter Register) 是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条执行字节码指令。
每条线程都有一个独立的程序计数器。
如果执行的是java方法,这个计数器记录的是正在执行的虚拟机字节码指令地址。如果是native方法,计数器为空。此内存区域是唯一一个在java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
Java虚拟机栈
同样是线程私有,描述Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。一个方法对应一个栈帧。
局部变量表存放了各种基本类型、对象引用和returnAddress类型(指向了一条字节码指令地址)。其中64位长度long 和 double占两个局部变量空间,其他只占一个。
规定的异常情况有两种:1.线程请求的栈的深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;2.如果虚拟机可以动态扩展,如果扩展时无法申请到足够的内存,就抛出OutOfMemoryError异常。
本地方法栈
和Java虚拟机栈很类似,不同的是本地方法栈为Native方法服务。
Java堆
是Java虚拟机所管理的内存中最大的一块。由所有线程共享,在虚拟机启动时创建。堆区唯一目的就是存放对象实例。
堆中可细分为新生代和老年代,再细分可分为Eden空间、From Survivor空间、To Survivor空间。
堆无法扩展时,抛出OutOfMemoryError异常
方法区
所有线程共享,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
当方法区无法满足内存分配需求时,抛出OutOfMemoryError
运行时常量池
它是方法区的一部分,Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项是常量池(Const Pool Table),用于存放编译期生成的各种字面量和符号引用。并非预置入Class文件中常量池的内容才进入方法运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较多的便是String类的intern()方法。
当方法区无法满足内存分配需求时,抛出OutOfMemoryError
直接内存
并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域。
JDK1.4加入了NIO,引入一种基于通道与缓冲区的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。因为避免了在Java堆和Native堆中来回复制数据,提高了性能。
当各个内存区域总和大于物理内存限制,抛出OutOfMemoryError异常。
GC相关
jvm 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 java 堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的。

GC的对象
需要进行回收的对象就是已经没有存活的对象,判断一个对象是否存活常用的有两种办法:引用计数和可达分析。
- 引用计数:每个对象有一个引用计数属性,新增一个引用时计数加1,引用释放时计数减1,计数为0时可以回收。此方法简单,无法解决对象相互循环引用的问题。
- 可达性分析(Reachability Analysis):从GC Roots开始向下搜索,搜索所走过的路径称为引用链。当一个对象到GC Roots没有任何引用链相连时,则证明此对象是不可用的。不可达对象。
1
2
3
4
5
6
7
8
9在Java语言中,GC Roots包括:
虚拟机栈中引用的对象。
方法区中类静态属性实体引用的对象。
方法区中常量引用的对象。
本地方法栈中JNI引用的对象。
什么时候触发GC
- 程序调用System.gc时可以触发
- 系统自身来决定GC触发的时机(根据Eden区和From Space区的内存大小来决定。当内存大小不足时,则会启动GC线程并停止应用线程)
1 | GC又分为 minor GC 和 Full GC (也称为 Major GC ) |
GC常用算法
GC常用算法有:标记-清除算法,标记-压缩算法,复制算法,分代收集算法。
目前主流的JVM(HotSpot)采用的是分代收集算法。
标记-清除算法
为每个对象存储一个标记位,记录对象的状态(活着或是死亡)。分为两个阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
优点
最大的优点是,标记—清除算法中每个活着的对象的引用只需要找到一个即可,找到一个就可以判断它为活的。此外,更重要的是,这个算法并不移动对象的位置。
缺点
它的缺点就是效率比较低(递归与全堆对象遍历)。每个活着的对象都要在标记阶段遍历一遍;所有对象都要在清除阶段扫描一遍,因此算法复杂度较高。没有移动对象,导致可能出现很多碎片空间无法利用的情况。

标记-压缩算法(标记-整理)
标记-压缩法是标记-清除法的一个改进版。同样,在标记阶段,该算法也将所有对象标记为存活和死亡两种状态;不同的是,在第二个阶段,该算法并没有直接对死亡的对象进行清理,而是将所有存活的对象整理一下,放到另一处空间,然后把剩下的所有对象全部清除。这样就达到了标记-整理的目的。
- 优点
该算法不会像标记-清除算法那样产生大量的碎片空间。 - 缺点
如果存活的对象过多,整理阶段将会执行较多复制操作,导致算法效率降低。
左边是标记阶段,右边是整理之后的状态。可以看到,该算法不会产生大量碎片内存空间。
复制算法
该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。
注意:
这个算法与标记-整理算法的区别在于,该算法不是在同一个区域复制,而是将所有存活的对象复制到另一个区域内。
- 优点
实现简单;不产生内存碎片 - 缺点
每次运行,总有一半内存是空的,导致可使用的内存空间只有原来的一半。
分代收集算法
现在的虚拟机垃圾收集大多采用这种方式,它根据对象的生存周期,将堆分为新生代(Young)和老年代(Tenure)。在新生代中,由于对象生存期短,每次回收都会有大量对象死去,那么这时就采用复制算法。老年代里的对象存活率较高,没有额外的空间进行分配担保,所以可以使用标记-整理 或者 标记-清除。
具体过程:新生代(Young)分为Eden区,From区与To区

当系统创建一个对象的时候,总是在Eden区操作,当这个区满了,那么就会触发一次YoungGC,也就是年轻代的垃圾回收。一般来说这时候不是所有的对象都没用了,所以就会把还能用的对象复制到From区。

这样整个Eden区就被清理干净了,可以继续创建新的对象,当Eden区再次被用完,就再触发一次YoungGC,然后呢,注意,这个时候跟刚才稍稍有点区别。这次触发YoungGC后,会将Eden区与From区还在被使用的对象复制到To区,

再下一次YoungGC的时候,则是将Eden区与To区中的还在被使用的对象复制到From区。

经过若干次YoungGC后,有些对象在From与To之间来回游荡,这时候From区与To区亮出了底线(阈值),这些家伙要是到现在还没挂掉,对不起,一起滚到(复制)老年代吧。

老年代经过这么几次折腾,也就扛不住了(空间被用完),好,那就来次集体大扫除(Full GC),也就是全量回收。如果Full GC使用太频繁的话,无疑会对系统性能产生很大的影响。所以要合理设置年轻代与老年代的大小,尽量减少Full GC的操作。
垃圾收集器
如果说收集算法是内存回收的方法论,垃圾收集器就是内存回收的具体实现
Serial收集器
串行收集器是最古老,最稳定以及效率高的收集器
可能会产生较长的停顿,只使用一个线程去回收
-XX:+UseSerialGC
- 新生代、老年代使用串行回收
- 新生代复制算法
- 老年代标记-压缩

并行收集器
ParNew
-XX:+UseParNewGC(new代表新生代,所以适用于新生代)- 新生代并行
- 老年代串行
Serial收集器新生代的并行版本
在新生代回收时使用复制算法
多线程,需要多核支持
-XX:ParallelGCThreads 限制线程数量
- Parallel收集器
类似ParNew
新生代复制算法
老年代标记-压缩
更加关注吞吐量
-XX:+UseParallelGC- 使用Parallel收集器+ 老年代串行
-XX:+UseParallelOldGC - 使用Parallel收集器+ 老年代并行
- 使用Parallel收集器+ 老年代串行

其他GC参数
-XX:MaxGCPauseMills
- 最大停顿时间,单位毫秒
- GC尽力保证回收时间不超过设定值
-XX:GCTimeRatio
- 0-100的取值范围
- 垃圾收集时间占总时间的比
- 默认99,即最大允许1%时间做GC
这两个参数是矛盾的。因为停顿时间和吞吐量不可能同时调优
CMS收集器
- Concurrent Mark Sweep 并发标记清除(应用程序线程和GC线程交替执行)
- 使用标记-清除算法
- 并发阶段会降低吞吐量(停顿时间减少,吞吐量降低)
- 老年代收集器(新生代使用ParNew)
- -XX:+UseConcMarkSweepGC
CMS运行过程比较复杂,着重实现了标记的过程,可分为
- 初始标记(会产生全局停顿)
- 根可以直接关联到的对象
- 速度快
- 并发标记(和用户线程一起)
- 主要标记过程,标记全部对象
- 重新标记 (会产生全局停顿)
- 由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
- 并发清除(和用户线程一起)
- 基于标记结果,直接清理对象

这里就能很明显的看出,为什么CMS要使用标记清除而不是标记压缩,如果使用标记压缩,需要多对象的内存位置进行改变,这样程序就很难继续执行。但是标记清除会产生大量内存碎片,不利于内存分配。
CMS收集器特点:
- 尽可能降低停顿
- 会影响系统整体吞吐量和性能
- 比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半
- 清理不彻底
- 因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理
- 因为和用户线程一起运行,不能在空间快满时再清理(因为也许在并发GC的期间,用户线程又申请了大量内存,导致内存不够)
- -XX:CMSInitiatingOccupancyFraction设置触发GC的阈值
- 如果不幸内存预留空间不够,就会引起concurrent mode failure
一旦 concurrent mode failure产生,将使用串行收集器作为后备。
CMS也提供了整理碎片的参数:
- -XX:+ UseCMSCompactAtFullCollection Full GC后,进行一次整理
整理过程是独占的,会引起停顿时间变长
-XX:+CMSFullGCsBeforeCompaction
- 设置进行几次Full GC后,进行一次碎片整理
-XX:ParallelCMSThreads
- 设定CMS的线程数量(一般情况约等于可用CPU数量)
CMS的提出是想改善GC的停顿时间,在GC过程中的确做到了减少GC时间,但是同样导致产生大量内存碎片,又需要消耗大量时间去整理碎片,从本质上并没有改善时间。
G1收集器
G1是目前技术发展的最前沿成果之一,HotSpot开发团队赋予它的使命是未来可以替换掉JDK1.5中发布的CMS收集器。
与CMS收集器相比G1收集器有以下特点:
(1) 空间整合,G1收集器采用标记整理算法,不会产生内存空间碎片。分配大对象时不会因为无法找到连续空间而提前触发下一次GC。
(2)可预测停顿,这是G1的另一大优势,降低停顿时间是G1和CMS的共同关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为N毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒,这几乎已经是实时Java(RTSJ)的垃圾收集器的特征了。
上面提到的垃圾收集器,收集的范围都是整个新生代或者老年代,而G1不再是这样。使用G1收集器时,Java堆的内存布局与其他收集器有很大差别,它将整个Java堆划分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔阂了,它们都是一部分(可以不连续)Region的集合。
G1的新生代收集跟ParNew类似,当新生代占用达到一定比例的时候,开始出发收集。
和CMS类似,G1收集器收集老年代对象会有短暂停顿。
步骤:
(1)标记阶段,首先初始标记(Initial-Mark),这个阶段是停顿的(Stop the World Event),并且会触发一次普通Mintor GC。对应GC log:GC pause (young) (inital-mark)
(2)Root Region Scanning,程序运行过程中会回收survivor区(存活到老年代),这一过程必须在young GC之前完成。
(3)Concurrent Marking,在整个堆中进行并发标记(和应用程序并发执行),此过程可能被young GC中断。在并发标记阶段,若发现区域对象中的所有对象都是垃圾,那个这个区域会被立即回收(图中打X)。同时,并发标记过程中,会计算每个区域的对象活性(区域中存活对象的比例)。

(4)Remark, 再标记,会有短暂停顿(STW)。再标记阶段是用来收集 并发标记阶段 产生新的垃圾(并发阶段和应用程序一同运行);G1中采用了比CMS更快的初始快照算法:snapshot-at-the-beginning (SATB)。
(5)Copy/Clean up,多线程清除失活对象,会有STW。G1将回收区域的存活对象拷贝到新区域,清除Remember Sets,并发清空回收区域并把它返回到空闲区域链表中。

(6)复制/清除过程后。回收区域的活性对象已经被集中回收到深蓝色和深绿色区域。
finalize()方法详解
finalize的作用
(1)finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
(2)finalize()与C++中的析构函数不是对应的。C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性
(3)不建议用finalize方法完成“非内存资源”的清理工作,但建议用于:
① 清理本地对象(通过JNI创建的对象);
② 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法
finalize的问题
(1)一些与finalize相关的方法,由于一些致命的缺陷,已经被废弃了,如System.runFinalizersOnExit()方法、Runtime.runFinalizersOnExit()方法
(2)System.gc()与System.runFinalization()方法增加了finalize方法执行的机会,但不可盲目依赖它们
(3)Java语言规范并不保证finalize方法会被及时地执行、而且根本不会保证它们会被执行
(4)finalize方法可能会带来性能问题。因为JVM通常在单独的低优先级线程中完成finalize的执行
(5)对象再生问题:finalize方法中,可将待回收对象赋值给GC Roots可达的对象引用,从而达到对象再生的目的
(6)finalize方法至多由GC执行一次(用户当然可以手动调用对象的finalize方法,但并不影响GC对finalize的行为)
finalize的执行过程(生命周期)
(1) 首先,大致描述一下finalize流程:当对象变成(GC Roots)不可达时,GC会判断该对象是否覆盖了finalize方法,若未覆盖,则直接将其回收。否则,若对象未执行过finalize方法,将其放入F-Queue队列,由一低优先级线程执行该队列中对象的finalize方法。执行finalize方法完毕后,GC会再次判断该对象是否可达,若不可达,则进行回收,否则,对象“复活”。
(2) 具体的finalize流程:
对象可由两种状态,涉及到两类状态空间,一是终结状态空间 F = {unfinalized, finalizable, finalized};二是可达状态空间 R = {reachable, finalizer-reachable, unreachable}。各状态含义如下:
- unfinalized: 新建对象会先进入此状态,GC并未准备执行其finalize方法,因为该对象是可达的
- finalizable: 表示GC可对该对象执行finalize方法,GC已检测到该对象不可达。正如前面所述,GC通过F-Queue队列和一专用线程完成finalize的执行
- finalized: 表示GC已经对该对象执行过finalize方法
reachable: 表示GC Roots引用可达 - finalizer-reachable(f-reachable):表示不是reachable,但可通过某个finalizable对象可达
- unreachable:对象不可通过上面两种途径可达
状态变迁图:

变迁说明:
(1)新建对象首先处于[reachable, unfinalized]状态(A)
(2)随着程序的运行,一些引用关系会消失,导致状态变迁,从reachable状态变迁到f-reachable(B, C, D)或unreachable(E, F)状态
(3)若JVM检测到处于unfinalized状态的对象变成f-reachable或unreachable,JVM会将其标记为finalizable状态(G,H)。若对象原处于[unreachable, unfinalized]状态,则同时将其标记为f-reachable(H)。
(4)在某个时刻,JVM取出某个finalizable对象,将其标记为finalized并在某个线程中执行其finalize方法。由于是在活动线程中引用了该对象,该对象将变迁到(reachable, finalized)状态(K或J)。该动作将影响某些其他对象从f-reachable状态重新回到reachable状态(L, M, N)
(5)处于finalizable状态的对象不能同时是unreahable的,由第4点可知,将对象finalizable对象标记为finalized时会由某个线程执行该对象的finalize方法,致使其变成reachable。这也是图中只有八个状态点的原因
(6)程序员手动调用finalize方法并不会影响到上述内部标记的变化,因此JVM只会至多调用finalize一次,即使该对象“复活”也是如此。程序员手动调用多少次不影响JVM的行为
(7)若JVM检测到finalized状态的对象变成unreachable,回收其内存(I)
(8)若对象并未覆盖finalize方法,JVM会进行优化,直接回收对象(O)
(9)注:System.runFinalizersOnExit()等方法可以使对象即使处于reachable状态,JVM仍对其执行finalize方法
总结
根据GC的工作原理,我们可以通过一些技巧和方式,让GC运行更加有效率,更加符合应用程序的要求。一些关于程序设计的几点建议:
1.最基本的建议就是尽早释放无用对象的引用。大多数程序员在使用临时变量的时候,都是让引用变量在退出活动域(scope)后,自动设置为 null.我们在使用这种方式时候,必须特别注意一些复杂的对象图,例如数组,队列,树,图等,这些对象之间有相互引用关系较为复杂。对于这类对象,GC 回收它们一般效率较低。如果程序允许,尽早将不用的引用对象赋为null.这样可以加速GC的工作。
2.尽量少用finalize函数。finalize函数是Java提供给程序员一个释放对象或资源的机会。但是,它会加大GC的工作量,因此尽量少采用finalize方式回收资源。
3.如果需要使用经常使用的图片,可以使用soft应用类型。它可以尽可能将图片保存在内存中,供程序调用,而不引起OutOfMemory.
4.注意集合数据类型,包括数组,树,图,链表等数据结构,这些数据结构对GC来说,回收更为复杂。另外,注意一些全局的变量,以及一些静态变量。这些变量往往容易引起悬挂对象(dangling reference),造成内存浪费。
5.当程序有一定的等待时间,程序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。使用增量式GC可以缩短Java程序的暂停时间。
countDownLatch用过没有,在项目中如何使用的,对AQS的了解。
介绍
- countDownLatch是在java1.5被引入,跟它一起被引入的工具类还有CyclicBarrier、Semaphore、concurrentHashMap和BlockingQueue。
- 存在于java.util.cucurrent包下。
- countDownLatch这个类使一个线程等待其他线程各自执行完毕后再执行。
- 是通过一个计数器来实现的,计数器的初始值是线程的数量。每当一个线程执行完毕后,计数器的值就-1,当计数器的值为0时,表示所有线程都执行完毕,然后在闭锁上等待的线程就可以恢复工作了。
类中有三个方法是最重要的1
2
3
4
5
6//调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
public void await() throws InterruptedException { };
//和await()类似,只不过等待一定的时间后count值还没变为0的话就会继续执行
public boolean await(long timeout, TimeUnit unit) throws InterruptedException { };
//将count值减1
public void countDown() { };
示例
1 | public class CountDownLatchTest { |
CountDownLatch和CyclicBarrier区别:
- countDownLatch是一个计数器,线程完成一个记录一个,计数器递减,只能只用一次
- CyclicBarrier的计数器更像一个阀门,需要所有线程都到达,然后继续执行,计数器递增,提供reset功能,可以多次使用
AQS
- AQS的全称:AbstractQueuedSynchronizer,抽象队列同步器
- java并发包下很多API都是基于AQS来实现的加锁和释放锁等功能的,AQS是java并发包的基础类。ReentrantLock、ReentrantReadWriteLock底层都是基于AQS来实现的。
- 看一下ReentrantLock和AQS之间的关系
ReentrantLock内部包含了一个AQS对象,也就是AbstractQueuedSynchronizer类型的对象。这个AQS对象就是ReentrantLock可以实现加锁和释放锁的关键性的核心组件。
ReentrantLock加锁和释放锁的底层原理
- 如果有一个线程过来尝试用ReentrantLock的lock()方法进行加锁,这个AQS对象内部有一个核心的变量叫做state,是int类型的,代表了加锁的状态。初始状态下,这个state的值是0。
- 另外,这个AQS内部还有一个关键变量,用来记录当前加锁的是哪个线程,初始化状态下,这个变量是null。
接着线程1跑过来调用ReentrantLock的lock()方法尝试进行加锁,这个加锁的过程,直接就是用CAS操作将state值从0变为1。如果之前没人加过锁,那么state的值肯定是0,此时线程1就可以加锁成功。一旦线程1加锁成功了之后,就可以设置当前加锁线程是自己。所以大家看下面的图,就是线程1跑过来加锁的一个过程。

看到这儿,大家应该对所谓的AQS有感觉了。说白了,就是并发包里的一个核心组件,里面有state变量、加锁线程变量等核心的东西,维护了加锁状态。ReentrantLock这种东西只是一个外层的API,内核中的锁机制实现都是依赖AQS组件的。这个ReentrantLock之所以用Reentrant打头,意思就是他是一个可重入锁。可重入锁的意思,就是你可以对一个ReentrantLock对象多次执行lock()加锁和unlock()释放锁,也就是可以对一个锁加多次,叫做可重入加锁。
- 大家看明白了那个state变量之后,就知道了如何进行可重入加锁!
其实每次线程1可重入加锁一次,会判断一下当前加锁线程就是自己,那么他自己就可以可重入多次加锁,每次加锁就是把state的值给累加1,别的没啥变化。 - 接着,如果线程1加锁了之后,线程2跑过来加锁会怎么样呢?
我们来看看锁的互斥是如何实现的?线程2跑过来一下看到,哎呀!state的值不是0啊?所以CAS操作将state从0变为1的过程会失败,因为state的值当前为1,说明已经有人加锁了! - 接着线程2会看一下,是不是自己之前加的锁啊?当然不是了,“加锁线程”这个变量明确记录了是线程1占用了这个锁,所以线程2此时就是加锁失败。

- 接着,线程2会将自己放入AQS中的一个等待队列,因为自己尝试加锁失败了,此时就要将自己放入队列中来等待,等待线程1释放锁之后,自己就可以重新尝试加锁了

接着,线程1在执行完自己的业务逻辑代码之后,就会释放锁!他释放锁的过程非常的简单,就是将AQS内的state变量的值递减1,如果state值为0,则彻底释放锁,会将“加锁线程”变量也设置为null!
整个过程,参见下图:
接下来,线程1会从等待队列的队头唤醒线程2重新尝试加锁。
线程2现在就重新尝试加锁,这时还是用CAS操作将state从0变为1,- - 此时就会成功,成功之后代表加锁成功,就会将state设置为1;此外,还要把“加锁线程”设置为线程2自己,同时线程2自己就从等待队列中出队了。

总结
其实一句话总结AQS就是一个并发包的基础组件,用来实现各种锁,各种同步组件的。它包含了state变量、加锁线程、等待队列等并发中的核心组件。
写生产者消费者问题,考虑高并发的情况,可以使用Java 类库,白纸写代码。
1 | class Info{ // 定义信息类 |
有没有排查过线上OOM的问题,如何排查的?
查看当前路径,oom.out文件已经生成了,该文件就是应用在发生OOM异常时自动导出的堆文件。那我们此时需要对该文件进行分析,因为其中记录了是什么对象导出了应用程OOM的发生。
分析OOM的工具推荐使用MAT,下载地址,在配置好Java环境的电脑中,直接打开即可,不需要安装,然后通过MAT打开已经生成的OOM文件oom.out,出现如下提示,选择“Leak Suspects Report”执行内存泄漏检查分析:
点击Finish按钮后,MAT会将可疑的内存泄漏的对象都展现出来:

可以看到线程java.lang.Thread @ 0xff617e80 的main方法中,有一个本地变量占用了96.43%的堆内存,实际内存占用的是char[]数组,因而被检测出来为OOM可疑的元凶。点击红色框中的“See stacktrace”,可以直接看到该对象所在线程的堆栈信息:

直接定位到了发生OOM的代码所在位置,至此该示例分析完成,MAT工具本身还有其它许多的功能,这里就不一一细说了。
下一篇会写服务器由于时间戳不一致,导致有些服务器可以访问,有些服务器却不能够访问的问题,如果感兴趣,请继续观注。
有没有使用过JVM自带的工具,如何使用的?
%JAVA_HOME/bin%下就是安装java时为我们自带的可运行程序的文件夹。
jps命令
jps(java process status):用于查看java进程。
| option | description |
|---|---|
| - | 查看java进程 |
| -l | 显示全类名 |
| -m | 带参显示 |
| -v | JVM参数 |
jstat
jstat -gcutil pid

其中的pid是你关注的java进程号,可根据jps查询。-gcutil是关心的指标,更多详尽信息请参看官方文档。
options
description(后面也有详尽的字段说明)
jstat -option pid peroid times(周期监控)
jinfo
jinfo进行指定参数的查询。
jmap
jmap用于内存管理。
jmap -histo pid(类数量 / 实例数量)jmap -dump:format=b,file=file导出运行信息以便于后续线下分析。
jhat(JVM Heap Analysis Tool)
jhat a.bin分析导出数据
jstack
| options | description |
|---|---|
| - | 打印方法栈 |
| -F | 强制打印 |
| -m | 本地方法栈 |
| -l | 打印锁信息 |
jstack pidjstack -l pid(锁信息,能看见线程状态)
jconsole


假设有下图所示的一个Full GC 的图,纵向是内存使用情况,横向是时间,你如何排查这个Full GC 的问题,怎么去解决你说出来的这些问题?

Full GC的原因
我们知道Full GC的触发条件大致情况有以下几种情况:
- 程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行
- 执行了jmap -histo:live pid命令 //这个会立即触发fullgc
在执行minor gc的时候进行的一系列检查
1
2
3
4
5执行Minor GC的时候,JVM会检查老年代中最大连续可用空间是否大于了当前新生代所有对象的总大小。
如果大于,则直接执行Minor GC(这个时候执行是没有风险的)。
如果小于了,JVM会检查是否开启了空间分配担保机制,如果没有开启则直接改为执行Full GC。
如果开启了,则JVM会检查老年代中最大连续可用空间是否大于了历次晋升到老年代中的平均大小,如果小于则执行改为执行Full GC。
如果大于则会执行Minor GC,如果Minor GC执行失败则会执行Full GC使用了大对象 //大对象会直接进入老年代
- 在程序中长期持有了对象的引用 //对象年龄达到指定阈值也会进入老年代
对于我们的情况,可以初步排除1,2两种情况,最有可能是4和5这两种情况。为了进一步排查原因,我们在线上开启了 -XX:+HeapDumpBeforeFullGC。
1 | 注意: |
JVM参数的设置:
线上这个dubbo服务是分布式部署,在其中一台机子上开启了 -XX:HeapDumpBeforeFullGC,总体JVM参数如下:1
2
3
4
5
6
7
8
9
10
11-Xmx2g
-XX:+HeapDumpBeforeFullGC
-XX:HeapDumpPath=.
-Xloggc:gc.log
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+UseGCLogFileRotation
-XX:NumberOfGCLogFiles=10
-XX:GCLogFileSize=100m
-XX:HeapDumpOnOutOfMemoryError
Dump文件分析
dump下来的文件大约1.8g,用jvisualvm查看,发现用char[]类型的数据占用了41%内存,同时另外一个com.alibaba.druid.stat.JdbcSqlStat类型的数据占用了35%的内存,也就是说整个堆中几乎全是这两类数据。如下图:

查看char[]类型数据,发现几乎全是sql语句。
接下来查看char[]的引用情况:
找到了JdbcSqlStat类,在代码中查看这个类的代码,关键代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//构造函数只有这一个
public JdbcSqlStat(String sql){
this.sql = sql;
this.id = DruidDriver.createSqlStatId();
}
//查看这个函数的调用情况,找到com.alibaba.druid.stat.JdbcDataSourceStat#createSqlStat方法:
public JdbcSqlStat createSqlStat(String sql) {
lock.writeLock().lock();
try {
JdbcSqlStat sqlStat = sqlStatMap.get(sql);
if (sqlStat == null) {
sqlStat = new JdbcSqlStat(sql);
sqlStat.setDbType(this.dbType);
sqlStat.setName(this.name);
sqlStatMap.put(sql, sqlStat);
}
return sqlStat;
} finally {
lock.writeLock().unlock();
}
}
//这里用了一个map来存放所有的sql语句。
其实到这里也就知道什么原因造成了这个问题,因为我们使用的数据源是阿里巴巴的druid,这个druid提供了一个sql语句监控功能,同时我们也开启了这个功能。只需要在配置文件中把这个功能关掉应该就能消除这个问题,事实也的确如此,关掉这个功能后到目前为止线上没再触发FullGC
其他
如果用mat工具查看,建议把 “Keep unreachable objects” 勾上,否则mat会把堆中不可达的对象去除掉,这样我们的分析也许会变得没有意义。如下图:Window–>References 。另外jvisualvm对ool的支持不是很好,如果需要oql建议使用mat。

说说对Java中集合类的理解,项目中用过哪些,哪个地方用的,如何使用的?
从数据结构开始了解
数据结构
线性表

- 顺序存储结构(也叫顺序表):一个线性表是n个具有相同特性的数据元素的有限序列。数据元素是一个抽象的符号,其具体含义在不同的情况下一般不同。
- 链表:链表里面节点的地址不是连续的,是通过指针连起来的。
哈希表
解释一:
哈希表hashtable(key,value) 就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
解释二:
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是我们要提起的哈希表,哈希表有多种不同的实现方法,我接下来解释的是最常用的一种方法——拉链法,我们可以理解为“链表的数组”,如图:

左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
Hash 表的查询速度非常的快,几乎是O(1)的时间复杂度。
hash就是找到一种数据内容和数据存放地址之间的映射关系。
散列法:元素特征转变为数组下标的方法。
我想大家都在想一个很严重的问题:“如果两个字符串在哈希表中对应的位置相同怎么办?”,毕竟一个数组容量是有限的,这种可能性很大。解决该问题的方法很多,我首先想到的就是用“链表”。我遇到的很多算法都可以转化成链表来解决,只要在哈希表的每个入口挂一个链表,保存所有对应的字符串就OK了。
散列表的查找步骤
当存储记录时,通过散列函数计算出记录的散列地址
当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
优缺点
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
如果不需要有序遍历数据,并且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
哈希表的原理:
1,对对象元素中的关键字(对象中的特有数据),进行哈希算法的运算,并得出一个具体的算法值,这个值 称为哈希值。
2,哈希值就是这个元素的位置。
3,如果哈希值出现冲突,再次判断这个关键字对应的对象是否相同。如果对象相同,就不存储,因为元素重复。如果对象不同,就存储,在原来对象的哈希值基础 +1顺延。
4,存储哈希值的结构,我们称为哈希表。
5,既然哈希表是根据哈希值存储的,为了提高效率,最好保证对象的关键字是唯一的。
这样可以尽量少的判断关键字对应的对象是否相同,提高了哈希表的操作效率。
扩展:
相同的字符串如果存进去,哈希值相同并且equals方法为true,不会存入相同的
只要哈希值相同或者equals方法为true都成立才不会存入,只要其中一条不满足,都会储存
哈希表存储过程:
1.调用对象的哈希值(通过一个函数f()得到哈希值):存储位置 = f(关键字)
2.集合在容器内搜索有没有重复的哈希值,如果没有,存入新元素,记录哈希值
3.再次存储,重复上边的过程
4.如果有重复的哈希值,调用后来者的equals方法,参数为前来者,结果得到true,集合判断为重复元素,不存入
哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。前面我们提到过,哈希函数的设计至关重要,好的哈希函数会尽可能地保证 计算简单和散列地址分布均匀,但是,我们需要清楚的是,数组是一块连续的固定长度的内存空间,再好的哈希函数也不能保证得到的存储地址绝对不发生冲突。那么哈希冲突如何解决呢?
哈希冲突的解决方案有多种:
开放定址法(发生冲突,继续寻找下一块未被占用的存储地址)
再散列函数法
链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式
关于hashcode和equals的一些问题,在面试中会问道:
1.两个对象哈希值相同,那么equals方法一定返回true吗?
不一定:取决于如何重写equals,如果重写固定了它返回false,结果就一定是false
2.equals方法返回true,那么哈希值一定相同吗?
一定:如果类中定义一个静态变量(static int a = 1),然后重写hashcode返回a+1,那么每一个对象的哈希值都不一样,不过java中规定:对象相等,必须具有相同的哈希码值,所以这里是一定的
数组
采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
区别
1.数组
优点:(1)随机访问效率高(根据下标查询),(2)搜索效率较高(可使用折半方法)。
缺点:(1)内存连续且固定,存储效率低。(2)插入和删除效率低(可能会进行数组拷贝或扩容)。
2.链表
优点:(1)不要求连续内存,内存利用率高,(2)插入和删除效率高(只需要改变指针指向)。
缺点:(1)不支持随机访问,(2)搜索效率低(需要遍历)。
3.Hash表
优点:(1)搜索效率高,(2)插入和删除效率较高,
缺点:(1)内存利用率低(基于数组),(2)存在散列冲突。
集合类种重要概念词解释
泛型
java中很重要的概念, 集合里面应用很多.
集合的元素,可以是任意类型对象的引用,如果把某个对象放入集合,则会忽略它的类型,就会把它当做Object类型处理.
泛型则是规定了某个集合只可以存放特定类型的对象的引用,会在编译期间进行类型检查,可以直接指定类型来获取集合元素
在泛型集合中有能够存入泛型类型的对象实例还可以存入泛型的子类型的对象实例
注意:
1 泛型集合中的限定类型,不能使用基本数据类型
2 可以通过使用包装类限定允许存放基本数据类型
泛型的好处
1 提高了安全性(将运行期的错误转换到编译期)
2 省去强转的麻烦
哈希值
1 就是一个十进制的整数,有操作系统随机给出
2 可以使用Object类中的方法hashCode获取哈希值
3 Object中源码: int hashCode()返回该对象的哈希码值;
源码:1
2//native:指调用了本地操作系统的方法实现
public native int hashCode();
平衡二叉树(称AVL树)
其特点是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个子节点,其左右子树的高度都相近。
注意:
关键点是左子树和右子树的深度的绝对值不超过1
那什么是左子树深度和右子树深度呢?

如上图中:
如果插入6元素, 则8的左子树深度就为2, 右子树深度就为0,绝对值就为2, 就不是一个平很二叉树
二叉排序树
1若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3左、右子树也分别为二叉排序树
解释一:
现在有a[10] = {3, 2, 1, 4, 5, 6, 7, 10, 9, 8}需要构建二叉排序树。在没有学习平衡二叉树之前,根据二叉排序树的特性,通常会将它构建成如下左图。虽然完全符合二叉排序树的定义,但是对这样高度达到8的二叉树来说,查找是非常不利的。因此,更加期望构建出如下右图的样子,高度为4的二叉排序树,这样才可以提供高效的查找效率。
平衡二叉树是一种二叉排序树,是一种高度平衡的二叉树,其中每个结点的左子树和右子树的高度至多等于1.意味着:要么是一棵空树,要么左右都是平衡二叉树,且左子树和右子树深度之绝对值不超过1. 将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF,那么平衡二叉树上的所有结点的平衡因子只可能是-1、0和1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
平衡二叉树的前提是它是一棵二叉排序树。
旋转
假设一颗 AVL 树的某个节点为 r,有四种操作会使 r 的左右子树高度差大于 1,从而破坏了原有 AVL 树的平衡性。使用旋转达到平衡性
1.对 r 的左儿子的左子树进行一次插入(左旋转 LL)
2.对 r 的左儿子的右子树进行一次插入(LR)
3.对 r 的右儿子的左子树进行一次插入(RL)
4.对 r 的右儿子的右子树进行一次插入(RR)
红黑树
红黑树(Red Black Tree) 是一种自平衡二叉查找树
(1) 检索效率O(log n)
(2) 红黑树的五点规定:
1.每个结点要么是红的要么是黑的
2.根结点是黑的
3.每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的
4.如果一个结点是红的,那么它的两个儿子都是黑的(反之不一定)
5.对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点
它的每个结点都额外有一个颜色的属性,颜色只有两种:红色和黑色。
示例:(这块难度比较大, 建议自行百度,查阅相关文档)
红黑树插入操作
如果是第一次插入,由于原树为空,所以只会违反红黑树的规则2,所以只要把根节点涂黑即可;
如果插入节点的父节点是黑色的,那不会违背红-黑树的规则,什么也不需要做;
但是遇到如下三种情况时,我们就要开始变色和旋转了:
1. 插入节点的父节点和其叔叔节点(祖父节点的另一个子节点)均为红色的;
2. 插入节点的父节点是红色,叔叔节点是黑色,且插入节点是其父节点的右子节点;
3. 插入节点的父节点是红色,叔叔节点是黑色,且插入节点是其父节点的左子节点。
下面我们先挨个分析这三种情况都需要如何操作:
对于情况1:插入节点的父节点和其叔叔节点(祖父节点的另一个子节点)均为红色的。此时,肯定存在祖父节点,但是不知道父节点是其左子节点还是右子节点,但是由于对称性,我们只要讨论出一边的情况,另一种情况自然也与之对应。
这里考虑父节点是祖父节点的左子节点的情况(即插入一个4节点,插入的节点一般为红色,不然可能违反规则5.),如下左图所示:

对于这种情况,我们要做的操作有:将当前节点(4)的父节点(5)和叔叔节点(8)涂黑,将祖父节点(7)涂红,变成上右图所示的情况。再将当前节点指向其祖父节点,再次从新的当前节点开始算法。这样上右图就变成了情况2了。
对于情况2:插入节点的父节点是红色,叔叔节点是黑色,且插入节点是其父节点的右子节点。我们要做的操作有:将当前节点(7)的父节点(2)作为新的节点,以新的当前节点为支点做左旋操作。完成后如左下图所示,这样左下图就变成情况3了。


对于情况3:插入节点的父节点是红色,叔叔节点是黑色,且插入节点是其父节点的左子节点。我们要做的操作有:将当前节点的父节点(7)涂黑,将祖父节点(11)涂红,在祖父节点为支点做右旋操作。最后把根节点涂黑,整个红-黑树重新恢复了平衡,如右上图所示。至此,插入操作完成!
我们可以看出,如果是从情况1开始发生的,必然会走完情况2和3,也就是说这是一整个流程,当然咯,实际中可能不一定会从情况1发生,如果从情况2开始发生,那再走个情况3即可完成调整,如果直接只要调整情况3,那么前两种情况均不需要调整了。故变色和旋转之间的先后关系可以表示为:变色->左旋->右旋。
红黑树删除操作
我们现在约定:后继节点的子节点称为“当前节点”.
删除节点有三种情况分析:
a. 叶子节点;(直接删除即可)
b. 仅有左或右子树的节点;(上移子树即可)
c. 左右子树都有的节点。( 用删除节点的直接前驱或者直接后继来替换当前节点,调整直接前驱或者直接后继的位置)
删除操作后,如果当前节点是黑色的根节点,那么不用任何操作,因为并没有破坏树的平衡性,即没有违背红-黑树的规则,这很好理解。如果当前节点是红色的,说明刚刚移走的后继节点是黑色的,那么不管后继节点的父节点是啥颜色,我们只要将当前节点涂黑就可以了,红-黑树的平衡性就可以恢复。但是如果遇到以下四种情况,我们就需要通过变色或旋转来恢复红-黑树的平衡了。
当前节点是黑色的,且兄弟节点是红色的(那么父节点和兄弟节点的子节点肯定是黑色的);
当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的两个子节点均为黑色的;
当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的左子节点是红色,右子节点时黑色的;
当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的右子节点是红色,左子节点任意颜色。
以上四种情况中,我们可以看出2,3,4其实是“当前节点是黑色的,且兄弟节点是黑色的”的三种子集,等会在程序中可以体现出来。现在我们假设当前节点是左子节点(当然也可能是右子节点,跟左子节点相反即可,我们讨论一边就可以了),分别解决上面四种情况:
对于情况1:当前节点是黑色的,且兄弟节点是红色的(那么父节点和兄弟节点的子节点肯定是黑色的)。如左下图所示:A节点表示当前节点。针对这种情况,我们要做的操作有:将父节点(B)涂红,将兄弟节点(D)涂黑,然后将当前节点(A)的父节点(B)作为支点左旋,然后当前节点的兄弟节点就变成黑色的情况了(自然就转换成情况2,3,4的公有特征了),如右下图所示:

对于情况2:当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的两个子节点均为黑色的。如左下图所示,A表示当前节点。针对这种情况,我们要做的操作有:将兄弟节点(D)涂红,将当前节点指向其父节点(B),将其父节点指向当前节点的祖父节点,继续新的算法(具体见下面的程序),不需要旋转。这样变成了右下图所示的情况:

对于情况3:当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的左子节点是红色,右子节点时黑色的。如左下图所示,A是当前节点。针对这种情况,我们要做的操作有:把当前节点的兄弟节点(D)涂红,把兄弟节点的左子节点(C)涂黑,然后以兄弟节点作为支点做右旋操作。然后兄弟节点就变成黑色的,且兄弟节点的右子节点变成红色的情况(情况4)了。如右下图:

对于情况4:当前节点是黑色的,且兄弟节点是黑色的,且兄弟节点的右子节点是红色,左子节点任意颜色。如左下图所示:A为当前节点,针对这种情况,我们要做的操作有:把兄弟节点(D)涂成父节点的颜色,再把父节点(B)涂黑,把兄弟节点的右子节点(E)涂黑,然后以当前节点的父节点为支点做左旋操作。至此,删除修复算法就结束了,最后将根节点涂黑即可。

我们可以看出,如果是从情况1开始发生的,可能情况2,3,4中的一种:如果是情况2,就不可能再出现3和4;如果是情况3,必然会导致情况4的出现;如果2和3都不是,那必然是4。当然咯,实际中可能不一定会从情况1发生,这要看具体情况了。
迭代器
迭代器模式
把访问逻辑从不同类型的集合类中抽取出来,从而避免向外部暴露集合的内部结构。在java中它是一个对象,其目的是遍历并选中其中的每个元素,而使用者(客户端)无需知道里面的具体细节。
Iterator
Collection集合元素的通用获取方式:在取出元素之前先判断集合中有没有元素。如果有,就把这个元素取出来,继续再判断,如果还有就再取出来,一直把集合中的所有元素全部取出来,这种取出元素的方式专业术语称为迭代。
java.util.Iterator:在Java中Iterator为一个接口,它只提供了迭代的基本规则。在JDK中它是这样定义的:对Collection进行迭代的迭代器。迭代器取代了Java Collection Framework中的Enumeration。
Collection中有一个抽象方法iterator方法,所有的Collection子类都实现了这个方法;返回一个Iterator对象
定义:
1 | package java.util; |
在使用Iterator的时候禁止对所遍历的容器进行改变其大小结构的操作。例如: 在使用Iterator进行迭代时,如果对集合进行了add、remove操作就会出现ConcurrentModificationException异常。
在进行集合元素取出的时候,如果集合中没有元素了,还继续使用next()方法的话,将发生NoSuchElementException没有集合元素的错误
修改并发异常:在迭代集合中元素的过程中,集合的长度发生改变(进行了元素增加或者元素删除的操作), 增强for的底层原理也是迭代器,所以也需要避免这种操作;
解决以上异常的方法:使用ListIterator
任何集合都有迭代器。
任何集合类,都必须能以某种方式存取元素,否则这个集合容器就没有任何意义。
迭代器,也是一种模式(也叫迭代器模式)。迭代器要足够的“轻量”——创建迭代器的代价小。
Iterable(1.5)
Java中还提供了一个Iterable接口,Iterable接口实现后的功能是‘返回’一个迭代器,我们常用的实现了该接口的子接口有:Collection<E>、List<E>、Set<E>等。该接口的iterator()方法返回一个标准的Iterator实现。实现Iterable接口允许对象成为Foreach语句的目标。就可以通过foreach语句来遍历你的底层序列。
Iterable接口包含一个能产生Iterator对象的方法,并且Iterable被foreach用来在序列中移动。因此如果创建了实现Iterable接口的类,都可以将它用于foreach中。
定义:
1 | Package java.lang; |
Iterable是Java 1.5的新特性, 主要是为了支持forEach语法, 使用容器的时候, 如果不关心容器的类型, 那么就需要使用迭代器来编写代码. 使代码能够重用.
使用方法很简单:
1 | List<String> strs = Arrays.asList("a", "b", "c"); |
- 好处:代码减少,方便遍历
- 弊端:没有索引,不能操作容器里的元素
增强for循环底层也是使用了迭代器获取的,只不过获取迭代器由jvm完成,不需要我们获取迭代器而已,所以在使用增强for循环变量元素的过程中不准使用集合对象对集合的元素个数进行修改;
forEach()(1.8)
使用接收lambda表达式的forEach方法进行快速遍历.
1 | List<String> strs = Arrays.asList("a", "b", "c"); |
Spliterator迭代器
Spliterator是1.8新增的迭代器,属于并行迭代器,可以将迭代任务分割交由多个线程来进行。
Spliterator可以理解为Iterator的Split版本(但用途要丰富很多)。使用Iterator的时候,我们可以顺序地遍历容器中的元素,使用Spliterator的时候,我们可以将元素分割成多份,分别交于不于的线程去遍历,以提高效率。使用 Spliterator 每次可以处理某个元素集合中的一个元素 — 不是从 Spliterator 中获取元素,而是使用 tryAdvance() 或 forEachRemaining() 方法对元素应用操作。但Spliterator 还可以用于估计其中保存的元素数量,而且还可以像细胞分裂一样变为一分为二。这些新增加的能力让流并行处理代码可以很方便地将工作分布到多个可用线程上完成
ListIterator
ListIterator是一个更强大的Iterator子类型,能用于各种List类访问,前面说过Iterator支持单向取数据,ListIterator可以双向移动,所以能指出迭代器当前位置的前一个和后一个索引,可以用set方法替换它访问过的最后一个元素。我们可以通过调用listIterator方法产生一个指向List开始处的ListIterator,并且还可以用过重载方法listIterator(n)来创建一个指定列表索引为n的元素的ListIterator。
ListIterator可以往前遍历,添加元素,设置元素
Iterator和ListIterator的区别:
两者都有next()和hasNext(),可以实现向后遍历,但是ListIterator有previous()和hasPrevious()方法,即可以实现向前遍历
ListIterator可以定位当前位置,nextIndex()和previous()可以实现
ListIterator有add()方法,可以向list集合中添加数据
都可以实现删除操作,但是ListIterator可以实现对对象的修改,set()可以实现,Iterator仅能遍历,不能修改
Fail-Fast
类中的iterator()方法和listIterator()方法返回的iterators迭代器是fail-fast的:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
迭代器与枚举有两点不同:
1. 迭代器在迭代期间可以从集合中移除元素。
2. 方法名得到了改进,Enumeration的方法名称都比较长。
迭代器的好处:屏蔽了集合之间的不同,可以使用相同的方式取出
集合类概念
集合类的作用
集合类也叫做容器类,和数组一样,用于存储数据,但数组类型单一,并且长度固定,限制性很大,而集合类可以动态增加长度。
集合存储的元素都是对象(引用地址),所以集合可以存储不同的数据类型,但如果是需要比较元素来排序的集合,则需要类型一致。
集合中提供了统一的增删改查方法,使用方便。
支持泛型,避免数据不一致和转换异常,还对常用的数据结构进行了封装。
所有的集合类的都在java.util包下。
集合框架体系的组成
集合框架体系是由Collection、Map(映射关系)和Iterator(迭代器)组成,各部分的作用如下所示。
Collection体系中有三种集合:Set、List、Queue
Set(集): 元素是无序的且不可重复。
List(列表):元素是有序的且可重复。
Queue(队列):封装了数据结构中的队列。
Map体系
Map用于保存具有映射关系的数据,即key-value(键值对)。Map集合的key是唯一的,不可重复,而value可以重复。所以一个value可以对应多个key。
Map体系除了常用类之外,还有Properties(属性类)也属于Map体系。
Iterator(迭代器)
请查看上面!
Collection的由来
由于数组中存放对象,对对象操作起来不方便。java中有一类容器,专门用来存储对象。
集合可以存储多个元素,但我们对多个元素也有不同的需求
多个元素,不能有相同的
多个元素,能够按照某个规则排序
针对不同的需求:java就提供了很多集合类,多个集合类的数据结构不同。但是,结构不重要,重要 的是能够存储东西,能够判断,获取.
把集合共性的内容不断往上提取,最终形成集合的继承体系—->Collection
并且所有的Collection实现类都重写了toString()方法.
集合和数组
集合与数组的区别:
- 数组的长度固定的,而集合长度时可变的
数组只能储存同一类型的元素,而且能存基本数据类型和引用数据类型。集合可以存储不同类型的元素,只能存储引用数据类型
集合类和数组不一样,数组元素既可以是基本类型的值,也可以是对象(实际上保存的是对象的引用变量);而集合只能保存对象。
数组和集合的主要区别包括以下几个方面:
- 数组声明了它容纳的元素的类型,而集合不声明。这是由于集合以object形式来存储它们的元素。
- 一个数组实例具有固定的大小,不能伸缩。集合则可根据需要动态改变大小。
- 数组是一种可读/可写数据结构没有办法创建一个只读数组。然而可以使用集合提供的ReadOnly方 只读方式来使用集合。该方法将返回一个集合的只读版本。
集合的作用:
如果一个类的内部有很多相同类型的属性,并且他们的作用与意义是一样的,比如说学生能选课学生类就有很多课程类型的属性,或者工厂类有很多机器类型的属性,我们用一个类似于容器的集合去盛装他们,这样在类的内部就变的井然有序———这就是:
- 在类的内部,对数据进行组织的作用。
- 简单而快速的搜索查找其中的某一条元素
- 有的集合接口,提供了一系列排列有序的元素,并且可以在序列中间快速的插入或者删除有关元素。
- 有的集合接口在其内部提供了映射关系的结构,可以通过关键字(key)去快速查找对应的唯一对象,而这个关键可以是任意类型的。
泛型与集合的区别
泛型听起来很高深的一个词,但实际上它的作用很简单,就是提高java程序的性能。
比如在计算机中经常用到一些数据结构,如队列,链表等,而其中的元素以前一般这么定义:object a=new object();
这样就带来一个严重的问题,用object来表示元素没有逻辑问题,但每次拆箱、封箱就占用了大量的计算机资源,导致程序性能低下,而这部分内容恰恰一般都是程序的核心部分,如果使用object,那么程序的表现就比较糟糕。
而使用泛型则很好的解决这个问题,本质就是在编译阶段就告诉编译器,数据结构中元素的种类,既然编译器知道了元素的种类,自然就避免了拆箱、封箱的操作,从而显著提高java程序的性能。
比如List<string>就直接使用string对象作为List的元素,而避免使用object对象带来的封箱、拆箱操作,从而提高程序性能。
集合接口与类
数组和集合一般就用到下面接口和集合
Array 数组
Arrays 数组工具
Collection 最基本的集合接口
Collections 集合工具类
List 接口
ArrayList 一种可以动态增长和缩减的索引序列
LinkedList 一种可以在任何位置进行高效地插入和删除操作的有序序列
Vector
Set
HashSet 一种没有重复元素的无序集合
TreeSet 一种有序集
LinkHashSet 一种可以记住元素插入次序的集合
map
HashMap 一种存储key:value关联的映射
HashTable
TreeMap 一种key有序的映射
LinkedHashMap 一种可以记住插入次序的映射
Deque
Stack
ArrayDeque 一种用循环数组实现的双端队列
Queue
PriorityQueue 一种可以高效删除最小元素的集合
Array
数组:是以一段连续内存保存数据的;随机访问是最快的,但不支持插入,删除,迭代等操作。
Array可以包含基本类型和对象类型
Array大小是固定的
指定数组引用为 null,则此类中的方法都会抛出 NullPointerException。
所创建的对象都放在堆中。
够对自身进行枚举(因为都实现了IEnumerable接口)。
具有索引(index),即可以通过index来直接获取和修改任意项。
Array类型的变量在声明的同时必须进行实例化(至少得初始化数组的大小),而ArrayList可以只是先声明。
Array只能存储同构的对象,而ArrayList可以存储异构的对象。
在CLR托管对中的存放方式
Array是始终是连续存放的,而ArrayList的存放不一定连续。
Array不能够随意添加和删除其中的项,而ArrayList可以在任意位置插入和删除项。
采用数组存在的一些缺陷:
1.数组长度固定不变,不能很好地适应元素数量动态变化的情况。
2.可通过数组名.length获取数组的长度,却无法直接获取数组中真实存储的个数。
3.在进行频繁插入、删除操作时同样效率低下。
Arrays
数组的工具类,里面都是操作数组的工具.
常用方法:
1、数组的排序:Arrays.sort(a);//实现了对数组从小到大的排序//注:此类中只有升序排序,而无降序排序。
2、数组元素的定位查找:Arrays.binarySearch(a,8);//二分查找法
3、数组的打印:Arrays.toString(a);//String 前的a和括号中的a均表示数组名称
4、 查看数组中是否有特定的值:Arrays.asList(a).contains(1);
Collection
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些 Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类, Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的 Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
1 | Iterator it = collection.iterator(); // 获得一个迭代子 |
由Collection接口派生的两个接口是List和Set。
Collection返回的是Iterator迭代器接口,而List中又有它自己对应的实现–>ListIterator接口 Collection。标识所含元素的序列,这里面又包含多种集合类,比如List,Set,Queue;它们都有各自的特点,比如List是按顺序插入元素,Set是不重复元素集合,Queue则是典型的FIFO结构
Collection接口描述:
Collection接口常用的子接口有List 接口和Set接口
List接口中常用的子类有:ArrayList类(数组列表)和LinkedList(链表)
Set接口中常用的子类有:HashSet (哈希表)和LinkedHashSet(基于链表的哈希表)
Collection 层次结构 中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set和 List)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。(面向接口的编程思想)
Collections
排序操作
Collections提供以下方法对List进行排序操作
void reverse(List list):反转
void shuffle(List list),随机排序
void sort(List list),按自然排序的升序排序
void sort(List list, Comparator c);定制排序,由Comparator控制排序逻辑
void swap(List list, int i , int j),交换两个索引位置的元素
void rotate(List list, int distance),旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
查找,替换操作
int binarySearch(List list, Object key), 对List进行二分查找,返回索引,注意List必须是有序的
int max(Collection coll),根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
int max(Collection coll, Comparator c),根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
void fill(List list, Object obj),用元素obj填充list中所有元素
int frequency(Collection c, Object o),统计元素出现次数
int indexOfSubList(List list, List target), 统计targe在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素。
同步控制
Collections中几乎对每个集合都定义了同步控制方法, 这些方法,来将集合包装成线程安全的集合
SynchronizedList(List);
SynchronizedSet(Set;
SynchronizedMap(Map);
SynchronizedMap和ConcurrentHashMap 区别
Collections.synchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步,而ConcurrentHashMap的实现却更加精细,它对map中的所有桶加了锁。所以,只要要有一个线程访问map,其他线程就无法进入map,而如果一个线程在访问ConcurrentHashMap某个桶时,其他线程,仍然可以对map执行某些操作。这样,ConcurrentHashMap在性能以及安全性方面,明显比Collections.synchronizedMap()更加有优势。同时,同步操作精确控制到桶,所以,即使在遍历map时,其他线程试图对map进行数据修改,也不会抛出ConcurrentModificationException。
ConcurrentHashMap从类的命名就能看出,它必然是个HashMap。而Collections.synchronizedMap()可以接收任意Map实例,实现Map的同步
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
List
List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引。元素可以重复。
List本身是Collection接口的子接口,具备了Collection的所有方法。
List的特有方法都有索引,这是该集合最大的特点。
List集合支持对元素的增、删、改、查。
List中存储的元素实现类排序,而且可以重复的存储相关元素。
次序是List最重要的特点:它保证维护元素特定的顺序。
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
和下面要提到的Set不同,List允许有相同的元素。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个 ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
优点:操作读取操作效率高,基于数组实现的,可以为null值,可以允许重复元素,有序,异步。
缺点:由于它是由动态数组实现的,不适合频繁的对元素的插入和删除操作,因为每次插入和删除都需要移动数组中的元素。
ArrayList
ArrayList 是基于数组实现,内存中分配连续的空间,需要维护容量大小。随机访问.
ArrayList就是动态数组,也是一个对象。
ArrayList不自定义位置添加元素和LinkedList性能没啥区别,ArrayList默认元素追加到数组后面,而LinkedList只需要移动指针,所以两者性能相差无几。
如果ArrayList自定义位置插入元素,越靠前,需要重写排序的元素越多,性能消耗越大,LinkedList无论插入任何位置都一样,只需要创建一个新的表项节点和移动一下指针,性能消耗很低。
ArrayList是基于数组,所以查看任意位置元素只需要获取当前位置的下标的数组就可以,效率很高,然而LinkedList获取元素需要从最前面或者最后面遍历到当前位置元素获取,如果集合中元素很多,就会效率很低,性能消耗大。
频繁遍历查看元素,使用 ArrayList 集合,ArrayList 查询快,增删慢
ArrayList线程不安全的
1、ArrayList是用数组实现的,该对象存放在堆内存中,这个数组的内存是连续的,不存在相邻元素之间还隔着其他内存。底层是一个可动态扩容的数组
2、索引ArrayList时,速度比原生数组慢是因为你要用get方法,这是一个函数调用,而数组直接用[ ]访问,相当于直接操作内存地址,速度当然比函数调用快。
3、新建ArrayList的时候,JVM为其分配一个默认或指定大小的连续内存区域(封装为数组)。
4、每次增加元素会检查容量,不足则创建新的连续内存区域(大小等于初始大小+步长),也用数组形式封装,并将原来的内存区域数据复制到新的内存区域,然后再用ArrayList中引用原来封装的数组对象的引用变量引用到新的数组对象:
1 | elementData = Arrays.copyOf(elementData, newCapacity); |
ArrayList里面的removeIf方法就接受一个Predicate参数,采用如下Lambda表达式就能把,所有null元素删除:
1 | list.removeIf(e -> e == null); |
ArrayList:每次添加元素之前会检查是否需要扩容,是按照原数组的1.5倍延长。构造一个初始容量为 10 的空列表。
使用for适合循环ArrayLIst以及数组,当大批量的循环LinkedList时程序将会卡死,for适合循环数组结构,通过下标去遍历。
get访问List内部任意元素时,ArrayList的性能要比LinkedList性能好。LinkedList中的get方法是要按照顺序从列表的一端开始检查,直到另一端。
在ArrayList的 中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;
ArrayList的空 间浪费主要体现在在list列表的结尾预留一定的容量空间
ArrayList只能包含对象类型。
ArrayList的大小是动态变化的。
对于基本类型数据,集合使用自动装箱来减少编码工作量
够对自身进行枚举(因为实现了IEnumerable接口)。
具有索引(index),即可以通过index来直接获取和修改任意项。
ArrayList允许存放(不止一个)null元素
允许存放重复数据,存储时按照元素的添加顺序存储
ArrayList可以存放任何不同类型的数据(因为它里面存放的都是被装箱了的Object型对象,实际上ArrayList内部就是使用”object[] _items;”这样一个私有字段来封装对象的)
ArrayList不是一个线程安全的集合,如果集合的增删操作需要保证线程的安全性,可以考虑使用CopyOWriteArrayList或者使用collections.synchronizedList(Lise l)函数返回一个线程安全的ArrayList类。
实现了RandomAccess接口,底层又是数组,get读取元素性能很好
顺序添加很方便
删除和插入需要复制数组 性能很差(可以使用LinkindList)
为什么ArrayList的elementData是用transient修饰的?
transient修饰的属性意味着不会被序列化,也就是说在序列化ArrayList的时候,不序列化elementData。
为什么要这么做呢?
elementData不总是满的,每次都序列化,会浪费时间和空间
重写了writeObject 保证序列化的时候虽然不序列化全部 但是有的元素都序列化
所以说不是不序列化 而是不全部序列化。
elementData属性采用了transient来修饰,不使用Java默认的序列化机制来实例化,自己实现了序列化writeObject()和反序列化readObject()的方法。
每次对下标的操作都会进行安全性检查,如果出现数组越界就立即抛出异常。
如果提前知道数组元素较多,可以在添加元素前通过调用ensureCapacity()方法提前增加容量以减小后期容量自动增长的开销。
当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
ArrayList基于数组方式实现,容量限制不大于Integer.MAX_VALUE的小大,每次扩容1.5倍。有序,可以为null,允许重复,非线程安全。
增加和删除会修改modCount,在迭代的时候需要保持单线程的唯一操作,如果期间进行了插入或者删除操作,就会被迭代器检查获知,从而出现运行时异常。
一般建议在单线程中使用ArrayList。
当在index处放置一个元素的时候,会将数组index处右边的元素全部右移
当在index处删除一个元素的时候,会将数组index处右边的元素全部左移
ArrayList底层是数组结构,因为数组有维护索引,所以查询效率高;而做插入、删除操作时,因为要判断扩容(复制一份新数组)且数组中的元素可能要大规模的后移或前移一个索引位置,所以效率差。
Arrays.asList()方法返回的List集合是一个固定长度的List集合,不是ArrayList实例,也不是Vector的实例
ArrayList也采用了快速失败(Fail-Fast机制)的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。具体介绍请参考HashMap的实现原理中的Fail-Fast机制。
linkedList
LinkedList 是基于循环双向链表数据结构,不需要维护容量大小。顺序访问。
频繁插入删除元素 使用 LinkedList 集合
LinkedList 线程不安全的
LinkedList在随机访问方面相对比较慢,但是它的特性集较ArrayList 更大。
LinkedList提供了大量的首尾操作
LinkedList:底层的数据结构是链表,线程不同步,增删元素的速度非常快。
LinkedList:底层基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢
LinkedList由双链表实现,增删由于不需要移动底层数组数据,其底层是链表实现的,只需要修改链表节点指针,对元素的插入和删除效率较高。
LinkedList缺点是遍历效率较低。HashMap和双链表也有关系。
LinkedList是一个继承于AbstractSequentialList的双向链表,它可以被当做堆栈、队列或双端队列进行操作
LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
使用foreach适合循环LinkedList,使用双链表结构实现的应当使用foreach循环。
LinkedList实现了List接口,允许null元素。
LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
1 | List list = Collections.synchronizedList(new LinkedList(…)); |
在LinkedList的中间插入或删除一个元素的开销是固定的。
LinkedList不支持高效的随机元素访问。
LinkedList的空间花费则体现在它的每一个元素都需要消耗相当的空间
LinkedList是List和Deque接口的双向链表的实现。实现了所有可选列表操作,并允许包括null值。
Fail-Fast机制:LinkedList也采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
LinkedList因为底层为链表结构,查询时需要从头节点(或尾节点)开始遍历所以查询效率差;但同时也因为是链表结构,做插入、删除操作时只要断开当前删除节点前驱、后驱引用,并将原来的前、后节点的引用链接起来,所以效率高。
千万不要使用普通for循环遍历LinkedList,这么做会让你崩溃!可以选择使用foreach或迭代器来进行遍历操作
LinedList适合用迭代遍历;
基于链表结构的集合 LinkedList。LinkedList 属于 java.util 包下面,也实现Iterable接口,说明可以使用迭代器遍历;LinkedList 还实现 Deque<E>,Queue<E>操作。Deque 和 Queue 是 LinkedList 的父接口,那么 LinkedList 也可以看成一种 Deque 或者 Queue;Queue表示一种队列,也是一种数据结构,它的特点是先进先出,因此在队列这个接口里面提供了一些操作队列的方法,同时LinkedList也具有这些方法;Deque(Double ended queues双端队列),支持在两端插入或者移除元素; 那也应该具有操作双端队列的一些方法;LinkedList 是他们的子类,说明都具有他们两者的方法;LinkedList也可以充当队列,双端队列,堆栈多个角色。
vector
Vector:底层的数据结构就是数组,线程同步的,Vector无论查询和增删都巨慢。
Vector:是按照原数组的2倍延长。
Vector是基于线程安全的,效率低 元素有放入顺序,元素可重复
Vector可以由我们自己来设置增长的大小,ArrayList没有提供相关的方法。
Vector相对ArrayList查询慢(线程安全的)
Vector相对LinkedList增删慢(数组结构)
以前还能见到Vector和Stack,但Vector太过古老,被ArrayList取代,所以这里不讲;而Stack已经被ArrayDeque取代。
对于想在迭代器迭代过程中针对集合进行增删改的,可以通过返回ListIterator来操作。
Vector:底层结构是数组,线程是安全的,添加删除慢,查找快,(同ArrayList)
ArrayList 和Vector是采用数组方式存储数据,此数组元素数大于实际存储的数据以便增加和插入元素,都允许直接序号索引元素,但是插入数据要涉及到数组元素移动等内存操作,所以索引数据快,插入数据慢,Vector由于使用了synchronized方法(线程安全)所以性能上比ArrayList要差,LinkedList使用双向链表实现存储,按序号索引数据需要进行向前或向后遍历,但是插入数据时只需要记录本项的前后项即可,所以插入数度较快。
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
由Vector创建的Iterator,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
Set
无序(存入和取出顺序有可能不一致),不可以存储重复元素。必须保证元素唯一性。
元素无放入顺序,元素不可重复(注意:元素虽然无放入顺序,但是元素在set中的位置是有该元素的HashCode决定的,其位置其实是固定的)
Set具有与Collection完全一样的接口,因此没有任何额外的功能,只是行为不同。这是继承与多态思想的典型应用:表现不同的行为。
Set不保存重复的元素(至于如何判断元素相同则较为负责)
存入Set的每个元素都必须是唯一的,因为Set不保存重复元素,加入Set的元素必须定义equals()方法以确保对象的唯一性。
Set 是基于对象的值来确定归属性的。
Set本身有去重功能是因为String内部重写了hashCode()和equals()方法,在add里实现了去重, Set集合是不允许重复元素的,但是集合是不知道我们对象的重复的判断依据的,默认情况下判断依据是判断两者是否为同一元素(euqals方法,依据是元素==元素),如果要依据我们自己的判断来判断元素是否重复,需要重写元素的equals方法(元素比较相等时调用)hashCode()的返回值是元素的哈希码,如果两个元素的哈希码相同,那么需要进行equals判断。【所以可以自定义返回值作为哈希码】 equals()返回true代表两元素相同,返回false代表不同。
set集合没有索引,只能用迭代器或增强for循环遍历
set的底层是map集合
Set最多有一个null元素
必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
Set具有与Collection完全一样的接口,没有额外的任何功能。所以把Set就是Collection,只是行为不同(这就是多态);Set是基于对象的值来判断归属的,由于查询速度非常快速,HashSet使用了散列,HashSet维护的顺序与TreeSet或LinkedHashSet都不同,因为它们的数据结构都不同,元素存储方式自然也不同。TreeSet的数据结构是“红-黑树”,HashSet是散列函数,LinkedHashSet也用了散列函数;如果想要对结果进行排序,那么选择TreeSet代替HashSet是个不错的选择
Hashset
HashSet : 为快速查找设计的Set。存入HashSet的对象必须定义hashCode()。
Hashset实现set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set的迭代顺序,别是它不保证该顺序恒久不变。此类允许使用Null元素
对于HashSet而言,它是基于HashMap实现的,HashSet底层使用HashMap来保存所有元素,因此HashSet的实现比较简单,相关HashSet的操作,基本上都说调用HashMap的相关方法来实现的
对于HashSet中保存的对象,请注意正确重写其equals和hashCode方法,以保证放入的对象的唯一性。
HashSet: 哈希表结构的集合 利用哈希表结果构成的集合查找速度会很快。
HashSet : 底层数据结构是哈希表,线程 是不同步的 。 无序,高效;HashSet 集合保证元素唯一性 :通过元素的 hashCode 方法,和 equals 方法完成的。当元素的 hashCode 值相同时,才继续判断元素的 equals 是否为 true。如果为 true,那么视为相同元素,不存。如果为 false,那么存储。如果 hashCode 值不同,那么不判断 equals,从而提高对象比较的速度。
HashSet类直接实现了Set接口, 其底层其实是包装了一个HashMap去实现的。HashSet采用HashCode算法来存取集合中的元素,因此具有比较好的读取和查找性能。
元素值可以为NULL,但只能放入一个null
HashSet集合保证元素唯一性:通过元素的hashCode方法,和equals方法完成的。
当元素的hashCode值相同时,才继续判断元素的equals是否为true。
如果hashCode值不同,那么不判断equals,从而提高对象比较的速度。
对于HashSet集合,判断元素是否存在,或者删除元素,底层依据的是hashCode方法和equals方法。
特点:存储取出都比较快
1、不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化。
2、HashSet不是同步的,必须通过代码来保证其同步。
3、集合元素可以是null.
原理:简单说就是链表数组结合体
对象的哈希值:普通的一个整数,可以理解为身份证号,是hashset存储的依据
HashSet按Hash算法来存储集合中的元素。在存取和查找上有很好的性能。
当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据该hashCode值决定该hashCode值决定该对象在HashSet中存储的位置。
如果有两个元素通过equals()方法比较返回true,但它们的hashCode()方法返回值不相等,hashSet将会把它们存储在不同位置,依然可以添加成功。如果两个对象的hashCode()方法返回的hashCode值相同,当它们的equals()方法返回false时,会在hashCode所在位置采用链式结构保存多个对象。这样会降低hashSet的查询性能。
在使用HashSet中重写hashCode()方法的基本原则
1、在程序运行过过程中,同一个对象多次调用hashCode()方法应该返回相同的值。
2、当两个对象的equals()方法比较返回true时,这个两个对象的hashCode()方法返回相同的值。
3、对象中用作equals()方法比较标准的实例变量,都应该用于计算hashCode值。
把对象内的每个意义的实例变量(即每个参与equals()方法比较标准的实例变量)计算出一个int类型的hashCode值。用第1步计算出来的多个hashCode值组合计算出一个hashCode值返回
1 | return f1.hashCode()+(int)f2; |
为了避免直接相加产生的偶然相等(两个对象的f1、f2实例变量并不相等,但他们的hashCode的和恰好相等),可以通过为各个实例变量的hashCode值乘以一个质数后再相加
1 | return f1.hashCode()*19+f2.hashCode()*37; |
如果向HashSet中添加一个可变的对象后,后面的程序修改了该可变对想的实例变量,则可能导致它与集合中的其他元素的相同(即两个对象的equals()方法比较返回true,两个对象的hashCode值也相等),这就有可能导致HashSet中包含两个相同的对象。
Linkedhashset
LinkedHashSet : 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序
LinkedHashSet 综合了链表+哈希表,根据元素的hashCode值来决定元素的存储位置,它同时使用链表维护元素的次序。
当遍历该集合时候,LinkedHashSet 将会以元素的添加顺序访问集合的元素。
对于 LinkedHashSet 而言,它继承与 HashSet、又基于 LinkedHashMap 来实现的。
这个相对于HashSet来说有一个很大的不一样是LinkedHashSet是有序的。LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
与HashSet相比,特点:
对集合迭代时,按增加顺序返回元素。
性能略低于HashSet,因为需要维护元素的插入顺序。但迭代访问元素时会有好性能,因为它采用链表维护内部顺序。
LinkedHashSet不允许元素的重复
存储的顺序是元素插入的顺序。
TreeSet
TreeSet : 保存次序的Set, 底层为树结构。使用它可以从Set中提取有序的序列。
TreeSet 继承AbstractSet类,实现NavigableSet、Cloneable、Serializable接口。与HashSet是基于HashMap实现一样,TreeSet 同样是基于TreeMap 实现的。由于得到Tree 的支持,TreeSet 最大特点在于排序,它的作用是提供有序的Set集合。
用于对 Set 集合进行元素的指定顺序排序,排序需要依据元素自身具备的比较性。
如果元素不具备比较性,在运行时会抛出ClassCastException 异常。 所以元素需要实现Comparable 接口 ,让元素具备可比较性, 重写 compareTo 方法 。依据 compareTo 方法的返回值,确定元素在 TreeSet 数据结构中的位置。 或者用比较器方式,将Comparator对象传递给TreeSet构造器来告诉树集使用不同的比较方法
TreeSet底层的数据结构就是二叉树。
- 不能写入空数据
- 写入的数据是有序的。
- 不写入重复数据
TreeSet方法保证元素唯一性的方式:就是参考比较方法的结果是否为0,如果return 0,视为两个对象重复,不存。
TreeSet集合排序有两种方式,Comparable和Comparator区别:
1:让元素自身具备比较性,需要元素对象实现Comparable接口,覆盖compareTo方法。
2:让集合自身具备比较性,需要定义一个实现了Comparator接口的比较器,并覆盖compare方法,并将该类对象作为实际参数传递给TreeSet集合的构造函数。
TreeSet类是SortedSet接口的实现类。因为需要排序,所以性能肯定差于HashSet。与HashSet相比,额外增加的方法有:
first():返回第一个元素
last():返回最后一个元素
lower(Object o):返回指定元素之前的元素
higher(Obect o):返回指定元素之后的元素
subSet(fromElement, toElement):返回子集合
可以定义比较器(Comparator)来实现自定义的排序。默认自然升序排序。
TreeSet两种排序方式:自然排序和定制排序,默认情况下,TreeSet采用自然排序
TreeSet会调用集合元素的compareTo(Object object)方法来比较元素之间的大小关系,然后将元素按升序排列
如果试图把一个元素添加到TreeSet中,则该对象必须实现Comparable接口实现Comparable接口必须实现compareTo(Object object),两个对象即通过这个方法进行比较Comparable的典型实现
BigDecimal、BigInteger以及所有的数值类型对应的包装类型,按对应的数值大小进行比较
Character:按字符的Unicode值进行比较
Boolean:true对应的包装类实例大于false包装类对应的实例
String:按字符对应的Unicode值进行比较
Date、Time:后面的时间、日期比前面的时间、日期大
向TreeSet中添加一个元素,只有第一个不需要使用compareTo()方法,后面的都要调用该方法
因为只有相同类的两个实例才会比较大小,所以向TreeSet中添加的应该是同一个类的对象
TreeSet采用红黑树的数据结构来存储集合元素
对于TreeSet集合而言,它判断两个对象的是否相等的唯一标准是:两个对象的通过compareTo(Object obj)方法比较是否返回0–如果通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等,否则认为它们不相等。对于语句,obj1.compareTo(obj2),如果该方法返回一个正整数,则表明obj1大于obj2;如果该方法返回一个负整数,则表明obj1小于obj2.
在默认的compareTo方法中,需要将的两个的类型的对象的转换同一个类型,因此需要将的保证的加入到TreeSet中的数据类型是同一个类型,但是如果自己覆盖compareTo方法时,没有要求两个对象强制转换成同一个对象,是可以成功的添加treeSet中
如果两个对象通过CompareTo(Object obj)方法比较返回0时,但它们通过equals()方法比较返回false时,TreeSet不会让第二个元素添加进去
Map
Map主要用于存储健值对,根据键得到值,因此不允许键重复,但允许值重复。
Map接口概述:Java.util.Map<k,v>接口:是一个双列集合
Map集合的特点: 是一个双列集合,有两个泛型key和value,使用的时候key和value的数据类型可以相同。也可以不同.
Key不允许重复的,value可以重复的;
一个key只能对应一个value
底层是一个哈希表(数组+单向链表):查询快,增删快, 是一个无序集合
Map接口中的常用方法:
1.get(key) 根据key值返回对应的value值,key值不存在则返回null
2.put(key , value); 往集合中添加元素(key和value)
注意:添加的时候,如果key不存在,返回值null
如果Key已经存在的话,就会新值替换旧值,返回旧值
- remove(key); 删除key值对应的键值对;如果key不存在 ,删除失败。返回值为 null,如果key存在则删除成功,返回值为删除的value
Map遍历方式
第一种方式:通过key找value的方式:
Map中有一个方法:
Set
操作步骤:
1.调用Map集合的中方法keySet,把Map集合中所有的健取出来,存储到Set集合中
2.遍历Set集合,获取Map集合中的每一个健
3.通过Map集合中的方法get(key),获取value值
可以使用迭代器跟增强for循环遍历
第二种方式:Map集合遍历键值方式
Map集合中的一个方法:
Set<Map.Entry<k,v>> entrySet(); 返回此映射中包含的映射关系的Set视图
使用步骤
* 1.使用Map集合中的方法entrySet,把键值对(键与值的映射关系),取出来存储到Set 集合中
* 2.遍历Set集合,获取每一个Entry对象
* 3.使用Entry对象中的方法getKey和getValue获取健和值
可以使用迭代器跟增强for循环遍历
Collection中的集合元素是孤立的,可理解为单身,是一个一个存进去的,称为单列集合
Map中的集合元素是成对存在的,可理解为夫妻,是一对一对存进去的,称为双列集合
Map中存入的是:键值对,键不可以重复,值可以重复
Map主要用于存储带有映射关系的数据(比如学号与学生信息的映射关系)
Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个 value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
Map具有将对象映射到其他对象的功能,是一个K-V形式存储容器,你可以通过containsKey()和containsValue()来判断集合是否包含某个减或某个值。Map可以很容以拓展到多维(值可以是其他容器甚至是其他Map):
Map<Object,List
Map集合的数据结构仅仅针对键有效,与值无关。
HashMap
HashMap非线程安全,高效,支持null;
根据键的HashCode 来存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。
HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null。(不允许键重复,但允许值重复)
HashMap不支持线程的同步(任一时刻可以有多个线程同时写HashMap,即线程非安全),可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap() 方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Hashtable与 HashMap类似。不同的是:它不允许记录的键或者值为空;它支持线程的同步(任一时刻只有一个线程能写Hashtable,即线程安全),因此也导致了 Hashtable 在写入时会比较慢。
HashMap里面存入的值在取出的时候是随机的,它根据键的HashCode来存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
HashMap基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
值得注意的是HashMap不是线程安全的,如果想要线程安全的HashMap,可以通过Collections类的静态方法synchronizedMap获得线程安全的HashMap。
Map map = Collections.synchronizedMap(new HashMap());
HashMap的底层主要是基于数组和链表来实现的,它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储的位置。HashMap中主要是通过key的hashCode来计算hash值的,只要hashCode相同,计算出来的hash值就一样。如果存储的对象对多了,就有可能不同的对象所算出来的hash值是相同的,这就出现了所谓的hash冲突。学过数据结构的同学都知道,解决hash冲突的方法有很多,HashMap底层是通过链表来解决hash冲突的。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
HashMap是常用的Java集合之一,是基于哈希表的Map接口的实现。与HashTable主要区别为不支持同步和允许null作为key和value。由于HashMap不是线程安全的,如果想要线程安全,可以使用ConcurrentHashMap代替。
HashMap的底层是哈希数组,数组元素为Entry。HashMap通过key的hashCode来计算hash值,当hashCode相同时,通过“拉链法”解决冲突
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。原本Map.Entry接口的实现类Entry改名为了Node。转化为红黑树时改用另一种实现TreeNode。

1.8中最大的变化就是在一个Bucket中,如果存储节点的数量超过了8个,就会将该Bucket中原来以链表形式存储节点转换为以树的形式存储节点;而如果少于6个,就会还原成链表形式存储。
为什么要这样做?前面已经说过LinkedList的遍历操作不太友好,如果在节点个数比较多的情况下性能会比较差,而树的遍历效率是比较好的,主要是优化遍历,提升性能。
HashMap:去掉了contains(),保留了containsKey(),containsValue()
HashMap:key,value可以为空.null作为key只能有一个,null作为value可以存在多个
HashMap:使用Iterator
HashMap:数组初始大小为16,扩容方式为2的指数幂形式
HashMap:重新计算hash值
HashMap是基于哈希表的Map接口的实现,HashMap是一个散列表,存储的内容是键值对(key-value)映射,键值对都可为null;
HashMap继承自 AbstractMap<K, V> 并实现Map<K, V>, Cloneable, Serializable接口;
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。底层是个数组,数组上存储的数据是Entry<K,V>类型的链表结构对象。
HashMap是无序的,LinkedHashMap和treeMap是有序的;
HashMap基于哈希原理,可以通过put和get方法存储和获取对象。当我们将键值对传递给put方法时,它调用键对象的hashCode()方法来计算hashcode,然后找到对应的bucket位置存储键对象和值对象作为Map.Entry;如果两个对象的hashcode相同,所以对应的bucket位置是相同的,HashMap采用链表解决冲突碰撞,这个Entry(包含有键值对的Map.Entry对象)会存储到链表的下一个节点中;如果对应的hashcode和key值都相同,则修改对应的value的值。HashMap在每个链表节点中存储键值对对象。当使用get()方法获取对象时,HashMap会根据键对象的hashcode去找到对应的bucket位置,找到对应的bucket位置后会调用keys.equals()方法去找到连表中对应的正确的节点找到对象。
HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
HashMap存数据的过程是:
HashMap内部维护了一个存储数据的Entry数组,HashMap采用链表解决冲突,每一个Entry本质上是一个单向链表。当准备添加一个key-value对时,首先通过hash(key)方法计算hash值,然后通过indexFor(hash,length)求该key-value对的存储位置,计算方法是先用hash&0x7FFFFFFF后,再对length取模,这就保证每一个key-value对都能存入HashMap中,当计算出的位置相同时,由于存入位置是一个链表,则把这个key-value对插入链表头。
HashMap中key和value都允许为null。key为null的键值对永远都放在以table[0]为头结点的链表中。
HashMap内存储数据的Entry数组默认是16,如果没有对Entry扩容机制的话,当存储的数据一多,Entry内部的链表会很长,这就失去了HashMap的存储意义了。所以HasnMap内部有自己的扩容机制。HashMap内部有:
变量size,它记录HashMap的底层数组中已用槽的数量;
变量threshold,它是HashMap的阈值,用于判断是否需要调整HashMap的容量(threshold = 容量*加载因子)
变量DEFAULT_LOAD_FACTOR = 0.75f,默认加载因子为0.75
HashMap扩容的条件是:当size大于threshold时,对HashMap进行扩容
扩容是是新建了一个HashMap的底层数组,而后调用transfer方法,将就HashMap的全部元素添加到新的HashMap中(要重新计算元素在新的数组中的索引位置)。 很明显,扩容是一个相当耗时的操作,因为它需要重新计算这些元素在新的数组中的位置并进行复制处理。因此,我们在用HashMap的时,最好能提前预估下HashMap中元素的个数,这样有助于提高HashMap的性能。
加载因子,如果加载因子越大,对空间的利用更充分,但是查找效率会降低(链表长度会越来越长);如果加载因子太小,那么表中的数据将过于稀疏(很多空间还没用,就开始扩容了),对空间造成严重浪费。如果我们在构造方法中不指定,则系统默认加载因子为0.75,这是一个比较理想的值,一般情况下我们是无需修改的。另外,无论我们指定的容量为多少,构造方法都会将实际容量设为不小于指定容量的2的次方的一个数,且最大值不能超过2的30次方。
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
HashMap扩容时是当前容量翻倍即:capacity2,Hashtable扩容时是容量翻倍+1即:capacity2+1。
HashMap和Hashtable的底层实现都是数组+链表结构实现。
HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取摸:
1 | static int hash(int h) { |
HashTable
HashTable线程安全,低效,不支持null ,Hashtable是同步的
HashTable这个类实现了哈希表从key映射到value的数据结构形式。任何非null的对象都可以作为key或者value。
要在hashtable中存储和检索对象,作为key的对象必须实现hashCode、equals方法。
一般来说,默认的加载因子(0.75)提供了一种对于空间、时间消耗比较好的权衡策略。太高的值(指加载因子loadFactor)虽然减少了空间开销但是增加了检索时间,这反应在对hashtable的很多操作中,比如get、put方法。
初始容量的控制也是在空间消耗和rehash操作耗时(该操作耗时较大)二者之间的权衡。 如果初始容量大于哈希表的当前最大的条目数除以加载因子,则不会发生rehash。但是,将初始容量设置过高会浪费空间。
如果有大量的数据需要放进hashtable,则选择设置较大的初始容量比它自动rehash更优。
如果不需要线程安全的实现,建议使用HashMap代替Hashtable
如果想要一个线程安全的高并发实现,那么建议使用java.util.concurrent.ConcurrentHashMap取代了Hashtable。
HashTable的父类是Dictionary
HashTable:线程安全,HashTable方法有synchronized修饰
HashTable:保留了contains(),containsKey(),containsValue()
HashTable:key,value都不能为空.原因是源码中方法里会遍历entry,然后用entry的key或者value调用equals(),所以要先判断key/value是否为空,如果为空就会抛出异常
HashTable:使用Enumeration,Iterator
HashTable:数组初始大小为11,扩容方式为2*old+1
HashTable: 直接使用hashcode()
Hashtable同样是基于哈希表实现的,同样每个元素是一个key-value对,其内部也是通过单链表解决冲突问题,容量不足(超过了阀值)时,同样会自动增长。
Hashtable也是JDK1.0引入的类,是线程安全的,能用于多线程环境中。
Hashtable同样实现了Serializable接口,它支持序列化,实现了Cloneable接口,能被克隆。
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模:
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
底层数据结构是哈希表,特点和 hashMap 是一样的
Hashtable 是线程安全的集合,是单线程的,运行速度慢
HashMap 是线程不安全的集合,是多线程的,运行速度快
Hashtable 命运和 Vector 是一样的,从 JDK1.2 开始,被更先进的 HashMap 取代
HashMap 允许存储 null 值,null 健
Hashtable 不允许存储 null 值,null 健
Hashtable 他的孩子,子类 Properties 依然活跃在开发舞台
Properties
Java.util.Properties 集合extends Hashtable<k,v> 集合
Properties 集合特点:
Properties集合也是一个双列集合,key跟value都已经被内置为String类型
Properties集合是一个唯一和IO流相结合的集合
可以将集合中存储的临时数据,持久化到硬盘的文件中储存
可以把文件中储存对的键值对,读取到集合中使用
Properties集合的基本操作:添加数据,遍历集合,Key和value都已经被内置为String类型。里面包含了一些和String类的相关方法
Object setProperty(String key ,String value) 往集合中添加键值对,调用Hashtable的方法put添加
String getProperty(String key ) 通过key获取value的值,相当于Map集合中的get(key) 方法
Set<String > stringPropertyNames()返回此属性列表的键集。相当于Map集合中的keySet()方法;
Properties类的load方法:
可以把文件中存储的键值对,读取到集合中使用
void load(Reader reader)
void load(InputStream inStream)
参数:
Reader reader:字符输入流,可以使用FileReader
InputStream inStream:字节输入流,可以使用FileInputStream
操作步骤:
1.创建Properties集合对象
2.创建字符输入流FileReader对象,构造方法中绑定要读取的数据源
3.使用Properties集合中的方法load,把文件中存储的键值对,读取到集合中使 用
4.释放资源
5.遍历Properties集合
注意:
1.流使用Reader字符流,可以读取中文数据
2.流使用InputStream字节流,不能操作中文,会有乱码
3.Properties集合的配置文件中,可以使用注释单行数据,使用#
4.Properties集合的配置文件中,key和value默认都是字符串,不用添加””(画蛇 添足)
5.Properties集合的配置文件中,key和value的连接符号可以使用=,也可以使用 空格
Properties类的store方法使用:
可以把集合中存储的临时数据,持久化都硬盘的文件中存储
1 | void store(Writer writer, String comments) |
参数:
Writer writer:字符输出流,可以使用FileWriter
OutputStream out:字节输出流,可以使用FileOutputStream
String comments:注释,解释说明存储的文件,不能使用中文(乱码),默认编码格式为 Unicode编码
可以使用””空字符串
操作步骤:
1.创建Properties集合,往集合中添加数据
2.创建字符输出流FileWriter对象,构造方法中绑定要写入的目的地
3.调用Properties集合中的方法store,把集合中存储的临时数据,持久化都硬盘的文 件中存储
4.释放资源
注意:
1.流使用Writer字符流,可以写入中文数据的
2.流使用OutputStream字节流,不能操作中文,会有乱码
3.Propertie集合存储的文件,一般都以.properties结尾(程序员默认)
HashMap多线程put操作后,get操作导致死循环。为何出现死循环?
大家都知道,HashMap采用链表解决Hash冲突,具体的HashMap的分析因为是链表结构,那么就很容易形成闭合的链路,这样在循环的时候只要有线程对这个HashMap进行get操作就会产生死循环。但是,我好奇的是,这种闭合的链路是如何形成的呢。在单线程情况下,只有一个线程对HashMap的数据结构进行操作,是不可能产生闭合的回路的。那就只有在多线程并发的情况下才会出现这种情况,那就是在put操作的时候,如果size>initialCapacity*loadFactor,那么这时候HashMap就会进行rehash操作,随之HashMap的结构就会发生翻天覆地的变化。很有可能就是在两个线程在这个时候同时触发了rehash操作,产生了闭合的回路。
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度依然为O(1),因为最新的Entry会插入链表头部,急需要简单改变引用链即可,而对于查找操作来讲,此时就需要遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap存储自定义类型:使用HashMap储存自定义类形式,因为要保证key的唯一性。需要 自定义类重写 hashCode()跟equals()方法;
HashMap的方法基本都是Map中声明的方法
实现原理:实现一个哈希表,存储元素(key/value)时,用key计算hash值,如果hash值没有碰撞,则只用数组存储元素;如果hash值碰撞了,则相同的hash值的元素用链表存储;如果相同hash值超过8个,则相同的hash值的元素用红黑树存储。获取元素时,用key计算hash值,用hash值计算元素在数组中的下标,取得元素如果命中,则返回;如果不是就在红黑树或链表中找。
PS:存储元素的数组是有冗余的。
采用了Fail-Fast机制,通过一个modCount值记录修改次数,在迭代过程中,判断modCount跟初始过程记录的expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map,马上抛出异常;另外扩容过程中还有可能产生环形链表。
synchronized是针对整张Hash表的,即每次锁住整张表让线程独占
LinkeHashMap
LinkedHashMap继承自HashMap,实现了Map<K,V>接口。其内部还维护了一个双向链表,在每次插入数据,或者访问、修改数据时,会增加节点、或调整链表的节点顺序。以决定迭代时输出的顺序。
默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。
也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。
LinkedHashMap在实现时,就是重写override了几个方法。以满足其输出序列有序的需求。
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。
在遍历的时候会比HashMap慢,不过有种情况例外:当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢。因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和它的容量有关。
LinkedHashMap是HashMap的子类,保存了插入的顺序,需要输出的顺序和输入的顺序相同时可用LinkedHashMap;
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现.
LinkedHashMap取键值对时,是按照你放入的顺序来取的。
LinkedHashMap由于它的插入有序特性,也是一种比较常用的Map集合。它继承了HashMap,很多方法都直接复用了父类HashMap的方法。本文将探讨LinkedHashMap的内部实现,以及它是如何保证插入元素是按插入顺序排序的。
在分析前可以先思考下,既然是按照插入顺序,并且以Linked-开头,就很有可能是链表实现。如果纯粹以链表实现,也不是不可以,LinkedHashMap内部维护一个链表,插入一个元素则把它封装成Entry节点,并把它插入到链表尾部。功能可以实现,但这带来的查找效率达到了O(n),显然远远大于HashMap在没有冲突的情况下O(1)的时间复杂度。这就丝毫不能体现出Map这种数据结构随机存取快的优点。
所以显然,LinkedHashMap不可能只有一个链表来维护Entry节点,它极有可能维护了两种数据结构:散列表+链表。
LinkedHashMap的LRU特性
先讲一下LRU的定义:LRU(Least Recently Used),即最近最少使用算法,最初是用于内存管理中将无效的内存块腾出而用于加载数据以提高内存使用效率而发明的算法。
目前已经普遍用于提高缓存的命中率,如Redis、Memcached中都有使用。
为啥说LinkedHashMap本身就实现了LRU算法?原因就在于它额外维护的双向链表中。
在上面已经提到过,在做get/put操作时,LinkedHashMap会将当前访问/插入的节点移动到链表尾部,所以此时链表头部的那个节点就是 “最近最少未被访问”的节点。
举个例子:
往一个空的LinkedHashMap中插入A、B、C三个结点,那么链表会经历以下三个状态:
A 插入A节点,此时整个链表只有这一个节点,既是头节点也是尾节点
A -> B 插入B节点后,此时A为头节点,B为尾节点,而最近最常访问的节点就是B节点(刚被插入),而最近最少使用的节点就是A节点(相对B节点来讲,A节点已经有一段时间没有被访问过)
A -> B -> C 插入C节点后,此时A为头节点,C为尾节点,而最近最常访问的节点就是C节点(刚被插入),最近最少使用的节点就是A节点 (应该很好理解了吧 : ))
那么对于缓存来讲,A就是我最长时间没访问过的缓存,C就是最近才访问过的缓存,所以当缓存队列满时就会从头开始替换新的缓存值进去,从而保证缓存队列中的缓存尽可能是最近一段时间访问过的缓存,提高缓存命中率。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序。
默认是按键的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
TreeMap是基于红黑树结构实现的一种Map,要分析TreeMap的实现首先就要对红黑树有所了解。
要了解什么是红黑树,就要了解它的存在主要是为了解决什么问题,对比其他数据结构比如数组,链表,Hash表等树这种结构又有什么优点。
treeMap实现了sortMap接口,能够把保存的数据按照键的值排序,默认是按照自然数排序也可自定义排序方式。
TreeMap对键进行排序了。
当用Iterator遍历TreeMap时,得到的记录是排过序的。
如果使用排序的映射,建议使用TreeMap。
在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
二叉树插入元素是有顺序的,TreeSet的元素是有序的。
由于二叉树需要对结点排序(插入的结点位置),默认情况下没有排序方法,所以元素需要继承Comparator并重写compareTo方法来实现元素之间比较大小的功能。
对于TreeSet,compareTo方法来保证元素的唯一性。【这时候可以不重写equals】
二叉树需要结点排序,所以元素之间比较能够比较,所以对于自定义元素对象,需要继承Comparator并重写的compareTo方法。 两个元素相等时,compareTo返回0;左大于右时,返回正整数(一般返回1);小于时返回负整数(一般返回-1)
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n)
TreeMap中默认的排序为升序
使用entrySet遍历方式要比keySet遍历方式快
entrySet遍历方式获取Value对象是直接从Entry对象中直接获得,时间复杂度T(n)=o(1);
keySet遍历获取Value对象则要从Map中重新获取,时间复杂度T(n)=o(n);keySet遍历Map方式比entrySet遍历Map方式多了一次循环,多遍历了一次table,当Map的size越大时,遍历的效率差别就越大。
HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的)。
在Map 中插入、删除和定位元素,HashMap是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和 equals()的实现。
TreeMap 底层数据结构是红黑树(一种自平衡的二叉树) ,其根据比较的返回值是否是0来保证元素唯一性, 元素的排序通过两种方式:第一种是自然排序(元素具备比较性) 即让元素所属的类实现Comparable接口,第二种是比较器排序(集合具备比较性) ,即让集合接收一个Comparator的实现类对象。
Comparable 和 Comparator 的区别:
Comparable 是一个比较的标准,里面有比较的方法,对象要具有比较的标准,就必须实现 Comparable 接口;类实现这个接口,就有比较的方法;把元素放到 TreeSet 里面去,就会自动的调用 CompareTo 方法;但是这个 Comparable 并不是专为 TreeSet 设计的;只是说,TreeSet 顺便利用而已;就像 HashCode 和 equals 也一样,不是专门为 HashSet 设计一样;只是你顺便利用而已。
Compartor 是个比较器,也不是专门为TreeSet设计. 就是一个第三方的比较器接口;如果对象没有比较性,自己就可以按照比较器的标准,设计一个比较器,创建一个类,实现这个接口,覆写方法。
Queue
Queue用于模拟队列这种数据结构,实现“FIFO”等数据结构。即第一个放进去就是第一个拿出来的元素(从一端进去,从另一端出来)。队列常作被当作一个可靠的将对象从程序的某个区域传输到另一个区域的途径。通常,队列不允许随机访问队列中的元素。
Queue 接口并未定义阻塞队列的方法,而这在并发编程中是很常见的。BlockingQueue 接口定义了那些等待元素出现或等待队列中有可用空间的方法,这些方法扩展了此接口。
Queue 实现通常不允许插入 null 元素,尽管某些实现(如 LinkedList)并不禁止插入 null。即使在允许 null 的实现中,也不应该将 null 插入到 Queue 中,因为 null 也用作 poll 方法的一个特殊返回值,表明队列不包含元素。
LinkedList提供了方法以支持队列的行为,并且实现了Queue接口。通过LinkedList向上转型(up cast)为Queue,看Queue的实现就知道相对于LinkedList,Queue添加了element、offer、peek、poll、remove方法
offer:在允许的情况下,将一个元素插入到队尾,或者返回false
peek,element:在不移除的情况下返回队头,peek在队列为空返回null,element抛异常NoSuchElementException
poll,remove:移除并返回队头,poll当队列为空是返回null,remove抛出NoSuchElementException异常
注意:queue.offer在自动包装机制会自动的把random.nextInt转化程Integer,把char转化成Character
Deque
Deque是Queue的子接口,我们知道Queue是一种队列形式,而Deque则是双向队列,它支持从两个端点方向检索和插入元素,因此Deque既可以支持LIFO形式也可以支持LIFO形式.Deque接口是一种比Stack和Vector更为丰富的抽象数据形式,因为它同时实现了以上两者.
添加功能
void push(E) 向队列头部插入一个元素,失败时抛出异常
void addFirst(E) 向队列头部插入一个元素,失败时抛出异常
void addLast(E) 向队列尾部插入一个元素,失败时抛出异常
boolean offerFirst(E) 向队列头部加入一个元素,失败时返回false
boolean offerLast(E) 向队列尾部加入一个元素,失败时返回false
获取功能
E getFirst() 获取队列头部元素,队列为空时抛出异常
E getLast() 获取队列尾部元素,队列为空时抛出异常
E peekFirst() 获取队列头部元素,队列为空时返回null
E peekLast() 获取队列尾部元素,队列为空时返回null
删除功能
boolean removeFirstOccurrence(Object) 删除第一次出现的指定元素,不存在时返回false
boolean removeLastOccurrence(Object) 删除最后一次出现的指定元素,不存在时返回false
弹出功能
E pop() 弹出队列头部元素,队列为空时抛出异常
E removeFirst() 弹出队列头部元素,队列为空时抛出异常
E removeLast() 弹出队列尾部元素,队列为空时抛出异常
E pollFirst() 弹出队列头部元素,队列为空时返回null
E pollLast() 弹出队列尾部元素,队列为空时返回null
迭代器
Iterator<E> descendingIterator() 返回队列反向迭代器
同Queue一样,Deque的实现也可以划分成通用实现和并发实现.
通用实现主要有两个实现类ArrayDeque和LinkedList.
ArrayDeque是个可变数组,它是在Java 6之后新添加的,而LinkedList是一种链表结构的list,LinkedList要比ArrayDeque更加灵活,因为它也实现了List接口的所有操作,并且可以插入null元素,这在ArrayDeque中是不允许的.
从效率来看,ArrayDeque要比LinkedList在两端增删元素上更为高效,因为没有在节点创建删除上的开销.最适合使用LinkedList的情况是迭代队列时删除当前迭代的元素.此外LinkedList可能是在遍历元素时最差的数据结构,并且也LinkedList占用更多的内存,因为LinkedList是通过链表连接其整个队列,它的元素在内存中是随机分布的,需要通过每个节点包含的前后节点的内存地址去访问前后元素.
总体ArrayDeque要比LinkedList更优越,在大队列的测试上有3倍与LinkedList的性能,最好的是给ArrayDeque一个较大的初始化大小,以避免底层数组扩容时数据拷贝的开销.
LinkedBlockingDeque是Deque的并发实现,在队列为空的时候,它的takeFirst,takeLast会阻塞等待队列处于可用状态
Stack
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得 Vector得以被当作堆栈使用。基本的push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
栈,是指“LIFO”先进后出的集合容器,最后一个压入的元素是第一个出来的,就好比我们洗碗一样(或者叠罗汉)第一个摆放的碗放在最下面,自然是最后一个拿出来的。Stack是由LinkedList实现的,作为Stack的实现,下面是《java编程思想》给出基本的Stack实现:
peek和pop是返回T类型的对象。peek方法提供栈顶元素,但不删除栈顶,而pop是返回并删除栈顶元素;
ArrayDeque
ArrayDeque类是双端队列的实现类,类的继承结构如下面,继承自AbastractCollection(该类实习了部分集合通用的方法,其实现了Collection接口),其实现的接口Deque接口中定义了双端队列的主要的方法,比如从头删除,从尾部删除,获取头数据,获取尾部数据等等。
1 | public class ArrayDeque<E> extends AbstractCollection<E> implements Deque<E>, Cloneable, Serializable |
ArrayDeque基本特征
就其实现而言,ArrayDeque采用了循环数组的方式来完成双端队列的功能。
无限的扩展,自动扩展队列大小的。(当然在不会内存溢出的情况下。)
非线程安全的,不支持并发访问和修改。
支持fast-fail.
作为栈使用的话比比栈要快.
当队列使用比linklist要快。
null元素被禁止使用。
最小初始化容量限制8(必须是2的幂次)
扩容:之所以说该ArrayDeque容量无限制,是因为只要检测到head==tail的时候,就直接调用doubleCapacity方法进行扩容。
删除元素:删除元素的基本思路为确定那一侧的数据少,少的一侧移动元素位置,这样效率相对于不比较更高些,然后,判断head是跨越最大值还是为跨越最大值,继而可以分两种不同的情况进行拷贝。但是该方法比较慢,因为存在数组的拷贝。
获取并删除元素:这里在举个简单点的例子,中间判断是不是null,可以看出该队列不支持null,通过把其值设为null就算是将其删除了。然后head向递增的方向退一位即可。
ArrayDeque和LinkedList是Deque的两个通用实现
ArrayDeque不是线程安全的。
ArrayDeque不可以存取null元素,因为系统根据某个位置是否为null来判断元素的存在。
当作为栈使用时,性能比Stack好;当作为队列使用时,性能比LinkedList好。
1.添加元素 addFirst(E e)在数组前面添加元素 addLast(E e)在数组后面添加元素 offerFirst(E e) 在数组前面添加元素,并返回是否添加成功 offerLast(E e) 在数组后天添加元素,并返回是否添加成功
2.删除元素 removeFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将抛出异常 pollFirst()删除第一个元素,并返回删除元素的值,如果元素为null,将返回null removeLast()删除最后一个元素,并返回删除元素的值,如果为null,将抛出异常 pollLast()删除最后一个元素,并返回删除元素的值,如果为null,将返回null removeFirstOccurrence(Object o) 删除第一次出现的指定元素 removeLastOccurrence(Object o) 删除最后一次出现的指定元素
3.获取元素 getFirst() 获取第一个元素,如果没有将抛出异常 getLast() 获取最后一个元素,如果没有将抛出异常
4.队列操作 add(E e) 在队列尾部添加一个元素 offer(E e) 在队列尾部添加一个元素,并返回是否成功 remove() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将抛出异常(其实底层调用的是removeFirst()) poll() 删除队列中第一个元素,并返回该元素的值,如果元素为null,将返回null(其实调用的是pollFirst()) element() 获取第一个元素,如果没有将抛出异常 peek() 获取第一个元素,如果返回null
5.栈操作 push(E e) 栈顶添加一个元素 pop(E e) 移除栈顶元素,如果栈顶没有元素将抛出异常
6.其他 size() 获取队列中元素个数 isEmpty() 判断队列是否为空 iterator() 迭代器,从前向后迭代 descendingIterator() 迭代器,从后向前迭代 contain(Object o) 判断队列中是否存在该元素 toArray() 转成数组 clear() 清空队列 clone() 克隆(复制)一个新的队列
PriorityQueue
我们知道队列是遵循先进先出(First-In-First-Out)模式的,但有些时候需要在队列中基于优先级处理对象。举个例子,比方说我们有一个每日交易时段生成股票报告的应用程序,需要处理大量数据并且花费很多处理时间。客户向这个应用程序发送请求时,实际上就进入了队列。我们需要首先处理优先客户再处理普通用户。在这种情况下,Java的PriorityQueue(优先队列)会很有帮助。
PriorityQueue类在Java1.5中引入并作为 Java Collections Framework 的一部分。PriorityQueue是基于优先堆的一个无界队列,这个优先队列中的元素可以默认自然排序或者通过提供的Comparator(比较器)在队列实例化的时排序。
优先队列不允许空值,而且不支持non-comparable(不可比较)的对象,比如用户自定义的类。优先队列要求使用Java Comparable和Comparator接口给对象排序,并且在排序时会按照优先级处理其中的元素。
优先队列的头是基于自然排序或者Comparator排序的最小元素。如果有多个对象拥有同样的排序,那么就可能随机地取其中任意一个。当我们获取队列时,返回队列的头对象。
优先队列的大小是不受限制的,但在创建时可以指定初始大小。当我们向优先队列增加元素的时候,队列大小会自动增加。
PriorityQueue是非线程安全的,所以Java提供了PriorityBlockingQueue(实现BlockingQueue接口)用于Java多线程环境。
由于知道PriorityQueue是基于Heap的,当新的元素存储时,会调用siftUpUsingComparator方法
PriorityQueue的逻辑结构是一棵完全二叉树,存储结构其实是一个数组。逻辑结构层次遍历的结果刚好是一个数组。
PriorityQueue优先队列,它逻辑上使用堆结构(完全二叉树)实现,物理上使用动态数组实现,并非像TreeMap一样完全有序,但是如果按照指定方式出队,结果可以是有序的。
这里的堆是一种数据结构而非计算机内存中的堆栈。堆结构在逻辑上是完全二叉树,物理存储上是数组。
完全二叉树并不是堆结构,堆结构是不完全有序的完全二叉树。
BlockingQueue
Java中Queue的最重要的应用大概就是其子类BlockingQueue了。
考虑到生产者消费者模型,我们有多个生产者和多个消费者,生产者不断提供资源给消费者,但如果它们的生产/消费速度不匹配或者不稳定,则会造成大量的生产者闲置/消费者闲置。此时,我们需要使用一个缓冲区来存储资源,即生产者将资源置于缓冲区,而消费者不断地从缓冲区中取用资源,从而减少了闲置和阻塞。
BlockingQueue,阻塞队列,即可视之为一个缓冲区应用于多线程编程之中。当队列为空时,它会阻塞所有消费者线程,而当队列为满时,它会阻塞所有生产者线程。
在queue的基础上,BlockingQueue又添加了以下方法:
put:队列末尾添加一个元素,若队列已满阻塞。
take:移除并返回队列头部元素,若队列已空阻塞。
drainTo:一次性获取所有可用对象,可以用参数指定获取的个数,该操作是原子操作,不需要针对每个元素的获取加锁。
ArrayBlockingQueue
由一个定长数组和两个标识首尾的整型index标识组成,生产者放入数据和消费者取出数据对于ArrayBlockingQueue而言使用了同一个锁(一个私有的ReentrantLock),因而无法实现真正的并行。可以在初始化时除长度参数以外,附加一个boolean类型的变量,用于给其私有的ReentrantLock进行初始化(初始化是否为公平锁,默认为false)。
LinkedBlockingQueue
LinkedBlockingQueue的最大特点是,若没有指定最大容量,其可以视为无界队列(有默认最大容量限制,往往系统资源耗尽也无法达到)。即,不对生产者的行为加以限制,只在队列为空的时候限制消费者的行为。LinkedBlockingQueue采用了读写分离的两个ReentrantLock去控制put和take,因而有了更好的性能(类似读写锁提供读写场景下更好的性能),如下:
1 | /** Lock held by take, poll, etc */ |
ArrayBlockingQueue和LinkedBlockingQueue是最常用的两种阻塞队列。
PriorityBlockingQueue
PriorityBlockingQueue是对PriorityQueue的包装,因而也是一个优先队列。其优先级默认是直接比较,大者先出队,也可以从构造器传入自定义的Comparator。由于PriorityQueue从实现上是一个无界队列,PriorityBlockingQueue同样是一个无界队列,对生产者不做限制。
DelayQueue
DelayQueue是在PriorityBlockingQueue的基础上包装产生的,它用于存放Delayed对象,该队列的头部是延迟期满后保存时间最长的Delayed元素(即,以时间为优先级利用PriorityBlockingQueue),当没有元素延迟期满时,对其进行poll操作将会返回Null。take操作会阻塞。
SynchronousQueue
SynchronousQueue十分特殊,它没有容量——换言之,它是一个长度为0的BlockingQueue,生产者和消费者进行的是无中介的直接交易,当生产者/消费者没有找到合适的目标时,即会发生阻塞。但由于减少了环节,其整体性能在一些系统中可能更加适合。该方法同样支持在构造时确定为公平/默认的非公平模式,如果是非公平模式,有可能会导致某些生产者/消费者饥饿。
WeakHashMap
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
EnumSet类
EnumSet是一个专门为枚举设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型的创建Enumset时显示会隐式的指定。Enumset的集合元素也是有序的,EnumSet以枚举值在Enum类内定义的顺序来决定集合元素的顺序。
使用Java8新增的Predicate操作集合
Java 8为Collection集合新增了removeIf(Predicate filter)方法,该方法将会批量删除符合条件的filter条件的所有元素
使用java 8 新增的Stream操作集合
Java8新增了Stream、IntStream、LongStream、DoubleStream等流式API,这些API代表了多个支持串行和并行聚集操作的元素,其中Stream是一个通用的流接口,而IntStream、LongStream、DoubleStream则代表了类型为int,long,double的流。
独立使用Stream的步骤如下:
1、使用Stream或XxxStream的builder()类方法创建该Stream对应的Builder。
2、重复调用Builder的add()方法向该流中的添加多个元素
3、调用Builder的build()方法获取对应的Stream
4、调用Stream的聚集方法。
在Stream中方法分为两类中间方法和末端方法
中间方法:中间操作允许流保持打开状态,并允许直接调用后续方法。上面程序中的map()方法就是中间方法。
末端方法:末端方法是对流的最终操作。当对某个Stream执行末端方法后,该流将会被”消耗”且不再可用。上面程序中的sum()、count()、average()等方法都是末端方法。
除此之外,关于流的方法还有如下特征:
有状态的方法:这种方法会给你流增加一些新的属性,比如元素的唯一性、元素的最大数量、保证元素的排序的方式被处理等。有状态的方法往往需要更大的性能开销
短路方法:短路方法可以尽早结束对流的操作,不必检查所有的元素。
对CAS的理解,CAS带来的问题,如何解决这些问题?
锁
回答这个问题,可以先介绍一下锁要解决的问题,以及锁机制的缺点。
引入锁就是为了解决多线程竞争同一个资源时,出现脏读、数据不一致问题。一般我们常用的是synchronized等排他锁,
这种锁存在的问题:
1、多线程竞争下,加锁、释放锁会导致比较多的上下文切换和调 度延时,引起性能问题
2、一个线程持有锁会导致其它所有需要此锁的线程挂起直至该锁释放
CAS
cas是另一个无锁解决方案,更准确的是采用乐观锁技术,实现线程安全的问题。cas有三个操作数—-内存对象(V)、预期原值(A)、新值(B)。
CAS原理就是对v对象进行赋值时,先判断原来的值是否为A,如果为A,就把新值B赋值到V对象上面,如果原来的值不是A(代表V的值放生了变化),就不赋新值。
我们看一下AtomicInteger类,AtomicInteger是线程安全的,我们看一下源码
1 | /** |
再看一下unsafe源码1
2
3
4
5
6
7
8public final long getAndAddLong(Object var1, long var2, long var4) {
long var6;
do {
var6 = this.getLongVolatile(var1, var2);
} while(!this.compareAndSwapLong(var1, var2, var6, var6 + var4));
return var6;
}
我们看到do while自循环,这里为什么会有自循环,就是在 判断预期原值 如果与原来的值不符合,会再循环取原值,再走CAS流程,直到能够把新值B赋值成功。
CAS缺点
cas这个方式也存在一定的问题:
1、自循环时间长,开销大
2、只能保证一个共享变量的原子操作
3、ABA问题
什么是ABA问题?
考虑如下操作:
并发1(上):获取出数据的初始值是A,后续计划实施CAS乐观锁,期望数据仍是A的时候,修改才能成功
并发2:将数据修改成B
并发3:将数据修改回A
并发1(下):CAS乐观锁,检测发现初始值还是A,进行数据修改
上述并发环境下,并发1在修改数据时,虽然还是A,但已经不是初始条件的A了,中间发生了A变B,B又变A的变化,此A已经非彼A,数据却成功修改,可能导致错误,这就是CAS引发的所谓的ABA问题。
库存操作,出现ABA问题并不会对业务产生影响。
堆栈操作,会出现ABA的问题。
ABA问题的优化
ABA问题导致的原因,是CAS过程中只简单进行了“值”的校验,再有些情况下,“值”相同不会引入错误的业务逻辑(例如库存),有些情况下,“值”虽然相同,却已经不是原来的数据了。
优化方向:CAS不能只比对“值”,还必须确保的是原来的数据,才能修改成功。
常见实践:“版本号”的比对,一个数据一个版本,版本变化,即使值相同,也不应该修改成功。
一个共享变量的原子操作问题优化
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁来保证原子性。
volatile底层、synchronized底层、锁升级的过程、MESI
volatile底层
Java语言规范对于volatile定义如下:
Java编程语言允许线程访问共享变量,为了确保共享变量能够被准确和一致性地更新,线程应该确保通过排它锁单独获得这个变量。
首先我们从定义开始入手,官方定义比较拗口。通俗来说就是一个字段被volatile修饰,Java的内存模型确保所有的线程看到的这个变量值是一致的,但是它并不能保证多线程的原子操作。这就是所谓的线程可见性。我们要知道他是不能保证原子性的。
内存模型相关概念
Java线程之间的通信由Java内存模型(JMM)控制,JMM决定一个线程对共享变量的修改何时对另外一个线程可见。JMM定义了线程与主内存的抽象关系:线程之间的变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory)保存着共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。
如果线程A与线程B通信:
- 线程A要先把本地内存A中更新过的共享变量刷写到主内存中。
- 线程B到主内存中读取线程A更新后的共享变量
计算机在运行程序时,每条指令都是在CPU中执行的,在执行过程中势必会涉及到数据的读写。我们知道程序运行的数据是存储在主存中,这时就会有一个问题,读写主存中的数据没有CPU中执行指令的速度快,如果任何的交互都需要与主存打交道则会大大影响效率,所以就有了CPU高速缓存。CPU高速缓存为某个CPU独有,只与在该CPU运行的线程有关。
有了CPU高速缓存虽然解决了效率问题,但是它会带来一个新的问题:数据一致性。在程序运行中,会将运行所需要的数据复制一份到CPU高速缓存中,在进行运算时CPU不再也主存打交道,而是直接从高速缓存中读写数据,只有当运行结束后才会将数据刷新到主存中。
举个例子:
i++;
当线程运行这行代码时,首先会从主内存中读取i,然后复制一份到CPU高速缓存中,接着CPU执行+1的操作,再将+1后的数据写在缓存中,最后一步才是刷新到主内存中。在单线程时没有问题,多线程就有问题了。
如下:假如有两个线程A、B都执行这个操作(i++),按照我们正常的逻辑思维主存中的i值应该=3,但事实是这样么?
分析如下:两个线程从主存中读取i的值(1)到各自的高速缓存中,然后线程A执行+1操作并将结果写入高速缓存中,最后写入主存中,此时主存i==2,线程B做同样的操作,主存中的i仍然=2。所以最终结果为2并不是3。这种现象就是缓存一致性问题。
解决缓存一致性方案有两种:
通过在总线加LOCK#锁的方式;
通过缓存一致性协议。
但是方案1存在一个问题,它是采用一种独占的方式来实现的,即总线加LOCK#锁的话,只能有一个CPU能够运行,其他CPU都得阻塞,效率较为低下。
第二种方案,缓存一致性协议(MESI协议)它确保每个缓存中使用的共享变量的副本是一致的。所以JMM就解决这个问题。
volatile实现原理
有volatile修饰的共享变量进行写操作的时候会多出Lock前缀的指令,该指令在多核处理器下会引发两件事情。
- 将当前处理器缓存行数据刷写到系统主内存。
- 这个刷写回主内存的操作会使其他CPU缓存的该共享变量内存地址的数据无效。
这样就保证了多个处理器的缓存是一致的,对应的处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器缓存行设置无效状态,当处理器对这个数据进行修改操作的时候会重新从主内存中把数据读取到缓存里。
使用场景
volatile经常用于两个场景:状态标记、double check
1、状态标记1
2
3
4
5
6
7
8//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是加上volatile就没问题了。如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20volatile boolean flag = false;
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}
volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
2、double check1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}
synchronized底层
上面有写
锁升级的过程
Java SE 1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,在Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率,下文会详细分析。
markword
因为偏向锁,锁住对象时,会写入对象头相应的标识,我们先把对象头(官方叫法为:Mark Word)的图示如下(借用了网友的图片):

偏向锁
HotSpot [1] 的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
上文中黑体字部分,写得太简略,以致于很多初学者,对这个过程有点不明白,这个过程是怎么实现锁的升级、释放的?下面一一分析
- 线程2来竞争锁对象;
- 判断当前对象头是否是偏向锁;
- 判断拥有偏向锁的线程1是否还存在;
- 线程1不存在,直接设置偏向锁标识为0(线程1执行完毕后,不会主动去释放偏向锁);
- 使用cas替换偏向锁线程ID为线程2,锁不升级,仍为偏向锁;
- 线程1仍然存在,暂停线程1;
- 设置锁标志位为00(变为轻量级锁),偏向锁为0;
- 从线程1的空闲monitor record中读取一条,放至线程1的当前monitor record中;
- 更新mark word,将mark word指向线程1中monitor record的指针;
- 继续执行线程1的代码;
- 锁升级为轻量级锁;
- 线程2自旋来获取锁对象;

轻量级锁
(1)轻量级锁加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
(2)轻量级锁解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。下图是两个线程同时争夺锁,导致锁膨胀的流程图。
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于这个状态下,其他线程试图获取锁时,都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
缓存一致性和MESI
缓存一致性协议给缓存行(通常为64字节)定义了个状态:独占(exclusive)、共享(share)、修改(modified)、失效(invalid),用来描述该缓存行是否被多处理器共享、是否修改。所以缓存一致性协议也称MESI协议。
- 独占(exclusive):仅当前处理器拥有该缓存行,并且没有修改过,是最新的值。
- 共享(share):有多个处理器拥有该缓存行,每个处理器都没有修改过缓存,是最新的值。
- 修改(modified):仅当前处理器拥有该缓存行,并且缓存行被修改过了,一定时间内会写回主存,会写成功状态会变为S。
失效(invalid):缓存行被其他处理器修改过,该值不是最新的值,需要读取主存上最新的值。
协议协作如下:一个处于M状态的缓存行,必须时刻监听所有试图读取该缓存行对应的主存地址的操作,如果监听到,则必须在此操作执行前把其缓存行中的数据写回CPU。
- 一个处于S状态的缓存行,必须时刻监听使该缓存行无效或者独享该缓存行的请求,如果监听到,则必须把其缓存行状态设置为I。
- 一个处于E状态的缓存行,必须时刻监听其他试图读取该缓存行对应的主存地址的操作,如果监听到,则必须把其缓存行状态设置为S。
- 当CPU需要读取数据时,如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S,如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
- 当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下会性能开销是相对较大的。在写入完成后,修改其缓存状态为M。

这个图的含义就是当一个core持有一个cacheline的状态为Y时,其它core对应的cacheline应该处于状态X, 比如地址 0x00010000 对应的cacheline在core0上为状态M, 则其它所有的core对应于0x00010000的cacheline都必须为I , 0x00010000 对应的cacheline在core0上为状态S, 则其它所有的core对应于0x00010000的cacheline 可以是S或者I ,
另外MESI协议为了提高性能,引入了Store Buffe和Invalidate Queues,还是有可能会引起缓存不一致,还会再引入内存屏障来确保一致性,可以参考[7]和[12]
存储缓存(Store Buffe)
也就是常说的写缓存,当处理器修改缓存时,把新值放到存储缓存中,处理器就可以去干别的事了,把剩下的事交给存储缓存。
失效队列(Invalidate Queues)
处理失效的缓存也不是简单的,需要读取主存。并且存储缓存也不是无限大的,那么当存储缓存满的时候,处理器还是要等待失效响应的。为了解决上面两个问题,引进了失效队列(invalidate queue)。处理失效的工作如下:
收到失效消息时,放到失效队列中去。
为了不让处理器久等失效响应,收到失效消息需要马上回复失效响应。
为了不频繁阻塞处理器,不会马上读主存以及设置缓存为invlid,合适的时候再一块处理失效队列。
MESI和CAS关系
在x86架构上,CAS被翻译为”lock cmpxchg…”,当两个core同时执行针对同一地址的CAS指令时,其实他们是在试图修改每个core自己持有的Cache line
假设两个core都持有相同地址对应cacheline,且各自cacheline 状态为S, 这时如果要想成功修改,就首先需要把S转为E或者M, 则需要向其它core invalidate 这个地址的cacheline,则两个core都会向ring bus发出 invalidate这个操作, 那么在ringbus上就会根据特定的设计协议仲裁是core0,还是core1能赢得这个invalidate, 胜者完成操作, 失败者需要接受结果, invalidate自己对应的cacheline,再读取胜者修改后的值, 回到起点.
对于我们的CAS操作来说, 其实锁并没有消失,只是转嫁到了ring bus的总线仲裁协议中. 而且大量的多核同时针对一个地址的CAS操作会引起反复的互相invalidate 同一cacheline, 造成pingpong效应, 同样会降低性能(参考[9])。当然如果真的有性能问题,我觉得这可能会在ns级别体现了,一般的应用程序中使用CAS应该不会引起性能问题
指令重排和内存屏障
指令重排
现代CPU的速度越来越快,为了充分的利用CPU,在编译器和CPU执行期,都可能对指令重排。举个例子:1
2
3LDR R1, [R0];//操作1
ADD R2, R1, R1;//操作2
ADD R3, R4, R4;//操作3
上面这段代码,如果操作1如果发生cache miss,则需要等待读取内存外存。看看有没有能优先执行的指令,操作2依赖于操作1,不能被优先执行,操作3不依赖1和2,所以能优先执行操作3。
JVM的JSR-133规范中定义了as-if-serial语义,即compiler, runtime, and hardware三者需要保证在单线程模型下程序不会感知到指令重排的影响。
在并发模型下,重排序还是可能会引发问题,比较经典的就是“单例模式失效”问题(DoubleCheckedLocking):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Singleton {
private static Singleton instance = null;
private Singleton() { }
public static Singleton getInstance() {
if(instance == null) {
synchronzied(Singleton.class) {
if(instance == null) {
instance = new Singleton(); //
}
}
}
return instance;
}
}
上面这段代码,初看没问题,但是在并发模型下,可能会出错,那是因为instance= new Singleton()并非一个原子操作,它实际上下面这三个操作:1
2
3memory =allocate(); //1:分配对象的内存空间
ctorInstance(memory); //2:初始化对象
instance =memory; //3:设置instance指向刚分配的内存地址
上面操作2依赖于操作1,但是操作3并不依赖于操作2,所以JVM是可以针对它们进行指令的优化重排序的,经过重排序后如下:1
2
3memory =allocate(); //1:分配对象的内存空间
instance =memory; //3:instance指向刚分配的内存地址,此时对象还未初始化
ctorInstance(memory); //2:初始化对象
可以看到指令重排之后,instance指向分配好的内存放在了前面,而这段内存的初始化被排在了后面。在多线程场景下,可能A线程执行到了3,B线程发现已经不为空就返回继续执行,就会出错。
在java里面volatile可以防止重排,当然还有另外一个作用即内存可见性,这个知道的人还应该比较普遍,就不说了
内存屏障
硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。内存屏障有两个作用:
1.阻止屏障两侧的指令重排序;
2.强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
在JSR规范中定义了4种内存屏障:
- LoadLoad屏障:(指令Load1; LoadLoad; Load2),在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
- LoadStore屏障:(指令Load1; LoadStore; Store2),在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
- StoreStore屏障:(指令Store1; StoreStore; Store2),在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
StoreLoad屏障:(指令Store1; StoreLoad; Load2),在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能
对于volatile关键字,按照规范会有下面的操作:在每个volatile写入之前,插入一个StoreStore,写入之后,插入一个StoreLoad
- 在每个volatile读取之前,插入LoadLoad,之后插入LoadStore
- 具体到X86来看,其实没那么多指令,只有StoreLoad:
结合上面的【一】和【二】的内容,内存屏障首先阻止了指令的重排,另外也和MESI协议结合,确保了内存的可见性
怎么理解Java 中和 MySQL中的乐观锁、悲观锁?
java
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
乐观锁常见的两种实现方式
乐观锁一般会使用版本号机制或CAS(Compare-and-Swap,即比较并替换)算法实现。
版本号机制
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
举一个简单的例子: 假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
- 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
- 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
- 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
- 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
CAS算法
即 compare and swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。CAS算法涉及到三个操作数
需要读写的内存值 V
进行比较的值 A
拟写入的新值 B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
乐观锁的缺点
ABA 问题是乐观锁一个常见的问题。
- ABA 问题
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 “ABA”问题。
JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
- 循环时间长开销大
自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
- 只能保证一个共享变量的原子操作
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
CAS与synchronized的使用情景
简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)
- 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 “重量级锁” 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 偏向锁 和 轻量级锁 以及其它各种优化之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 Lock-Free 的队列,基本思路是 自旋后阻塞,竞争切换后继续竞争锁,稍微牺牲了公平性,但获得了高吞吐量。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
Mysql
悲观锁(Pessimistic Lock)
悲观锁的特点是先获取锁,再进行业务操作,即“悲观”的认为获取锁是非常有可能失败的,因此要先确保获取锁成功再进行业务操作。通常所说的“一锁二查三更新”即指的是使用悲观锁。通常来讲在数据库上的悲观锁需要数据库本身提供支持,即通过常用的select … for update操作来实现悲观锁。当数据库执行select for update时会获取被select中的数据行的行锁,因此其他并发执行的select for update如果试图选中同一行则会发生排斥(需要等待行锁被释放),因此达到锁的效果。select for update获取的行锁会在当前事务结束时自动释放,因此必须在事务中使用。
这里需要注意的一点是不同的数据库对select for update的实现和支持都是有所区别的,例如oracle支持select for update no wait,表示如果拿不到锁立刻报错,而不是等待,mysql就没有no wait这个选项。另外mysql还有个问题是select for update语句执行中所有扫描过的行都会被锁上,这一点很容易造成问题。因此如果在mysql中用悲观锁务必要确定走了索引,而不是全表扫描。
乐观锁(Optimistic Lock)
乐观锁的特点先进行业务操作,不到万不得已不去拿锁。即“乐观”的认为拿锁多半是会成功的,因此在进行完业务操作需要实际更新数据的最后一步再去拿一下锁就好。
乐观锁在数据库上的实现完全是逻辑的,不需要数据库提供特殊的支持。一般的做法是在需要锁的数据上增加一个版本号,或者时间戳,然后按照如下方式实现:1
2
3
4
5
6
7
81. SELECT data AS old_data, version AS old_version FROM …;
2. 根据获取的数据进行业务操作,得到new_data和new_version
3. UPDATE SET data = new_data, version = new_version WHERE version = old_version
if (updated row > 0) {
// 乐观锁获取成功,操作完成
} else {
// 乐观锁获取失败,回滚并重试
}
乐观锁是否在事务中其实都是无所谓的,其底层机制是这样:在数据库内部update同一行的时候是不允许并发的,即数据库每次执行一条update语句时会获取被update行的写锁,直到这一行被成功更新后才释放。因此在业务操作进行前获取需要锁的数据的当前版本号,然后实际更新数据时再次对比版本号确认与之前获取的相同,并更新版本号,即可确认这之间没有发生并发的修改。如果更新失败即可认为老版本的数据已经被并发修改掉而不存在了,此时认为获取锁失败,需要回滚整个业务操作并可根据需要重试整个过程。
总结
- 乐观锁在不发生取锁失败的情况下开销比悲观锁小,但是一旦发生失败回滚开销则比较大,因此适合用在取锁失败概率比较小的场景,可以提升系统并发性能
- 乐观锁还适用于一些比较特殊的场景,例如在业务操作过程中无法和数据库保持连接等悲观锁无法适用的地方
对线程池的理解,项目中哪个地方使用了,如何使用的,用的Excutor框架中的哪个实现类,为什么用这个
线程池
线程池的作用
线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
为什么要用线程池?
减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。
比较重要的几个类:
| 名称 | 作用 |
|---|---|
| ExecutorService | 真正的线程池接口。 |
| ScheduledExecutorService | 能和Timer/TimerTask类似,解决那些需要任务重复执行的问题。 |
| ThreadPoolExecutor | ExecutorService的默认实现。 |
| ScheduledThreadPoolExecutor | 继承ThreadPoolExecutor的ScheduledExecutorService接口实现,周期性任务调度的类实现。 |
要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,很有可能配置的线程池不是较优的,因此在Executors类里面提供了一些静态工厂,生成一些常用的线程池。
newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
ThreadPoolExecutor详解
ThreadPoolExecutor的完整构造方法的签名是:ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) .
- corePoolSize - 池中所保存的线程数,包括空闲线程。
- maximumPoolSize-池中允许的最大线程数。
- keepAliveTime - 当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
- unit - keepAliveTime 参数的时间单位。
- workQueue - 执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
- threadFactory - 执行程序创建新线程时使用的工厂。
- handler - 由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。
- ThreadPoolExecutor是Executors类的底层实现。
下面介绍一下几个类的源码:
ExecutorService newFixedThreadPool (int nThreads):固定大小线程池。
可以看到,corePoolSize和maximumPoolSize的大小是一样的(实际上,后面会介绍,如果使用无界queue的话maximumPoolSize参数是没有意义的),keepAliveTime和unit的设值表名什么?-就是该实现不想keep alive!最后的BlockingQueue选择了LinkedBlockingQueue,该queue有一个特点,他是无界的。
1 |
|
ExecutorService newSingleThreadExecutor():单线程1
2
3
4
5
6
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
ExecutorService newCachedThreadPool():无界线程池,可以进行自动线程回收
这个实现就有意思了。首先是无界的线程池,所以我们可以发现maximumPoolSize为big big。其次BlockingQueue的选择上使用SynchronousQueue。可能对于该BlockingQueue有些陌生,简单说:该QUEUE中,每个插入操作必须等待另一个线程的对应移除操作。
1 | public static ExecutorService newCachedThreadPool() { |
先从BlockingQueue<Runnable> workQueue这个入参开始说起。在JDK中,其实已经说得很清楚了,一共有三种类型的queue。
所有BlockingQueue 都可用于传输和保持提交的任务。可以使用此队列与池大小进行交互:
如果运行的线程少于 corePoolSize,则 Executor始终首选添加新的线程,而不进行排队。(如果当前运行的线程小于corePoolSize,则任务根本不会存放,添加到queue中,而是直接抄家伙(thread)开始运行)
如果运行的线程等于或多于 corePoolSize,则 Executor始终首选将请求加入队列,而不添加新的线程。
如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。
queue上的三种类型。
排队有三种通用策略:
直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙时新任务在队列中等待。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web页服务器中。这种排队可用于处理瞬态突发请求,当命令以超过队列所能处理的平均数连续到达时,此策略允许无界线程具有增长的可能性。
有界队列。当使用有限的 maximumPoolSizes时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低 CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
BlockingQueue的选择
例子一:使用直接提交策略,也即SynchronousQueue。
首先SynchronousQueue是无界的,也就是说他存数任务的能力是没有限制的,但是由于该Queue本身的特性,在某次添加元素后必须等待其他线程取走后才能继续添加。在这里不是核心线程便是新创建的线程,但是我们试想一样下,下面的场景。
我们使用一下参数构造ThreadPoolExecutor:
1 | new ThreadPoolExecutor( 2, 3, 30, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),new RecorderThreadFactory("CookieRecorderPool"),new ThreadPoolExecutor.CallerRunsPolicy()); |
1 | new ThreadPoolExecutor(2, 3, 30, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),new RecorderThreadFactory("CookieRecorderPool"),new ThreadPoolExecutor.CallerRunsPolicy()); |
当核心线程已经有2个正在运行.
- 此时继续来了一个任务(A),根据前面介绍的“如果运行的线程等于或多于 corePoolSize,则 Executor始终首选将请求加入队列,而不添加新的线程。”,所以A被添加到queue中。
- 又来了一个任务(B),且核心2个线程还没有忙完,OK,接下来首先尝试1中描述,但是由于使用的SynchronousQueue,所以一定无法加入进去。
- 此时便满足了上面提到的“如果无法将请求加入队列,则创建新的线程,除非创建此线程超出maximumPoolSize,在这种情况下,任务将被拒绝。”,所以必然会新建一个线程来运行这个任务。
- 暂时还可以,但是如果这三个任务都还没完成,连续来了两个任务,第一个添加入queue中,后一个呢?queue中无法插入,而线程数达到了maximumPoolSize,所以只好执行异常策略了。
所以在使用SynchronousQueue通常要求maximumPoolSize是无界的,这样就可以避免上述情况发生(如果希望限制就直接使用有界队列)。对于使用SynchronousQueue的作用jdk中写的很清楚:此策略可以避免在处理可能具有内部依赖性的请求集时出现锁。
什么意思?如果你的任务A1,A2有内部关联,A1需要先运行,那么先提交A1,再提交A2,当使用SynchronousQueue我们可以保证,A1必定先被执行,在A1么有被执行前,A2不可能添加入queue中。
例子二:使用无界队列策略,即LinkedBlockingQueue
这个就拿newFixedThreadPool来说,根据前文提到的规则:
如果运行的线程少于 corePoolSize,则 Executor 始终首选添加新的线程,而不进行排队。那么当任务继续增加,会发生什么呢?
如果运行的线程等于或多于 corePoolSize,则 Executor 始终首选将请求加入队列,而不添加新的线程。OK,此时任务变加入队列之中了,那什么时候才会添加新线程呢?
如果无法将请求加入队列,则创建新的线程,除非创建此线程超出 maximumPoolSize,在这种情况下,任务将被拒绝。这里就很有意思了,可能会出现无法加入队列吗?不像SynchronousQueue那样有其自身的特点,对于无界队列来说,总是可以加入的(资源耗尽,当然另当别论)。换句说,永远也不会触发产生新的线程!corePoolSize大小的线程数会一直运行,忙完当前的,就从队列中拿任务开始运行。所以要防止任务疯长,比如任务运行的实行比较长,而添加任务的速度远远超过处理任务的时间,而且还不断增加,不一会儿就爆了。
**例子三:有界队列,使用ArrayBlockingQueue。
这个是最为复杂的使用,所以JDK不推荐使用也有些道理。与上面的相比,最大的特点便是可以防止资源耗尽的情况发生。
举例来说,请看如下构造方法:1
new ThreadPoolExecutor(2, 4, 30, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(2),new RecorderThreadFactory("CookieRecorderPool"), new ThreadPoolExecutor.CallerRunsPolicy());
1 | new ThreadPoolExecutor(2, 4, 30, TimeUnit.SECONDS,new ArrayBlockingQueue<Runnable>(2),new RecorderThreadFactory("CookieRecorderPool"),new ThreadPoolExecutor.CallerRunsPolicy()); |
假设,所有的任务都永远无法执行完。
对于首先来的A,B来说直接运行,接下来,如果来了C,D,他们会被放到queue中,如果接下来再来E,F,则增加线程运行E,F。但是如果再来任务,队列无法再接受了,线程数也到达最大的限制了,所以就会使用拒绝策略来处理。
keepAliveTime
jdk中的解释是:当线程数大于核心时,此为终止前多余的空闲线程等待新任务的最长时间。
有点拗口,其实这个不难理解,在使用了“池”的应用中,大多都有类似的参数需要配置。比如数据库连接池,DBCP中的maxIdle,minIdle参数。
什么意思?接着上面的解释,后来向老板派来的工人始终是“借来的”,俗话说“有借就有还”,但这里的问题就是什么时候还了,如果借来的工人刚完成一个任务就还回去,后来发现任务还有,那岂不是又要去借?这一来一往,老板肯定头也大死了。
合理的策略:既然借了,那就多借一会儿。直到“某一段”时间后,发现再也用不到这些工人时,便可以还回去了。这里的某一段时间便是keepAliveTime的含义,TimeUnit为keepAliveTime值的度量。
RejectedExecutionHandler
另一种情况便是,即使向老板借了工人,但是任务还是继续过来,还是忙不过来,这时整个队伍只好拒绝接受了。
RejectedExecutionHandler接口提供了对于拒绝任务的处理的自定方法的机会。在ThreadPoolExecutor中已经默认包含了4中策略,因为源码非常简单,这里直接贴出来。
CallerRunsPolicy:线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。1
2
3
4
5
6
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
这个策略显然不想放弃执行任务。但是由于池中已经没有任何资源了,那么就直接使用调用该execute的线程本身来执行。
AbortPolicy:处理程序遭到拒绝将抛出运行时RejectedExecutionException1
2
3
4
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException();
}
这种策略直接抛出异常,丢弃任务。
DiscardPolicy:不能执行的任务将被删除1
2
3
4
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
这种策略和AbortPolicy几乎一样,也是丢弃任务,只不过他不抛出异常。
DiscardOldestPolicy:如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)1
2
3
4
5
6
7
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
该策略就稍微复杂一些,在pool没有关闭的前提下首先丢掉缓存在队列中的最早的任务,然后重新尝试运行该任务。这个策略需要适当小心。
设想:如果其他线程都还在运行,那么新来任务踢掉旧任务,缓存在queue中,再来一个任务又会踢掉queue中最老任务。
总结
keepAliveTime和maximumPoolSize及BlockingQueue的类型均有关系。如果BlockingQueue是无界的,那么永远不会触发maximumPoolSize,自然keepAliveTime也就没有了意义。
反之,如果核心数较小,有界BlockingQueue数值又较小,同时keepAliveTime又设的很小,如果任务频繁,那么系统就会频繁的申请回收线程。
怎么理解线程安全?
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
安全性:
比如一个 ArrayList 类,在添加一个元素的时候,它可能会有两步来完成:1. 在 Items[Size] 的位置存放此元素;2. 增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;
而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增加 Size 的值。
那好,我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。
一个final修饰的属性,定义的时候没有初始化,在无参构造函数中初始化,可以吗,为什么
static
static修饰一个属性字段,那么这个属性字段将成为类本身的资源,public修饰为共有的,可以在类的外部通过test.a来访问此属性;在类内部任何地方可以使用。如果被修饰为private私有,那么只能在类内部使用。
如果属性被修饰为static静态类资源,那么这个字段永远只有一个,也就是说不管你new test()多少个类的对象,操作的永远都只是属于类的那一块内存资源。
final
final 用于声明属性、方法和类,分别表示属性一旦被分配内存空间就必须初始化并且以后不可变;方法一旦定义必须有实现代码并且子类里不可被覆盖;类一旦定义不能被定义为抽象类或是接口,因为不可被继承。
被final修饰而没有被static修饰的类的属性变量只能在两种情况下初始化:
在它被定义的时候
1
2
3
4
5
6
7
public class Test{
public final int a=0;
private Test(){
}
}在构造函数里初始化
1
2
3
4
5
6
7
public class Test{
public final int a;
private Test(){
a=0;
}
}
同时被final和static修饰的类的属性变量只能在两种情况下初始化
在它被定义的时候
1
2
3
4
5
6
7
public class Test{
public static final int a=0;
private Test(){
}
}在类的静态块里初始化
1
2
3
4
5
6public class Test{
public static final int a;
static{
a=0;
}
}
当类的属性被同时被修饰为static和final的时候,他属于类的资源,那么就是类在被加载进内存的时候(也就是应用程序启动的时候)就要为属性分配内存,所以此时属性已经存在,它又被final修饰,所以必须在属性定义了以后就给其初始化值。而构造函数是在当类被实例化的时候才会执行,所以不能用构造函数。而static块是类被加载的时候执行,且只执行这一次,所以在static块中可以执行初始化。
HashMap,concurrentHashMap底实现序列化层实现
实现了Serializable接口
Java中 Serializable 是 标示一个类是可以被 JDK 序列化和反序列化的,他只是一个接口并没有任何操作。
序列化,本质就是将内存里面的 Java 对象写入到流里面,还可以将流里面的Java序列化数据反序列化还原到实例对象。
当然,序列化的方法很多,常见的就是 JDK 序列化、JSON 序列化、还有 protobuffer 等等。
每一种框架,序列化和反序列化都是有一个统一的数据格式规范和算法。
什么是红黑树,什么是B-Tree,为什么HashMap中用红黑树不用其他树?
树的概念前面有。
那么很多人就有疑问为什么是使用红黑树而不是AVL树,AVL树是完全平衡二叉树阿?
最主要的一点是:
在CurrentHashMap中是加锁了的,实际上是读写锁,如果写冲突就会等待,
如果插入时间过长必然等待时间更长,而红黑树相对AVL树他的插入更快!
问题:为什么不使用AVL树而使用红黑树?
红黑树和AVL树都是最常用的平衡二叉搜索树,它们的查找、删除、修改都是O(lgn) time
AVL树和红黑树有几点比较和区别:
(1)AVL树是更加严格的平衡,因此可以提供更快的查找速度,一般读取查找密集型任务,适用AVL树。
(2)红黑树更适合于插入修改密集型任务。
(3)通常,AVL树的旋转比红黑树的旋转更加难以平衡和调试。
总结:
(1)AVL以及红黑树是高度平衡的树数据结构。它们非常相似,真正的区别在于在任何添加/删除操作时完成的旋转操作次数。
(2)两种实现都缩放为a O(lg N),其中N是叶子的数量,但实际上AVL树在查找密集型任务上更快:利用更好的平衡,树遍历平均更短。另一方面,插入和删除方面,AVL树速度较慢:需要更高的旋转次数才能在修改时正确地重新平衡数据结构。
(3)在AVL树中,从根到任何叶子的最短路径和最长路径之间的差异最多为1。在红黑树中,差异可以是2倍。
(4)两个都给O(log n)查找,但平衡AVL树可能需要O(log n)旋转,而红黑树将需要最多两次旋转使其达到平衡(尽管可能需要检查O(log n)节点以确定旋转的位置)。旋转本身是O(1)操作,因为你只是移动指针。
计算密集型/IO密集型任务分别如何设置线程池的核心线程数和最大线程数,为什么这么设置?
任务类型举例:
CPU密集型:
例如,一般我们系统的静态资源,比如js,css等,会存在一个版本号,如 main.js?v0,每当用户访问这个资源的时候,会发送一个比对请求到服务端,比对本地静态文件版本和服务端的文件版本是否一致,不一致则更新.这种任务一般不占用大量IO,所以后台服务器可以快速处理,压力落在CPU上.
I/O密集型:
比方说近期我们做的万科CRM系统,常有大数据量的查询和批量插入操作,此时的压力主要在I/O上.
线程数与任务类型的关系:
与CPU密集型的关系:
一般情况下,CPU核心数 == 最大同时执行线程数.在这种情况下(设CPU核心数为n),大量客户端会发送请求到服务器,但是服务器最多只能同时执行n个线程.
设线程池工作队列长度为m,且m>>n,则此时会导致CPU频繁切换线程来执行(如果CPU使用的是FCFS,则不会频繁切换,如使用的是其他CPU调度算法,如时间片轮转法,最短时间优先,则可能会导致频繁的线程切换).
所以这种情况下,无需设置过大的线程池工作队列,(工作队列长度 = CPU核心数 || CPU核心数+1) 即可.
与I/O密集型的关系:
1个线程对应1个方法栈,线程的生命周期与方法栈相同.
比如某个线程的方法栈对应的入站顺序为:controller()->service()->DAO(),由于DAO长时间的I/O操作,导致该线程一直处于工作队列,但它又不占用CPU,则此时有1个CPU是处于空闲状态的.
所以,这种情况下,应该加大线程池工作队列的长度(如果CPU调度算法使用的是FCFS,则无法切换),尽量不让CPU空闲下来,提高CPU利用率.
画一下Java 线程几个状态及状态之间互相转换的图?

在Java中线程的状态一共被分成6种:
初始态:NEW
创建一个Thread对象,但还未调用start()启动线程时,线程处于初始态。
运行态:RUNNABLE
在Java中,运行态包括就绪态 和 运行态。
- 就绪态
- 该状态下的线程已经获得执行所需的所有资源,只要CPU分配执行权就能运行。
- 所有就绪态的线程存放在就绪队列中。
- 运行态
- 获得CPU执行权,正在执行的线程。
- 由于一个CPU同一时刻只能执行一条线程,因此每个CPU每个时刻只有一条运行态的线程。
阻塞态
- 当一条正在执行的线程请求某一资源失败时,就会进入阻塞态。
- 而在Java中,阻塞态专指请求锁失败时进入的状态。
- 由一个阻塞队列存放所有阻塞态的线程。
- 处于阻塞态的线程会不断请求资源,一旦请求成功,就会进入就绪队列,等待执行。
PS:锁、IO、Socket等都资源。
等待态
- 当前线程中调用wait、join、park函数时,当前线程就会进入等待态。
- 也有一个等待队列存放所有等待态的线程。
- 线程处于等待态表示它需要等待其他线程的指示才能继续运行。
- 进入等待态的线程会释放CPU执行权,并释放资源(如:锁)
终止态
线程执行结束后的状态。
注意
- wait()方法会释放CPU执行权 和 占有的锁。
- sleep(long)方法仅释放CPU使用权,锁仍然占用;线程被放入超时等待队列,与yield相比,它会使线程较长时间得不到运行。
- yield()方法仅释放CPU执行权,锁仍然占用,线程会被放入就绪队列,会在短时间内再次执行。
- wait和notify必须配套使用,即必须使用同一把锁调用;
- wait和notify必须放在一个同步块中
- 调用wait和notify的对象必须是他们所处同步块的锁对象。
对线程池的理解,在项目中如何使用的,多个线程之间如何共享数据,多个进程之间如何共享数据?
首先想到的是将共享数据设置为全局变量,并且用static修饰,但是static修饰的变量是类变量,生命周期太长了,占用内存。
方法一:多个线程对共享数据的操作是相同的,那么创建
一个Runnable的子类对象,将这个对象作为参数传递给Thread的构造方法,此时因为多个线程操作的是同一个Runnable的子类对象,所以他们操作的是同一个共享数据。比如:买票系统,所以的线程的操作都是对票数减一的操作。
方法二:多个线程对共享数据的操作是不同的,将共享数据和操作共享数据的方法放在同一对象中,将这个对象作为参数传递给Runnable的子类,在子类中用该对象的方法对共享数据进行操作。如:生产者消费者。
方法三:多个线程对共享数据的操作是不同的, 用内部类的方式去实现,创建Runnable的子类作为内部类,将共享对象作为全局变量,在Runnable的子类中对共享数据进行操作。
方法四:ThreadLocal实现线程范围内数据的共享
设计模式
怎么理解命令模式和观察者模式,手写一个观察者模式或者命令模式的代码,策略模式也行
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
- 意图:将一个请求封装成一个对象,从而使您可以用不同的请求对客户进行参数化。
- 主要解决:在软件系统中,行为请求者与行为实现者通常是一种紧耦合的关系,但某些场合,比如需要对行为进行记录、撤销或重做、事务等处理时,这种无法抵御变化的紧耦合的设计就不太合适。
- 何时使用:在某些场合,比如要对行为进行”记录、撤销/重做、事务”等处理,这种无法抵御变化的紧耦合是不合适的。在这种情况下,如何将”行为请求者”与”行为实现者”解耦?将一组行为抽象为对象,可以实现二者之间的松耦合。
- 如何解决:通过调用者调用接受者执行命令,顺序:调用者→接受者→命令。
- 应用实例:struts 1 中的 action 核心控制器 ActionServlet 只有一个,相当于 Invoker,而模型层的类会随着不同的应用有不同的模型类,相当于具体的 Command。
- 优点: 1、降低了系统耦合度。 2、新的命令可以很容易添加到系统中去。
- 缺点:使用命令模式可能会导致某些系统有过多的具体命令类。
- 使用场景:认为是命令的地方都可以使用命令模式,比如: 1、GUI 中每一个按钮都是一条命令。 2、模拟 CMD。
- 注意事项:系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作,也可以考虑使用命令模式,见命令模式的扩展。
- 我们首先创建作为命令的接口 Order,然后创建作为请求的 Stock 类。实体命令类 BuyStock 和 SellStock,实现了 Order 接口,将执行实际的命令处理。创建作为调用对象的类 Broker,它接受订单并能下订单。Broker 对象使用命令模式,基于命令的类型确定哪个对象执行哪个命令。CommandPatternDemo,我们的演示类使用 Broker 类来演示命令模式。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78public interface Order {
void execute();
}
public class Stock {
private String name = "ABC";
private int quantity = 10;
public void buy(){
System.out.println("Stock [ Name: "+name+",
Quantity: " + quantity +" ] bought");
}
public void sell(){
System.out.println("Stock [ Name: "+name+",
Quantity: " + quantity +" ] sold");
}
}
public class BuyStock implements Order {
private Stock abcStock;
public BuyStock(Stock abcStock){
this.abcStock = abcStock;
}
public void execute() {
abcStock.buy();
}
}
public class SellStock implements Order {
private Stock abcStock;
public SellStock(Stock abcStock){
this.abcStock = abcStock;
}
public void execute() {
abcStock.sell();
}
}
import java.util.ArrayList;
import java.util.List;
public class Broker {
private List<Order> orderList = new ArrayList<Order>();
public void takeOrder(Order order){
orderList.add(order);
}
public void placeOrders(){
for (Order order : orderList) {
order.execute();
}
orderList.clear();
}
}
public class CommandPatternDemo {
public static void main(String[] args) {
Stock abcStock = new Stock();
BuyStock buyStockOrder = new BuyStock(abcStock);
SellStock sellStockOrder = new SellStock(abcStock);
Broker broker = new Broker();
broker.takeOrder(buyStockOrder);
broker.takeOrder(sellStockOrder);
broker.placeOrders();
}
}
Stock [ Name: ABC, Quantity: 10 ] bought
Stock [ Name: ABC, Quantity: 10 ] sold
观察者模式,当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知它的依赖对象。观察者模式属于行为型模式。
- 意图:定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。
- 主要解决:一个对象状态改变给其他对象通知的问题,而且要考虑到易用和低耦合,保证高度的协作。
- 何时使用:一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都将得到通知,进行广播通知。
- 如何解决:使用面向对象技术,可以将这种依赖关系弱化。
- 关键代码:在抽象类里有一个 ArrayList 存放观察者们。
- 应用实例:1、拍卖的时候,拍卖师观察最高标价,然后通知给其他竞价者竞价。2、西游记里面悟空请求菩萨降服红孩儿,菩萨洒了一地水招来一个老乌龟,这个乌龟就是观察者,他观察菩萨洒水这个动作。
- 优点: 1、观察者和被观察者是抽象耦合的。 2、建立一套触发机制。
- 缺点:1、如果一个被观察者对象有很多的直接和间接的观察者的话,将所有的观察者都通知到会花费很多时间。 2、如果在观察者和观察目标之间有循环依赖的话,观察目标会触发它们之间进行循环调用,可能导致系统崩溃。 3、观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
- 使用场景:1、一个抽象模型有两个方面,其中一个方面依赖于另一个方面。将这些方面封装在独立的对象中使它们可以各自独立地改变和复用。2、一个对象的改变将导致其他一个或多个对象也发生改变,而不知道具体有多少对象将发生改变,可以降低对象之间的耦合度。3、一个对象必须通知其他对象,而并不知道这些对象是谁。4、需要在系统中创建一个触发链,A对象的行为将影响B对象,B对象的行为将影响C对象……,可以使用观察者模式创建一种链式触发机制。
- 实现:观察者模式使用三个类 Subject、Observer 和 Client。Subject 对象带有绑定观察者到 Client 对象和从 Client 对象解绑观察者的方法。我们创建 Subject 类、Observer 抽象类和扩展了抽象类 Observer 的实体类。ObserverPatternDemo,我们的演示类使用 Subject 和实体类对象来演示观察者模式。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90import java.util.ArrayList;
import java.util.List;
public class Subject {
private List<Observer> observers
= new ArrayList<Observer>();
private int state;
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
notifyAllObservers();
}
public void attach(Observer observer){
observers.add(observer);
}
public void notifyAllObservers(){
for (Observer observer : observers) {
observer.update();
}
}
}
public abstract class Observer {
protected Subject subject;
public abstract void update();
}
public class BinaryObserver extends Observer{
public BinaryObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
public void update() {
System.out.println( "Binary String: "
+ Integer.toBinaryString( subject.getState() ) );
}
}
public class OctalObserver extends Observer{
public OctalObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
public void update() {
System.out.println( "Octal String: "
+ Integer.toOctalString( subject.getState() ) );
}
}
public class HexaObserver extends Observer{
public HexaObserver(Subject subject){
this.subject = subject;
this.subject.attach(this);
}
public void update() {
System.out.println( "Hex String: "
+ Integer.toHexString( subject.getState() ).toUpperCase() );
}
}
public class ObserverPatternDemo {
public static void main(String[] args) {
Subject subject = new Subject();
new HexaObserver(subject);
new OctalObserver(subject);
new BinaryObserver(subject);
System.out.println("First state change: 15");
subject.setState(15);
System.out.println("Second state change: 10");
subject.setState(10);
}
}
策略模式:在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
- 意图:定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
- 主要解决:在有多种算法相似的情况下,使用 if…else 所带来的复杂和难以维护。
- 何时使用:一个系统有许多许多类,而区分它们的只是他们直接的行为。
- 如何解决:将这些算法封装成一个一个的类,任意地替换。
- 应用实例:1、诸葛亮的锦囊妙计,每一个锦囊就是一个策略。 2、旅行的出游方式,选择骑自行车、坐汽车,每一种旅行方式都是一个策略。 3、JAVA AWT中的LayoutManager。
- 优点: 1、算法可以自由切换。2、避免使用多重条件判断。3、扩展性良好。
- 缺点:1、策略类会增多。2、所有策略类都需要对外暴露。
- 使用场景:1、如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么使用策略模式可以动态地让一个对象在许多行为中选择一种行为。2、一个系统需要动态地在几种算法中选择一种。3、如果一个对象有很多的行为,如果不用恰当的模式,这些行为就只好使用多重的条件选择语句来实现。
- 注意事项:如果一个系统的策略多于四个,就需要考虑使用混合模式,解决策略类膨胀的问题。
- 实现:我们将创建一个定义活动的 Strategy 接口和实现了 Strategy 接口的实体策略类。Context 是一个使用了某种策略的类。StrategyPatternDemo,我们的演示类使用 Context 和策略对象来演示 Context 在它所配置或使用的策略改变时的行为变化。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public interface Strategy {
public int doOperation(int num1, int num2);
}
public class OperationAdd implements Strategy{
public int doOperation(int num1, int num2) {
return num1 + num2;
}
}
public class OperationSubstract implements Strategy{
public int doOperation(int num1, int num2) {
return num1 - num2;
}
}
public class OperationMultiply implements Strategy{
public int doOperation(int num1, int num2) {
return num1 * num2;
}
}
public class Context {
private Strategy strategy;
public Context(Strategy strategy){
this.strategy = strategy;
}
public int executeStrategy(int num1, int num2){
return strategy.doOperation(num1, num2);
}
}
public class StrategyPatternDemo {
public static void main(String[] args) {
Context context = new Context(new OperationAdd());
System.out.println("10 + 5 = " + context.executeStrategy(10, 5));
context = new Context(new OperationSubstract());
System.out.println("10 - 5 = " + context.executeStrategy(10, 5));
context = new Context(new OperationMultiply());
System.out.println("10 * 5 = " + context.executeStrategy(10, 5));
}
}
设计模式在项目中哪个地方用到了,怎么使用的,能不能画一个你熟悉的设计模式的UML图,手写单例模式,手写静态内部类实现的单例模式。
1
2
3
4
5
6
7
8
9
10
11
12
public class Singleton {
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
private Singleton (){}
public static final Singleton getInstance() {
return SingletonHolder.INSTANCE;
}
}
掌握哪些设计模式,常用哪些,项目中如何使用的,为什么用这个,不用那个?手写一个线程安全的单例模式
- 设计模式:工厂模式、抽象工厂模式、单例模式、建造者模式、原型模式、适配器模式、桥接模式、过滤器模式、组合模式、装饰器模式、外观模式、享元模式、代理模式、责任链模式、命令模式、解释器模式、迭代器模式、中介者模式、备忘录模式、观察者模式、状态模式、空对象模式、策略模式、模板模式、访问者模式、MVC模式、业务代表模式、组合实体模式、数据访问对象模式、前端控制器模式、拦截过滤器模式、服务定位器模式、传输对象模式。
- 线程安全的单例模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Singleton {
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}